

The world of Artificial Intelligence is evolving at breakneck speed, blink, and you will miss the next advance. With model sizes getting larger and larger, researchers and developers are constantly seeking ways to improve the efficiency and performance of AI models. One of the easiest ways to achieve this is using multiple Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs, more on this in the next installment) for AI training and inferencing.
The world of Artificial Intelligence is evolving at breakneck speed, blink, and you will miss the next advance. With model sizes getting larger and larger, researchers and developers are constantly seeking ways to improve the efficiency and performance of AI models. One of the easiest ways to achieve this is using multiple Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs, more on this in the next installment) for AI training and inferencing.
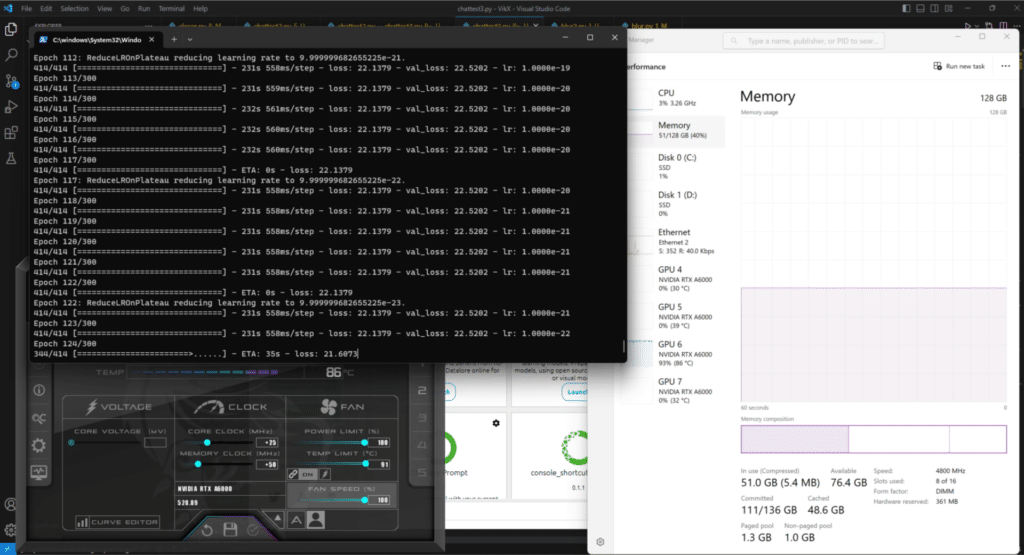
DNN Training on the HP z8 G5 Fury
Building on our last installment of AI In the lab, we took a deep dive and practical hands-on look into the benefits of transitioning from using a single GPU to employing two, and eventually four, of these powerful cards in our HP Z8 G5 Fury workstation, with a specific focus on PyTorch model parallelism.
The Power of Model Parallelism
Before we dive into the specifics, it’s essential to understand the concept of parallelism. In the context of AI, parallelism refers to the process of running multiple computations simultaneously. This is particularly beneficial in AI training and inferencing, where large amounts of data need to be processed. PyTorch, an open-source machine learning library that we employ in the lab, offers model parallelism, which allows for the distribution of an AI model across multiple GPUs. This leads to faster training times, more efficient inferencing, and the ability to run larger, more complex models.
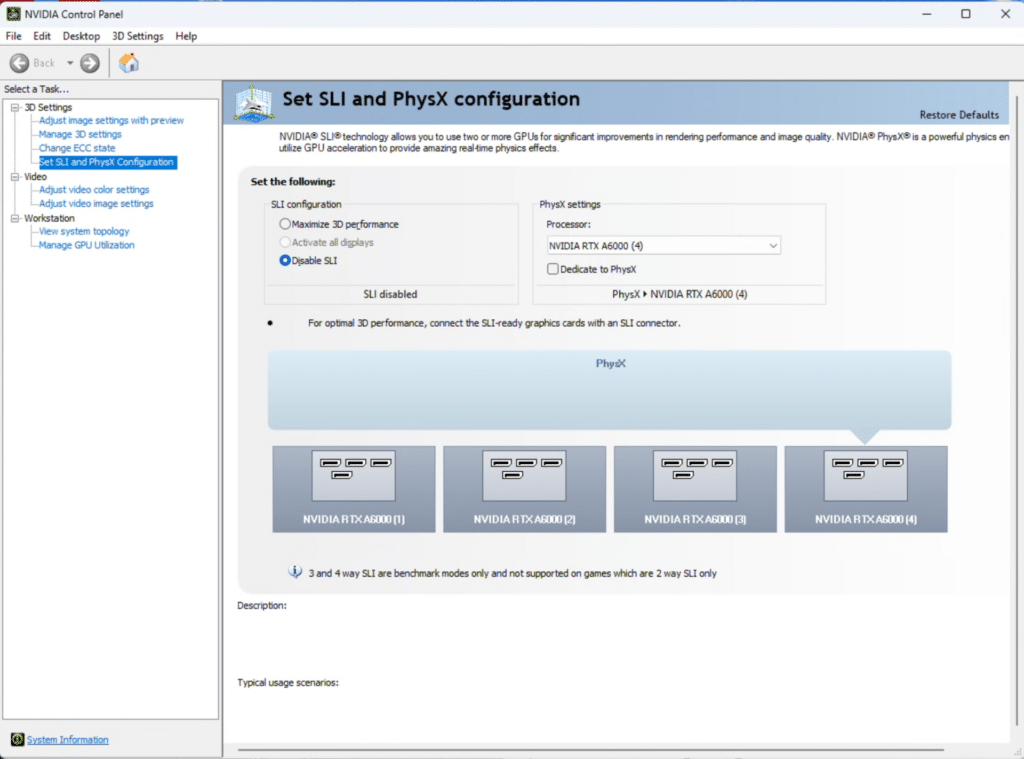
Ensuring SLI is disabled is critical
Benefits of Scaling Up
Single GPU
Starting with a single GPU, this setup provides a solid foundation for AI training and inferencing. Running a single modern (or even a few generations old) GPU in a workstation for development is more than sufficient for the POC stage. It’s capable of handling a reasonable amount of data and can deliver satisfactory results for smaller AI models. However, as the complexity and size of the models increase, a single GPU could quickly struggle to keep up, leading to longer training times and slower inferencing.
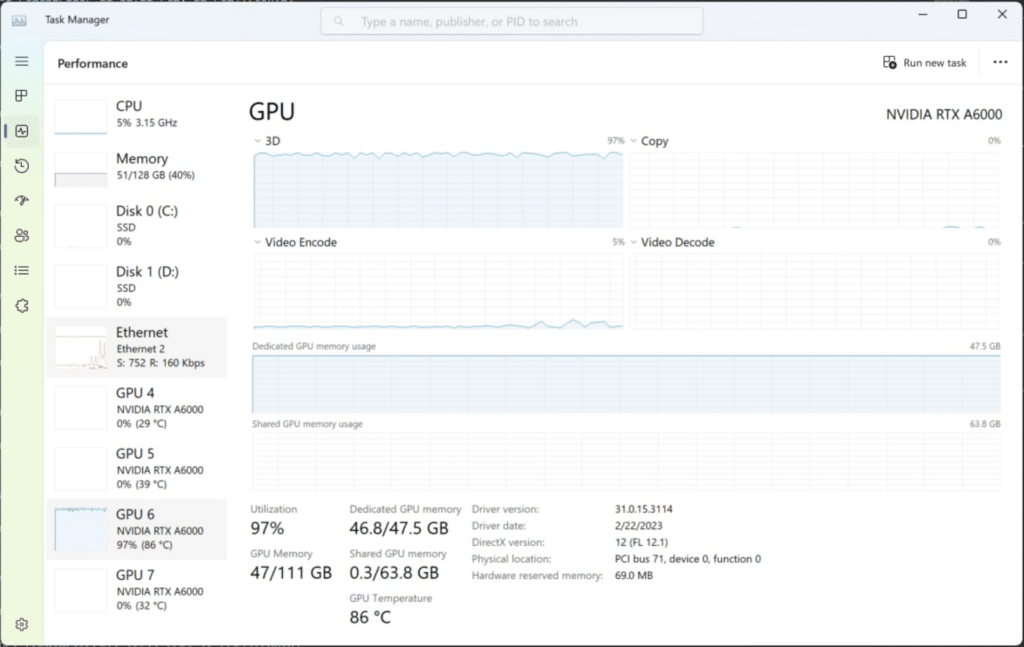
Single GPU Utilization
Two GPUs
Switching to a pair of GPUs can notably amp up the performance of AI models. Think about it: twice the processing power can dramatically cut down training times, paving the way for quicker iterations and a swift journey to results.
The inference stage also benefits, growing more efficient and capable of processing larger data batches simultaneously. In such an environment, PyTorch’s model parallelism comes into play. It effectively distributes the workload between the two units, maximizing their use. It’s a smart way of ensuring each piece of hardware carries its weight to achieve a highly productive AI operation.

3x the fun, NVIDIA A6000
Four GPUs
Scaling up to four GPUs takes the benefits of multi-GPU utilization to another level. With quadruple the processing power, AI models can be trained and inferred at unprecedented speeds. This setup is particularly beneficial for large, complex models that require substantial computational resources. PyTorch’s model parallelism can distribute the model across all four units, ensuring optimal utilization and performance.
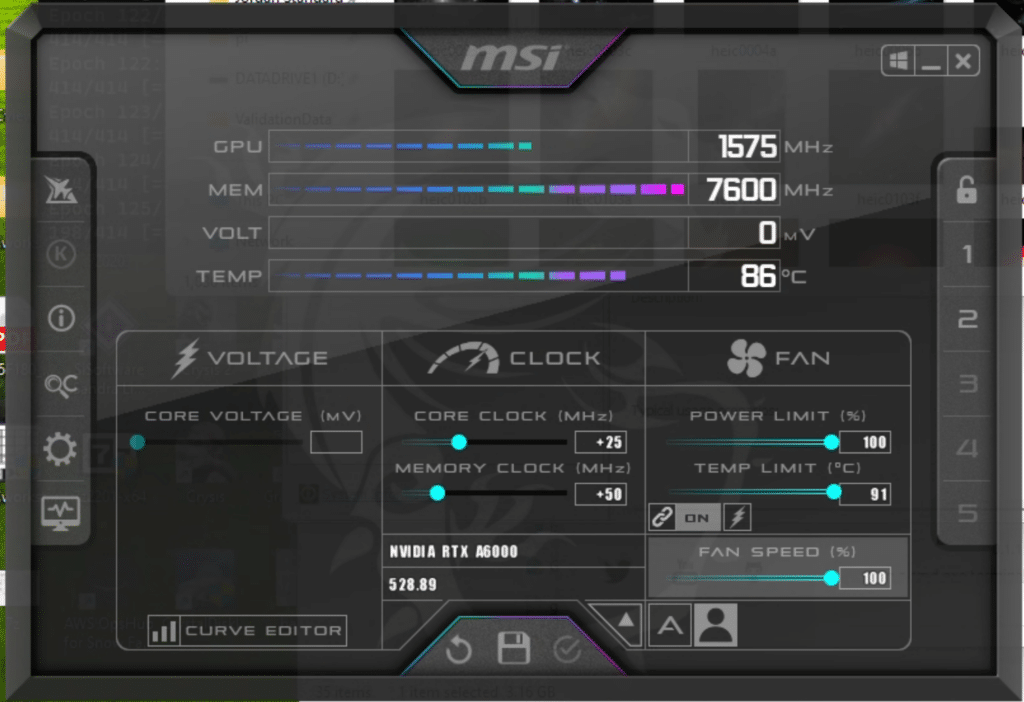
In a workstation, applying manual fan and clock values can yield training performance increases too.
Implementation In The Lab
Progressing from a solo unit to a duo and eventually to a quartet of GPUs for AI training and inferencing can unlock considerable advantages. Thanks to PyTorch’s model parallelism, these benefits can be optimally harnessed, yielding quicker and more efficient AI models.
Trial and error, patience is key with AI/ML/DL Training.
As our thirst for more intricate and competent AI swells, the adoption of multiple GPUs will undoubtedly grow in significance. In the next article, we will showcase the complexity improvements as you add more processing power and distribute across systems.
Note: This article is based on the current state of AI and PyTorch as of June 2023. For the most up-to-date information, make sure to check our most recent AI articles.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed