
While there’s a significant amount of hype around dense GPU servers for AI, and rightfully so, the reality is that most AI training projects start on workstations. Although we can now jam up to four NVIDIA A6000 Ada GPUs into a single workstation, what’s more challenging is getting robust storage in these AI boxes. We thought about this issue and came up with a plan to best supply a few AI workstations with high-speed storage. We worked with Supermicro and KIOXIA to fill up a server with 24 7.68TB XD7P SSDs to create an amazingly capable 1U storage server with an inferencing trick up its sleeve.
While there’s a significant amount of hype around dense GPU servers for AI, and rightfully so, the reality is that most AI training projects start on workstations. Although we can now jam up to four NVIDIA A6000 Ada GPUs into a single workstation, what’s more challenging is getting robust storage in these AI boxes. We thought about this issue and came up with a plan to best supply a few AI workstations with high-speed storage. We worked with Supermicro and KIOXIA to fill up a server with 24 7.68TB XD7P Series Data Center NVMe SSDs to create an amazingly capable 1U storage server with an inferencing trick up its sleeve.

We know what you’re thinking: How do you intend to connect the dots between a server platform stuffed with E1.S SSDs, workstations training AI models, and inferencing on the same storage server? Allow a little latitude to explain.
AI Workstations Don’t Need to Be Under a Desk
With a few exceptions, high-power AI workstations with expensive GPUs probably shouldn’t be distributed out to the edge or arguably even within an office building. The problems are many. Primarily, these endpoints are at high risk of security threats and data leakage, and importantly, they suffer from under-utilization. Most AI professionals cannot access the vast amount of data needed to train their models due to inadequate LAN configurations.
If, on the other hand, we were to put these powerful workstations in the data center, we now gain several benefits. First, physical security is resolved, and remote access concerns can be mitigated with thin clients or access that only pushes pixels rather than data over the wire. In this scenario, data resides on the server rather than the workstation. Secondly, these systems in the data center are faster, if not easier, to back up. Third, with smart provisioning, we can increase utilization across the company by sharing these systems with a distributed AI workforce. Lastly, being in the data center gives us access to the most precious AI asset: data.

We provisioned a trio of Lenovo workstations we had in the lab for this work. Each is configured a little differently, leveraging both AMD and NVIDIA GPUs, providing flexibility as some models may do better on different accelerators. Each system has an NVIDIA ConnectX-6 100GbE card installed, which is fundamental to ensuring these systems have fast access to the storage. Each system then connects to a Dell Z9100 100GbE switch, which the storage service is also attached to.
| Part | Workstation 1 | Workstation 2 | Workstation 3 |
| Model | Lenovo P620 | Lenovo P620 | Lenovo P5 |
| CPU | AMD Ryzen Threadripper PRO 5995WX | AMD Ryzen Threadripper PRO 3995WX | Intel Xeon w7-2495X |
| Memory | 128GB DDR4 3200 | 32GB DDR4 3200 | 32GB DDR5 4800Mhz |
| GPU | AMD Radeon PRO W7900 | NVIDIA RTX A6000 | NVIDIA RTX A4500 |
Fast AI Storage with KIOXIA XD7P Series SSDs
With the AI workstation testbed sorted, we turn to the storage server. In this case, we’re using a Supermicro Storage SuperServer SSG-121E-NES24R. This 1U server has dual Intel Xeon Platinum 8450H processors with 28 cores and 56 threads with a base frequency of 2.00 GHz. The 8450H processors can reach a maximum turbo frequency of 3.50 GHz while featuring a cache of 75MB and a TDP of 250W. The 512GB of DDR5 RAM is a relatively modest RAM footprint. The server uses the same NVIDIA ConnectX-6 100GbE NIC as the workstations for connectivity. We also installed an NVIDIA A2 GPU for inferencing.

Turning to storage, KIOXIA sent us 24x XD7P Series Data Center NVMe SSDs. The KIOXIA XD7P Series E1.S SSDs are specifically designed to address the needs of hyperscale applications found in modern data centers, particularly regarding performance, power efficiency, and thermal requirements as outlined by the Open Compute Project (OCP) Datacenter NVMe SSD Specification.

These SSDs are available in 9.5mm and 15mm thickness E1.S variations, with the latter featuring a heatsink to enhance heat dissipation. KIOXIA’s proprietary architecture of the XD7P, which comprises its controller, firmware, and 5th-gen BiCS FLASH™, contributes to the overall efficiency, reliability, and performance. The new series is offered in capacities ranging from 1.92 TB to 7.68 TB to meet varying storage demands.
Some key features include power loss protection (PLP) and end-to-end data protection, which are critical for maintaining data integrity in scenarios involving unexpected power loss. In addition, the availability of self-encrypting-drive (SED) technology adds an extra layer of data security.
Regarding performance, the KIOXIA XD7P Series SSDs offer impressive potential numbers across different capacities. With sustained sequential read speeds of up to 7,200MB/s and sequential write speeds of up to 4,800 MB/s for larger capacities, these SSDs are designed to handle data-intensive tasks efficiently. Additionally, the sustained random read and write speeds of up to 1,650K IOPS and 200K IOPS, respectively, make them suitable for workloads demanding high I/O operations.
The XD7P leverages the E1.S form factor to strike a unique balance between performance and density. This positions the new drives as a forward-looking solution for flash storage in cloud and hyperscale data centers, addressing the evolving requirements of these demanding environments. The XD7P’s standardized size and built-in heatsinks provide an efficient means to accommodate our 24 front-mounted drives in the 1U SuperServer SSG-121E-NES24R, significantly increasing server density. Moreover, E1.S’s hot-swappability, coupled with its ability to handle high-performance workloads without thermal concerns, positions it as a practical replacement for the M.2 connector in data centers, with improved efficiency and performance for storage solutions like data centers.
The XD7P supports PCIe Gen4 x4 lanes. The drive plays well with Gen4 or Gen5 backplanes.
KIOXIA XD7P Series Quick Specifications
| Capacity | 7,680 GB | 3,840 GB | 1,920 GB | 7,680 GB | 3,840 GB | 1,920 GB |
| Basic Specifications | ||||||
| Form Factor | E1.S 15mm | E1.S 9.5mm | ||||
| Interface | PCIe 5.0, NVMe 2.0 | |||||
| Flash Memory Type | BiCS FLASH TLC | |||||
| Performance (Up to) | ||||||
| Sustained 128 KiB Sequential Read | 7,200MB/s | |||||
| Sustained 128 KiB Sequential Write | 4,800MB/s | 3,100MB/s | 4,800MB/s | 3,100MB/s | ||
| Sustained 4 KiB Random Read | 1,550K IOPS | 1,650K IOPS | 1,500K IOPS | 1,550K IOPS | 1,650K IOPS | 1,500K IOPS |
| Sustained 4 KiB Random Write | 200K IOPS | 180K IOPS | 95K IOPS | 200K IOPS | 180K IOPS | 95K IOPS |
| Power Requirements | ||||||
| Supply Voltage | 12 V ± 10 % | |||||
| Power Consumption (Active) | 20 W typ. | 20 W typ. | 16 W typ. | 20 W typ. | 20 W typ. | 16 W typ. |
| Power Consumption (Ready) | 5 W typ. | |||||
| Reliability | ||||||
| MTTF | 2,000,000 hours | |||||
| DWPD | 1 | |||||
Storage Server Performance With KIOXIA XD7P Series SSDs
To better understand how well this combo can perform, we started by shaking down the storage server with internal performance tests. When looking at the performance of the storage server, we focused on the full raw performance in a JBOD configuration in Ubuntu Linux to characterize what the storage is capable of.

We looked at peak throughput with a 4K random workload and then peak bandwidth with a 64k sequential workload. These tests were run leveraging VDbench in an Ubuntu 22.04 environment.
| Workload | Read | Write |
|---|---|---|
| 64K Sequential, 64-Thread Load | 158GB/s | 64.1GB/s |
| 4K Random, 512-Thread Load | 4.09M IOPS, 16GB/s | 4.5M IOPS, 17.7GB/s |
In our experimental setup, we decided to make use of Windows Storage Spaces in combination with the SMB3 protocol to leverage the high-speed KIOXIA drives. By leveraging Storage Spaces to create a resilient mirrored storage pool, we were able to ensure data integrity and optimize I/O performance.

SMB3’s enhanced features, like multichannel capabilities and persistent handles, allow for direct streaming of large data chunks at high throughput to multiple GPU workstations, bypassing traditional bottlenecks often associated with slower, CPU-bound memory. This setup had the dual advantage of enabling rapid data retrieval while allowing multiple workstations to concurrently access and load data to and from our KIOXIA-powered shared storage.
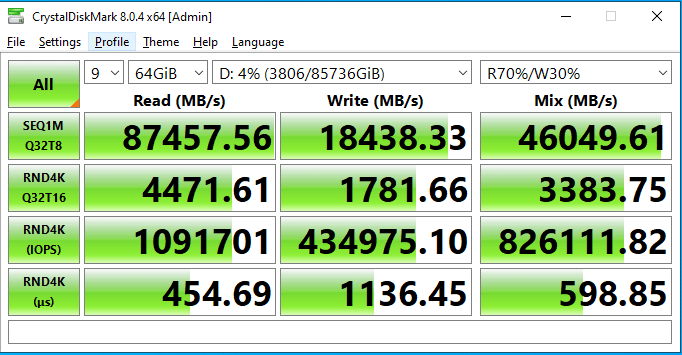
While our previous tests measured the raw performance of the KIOXIA XD7P Series SSDs without a filesystem in place, we took a second look at performance within the Windows Server 2022 environment. In this setup, with the mirrored virtual disk in place on our large storage pool, we used the NTFS filesystem.
To confirm strong performance from within our mirrored volume, we leveraged CrystalDiskMark locally on the server. This test was set up to measure sequential read and write performance with a 1MB transfer size as well as random 4K transfer speeds. Here, with a 64GB file footprint, we measured 87.4GB/s read and upwards of 18.4GB/s write.
For this paper, we’re looking at the overall capabilities of the entire AI solution, so while having this kind of performance profile is impressive, KIOXIA is clearly giving us more than we need. This is a good thing, as it means we could easily scale up the number of AI workstations or assign additional tasks to the storage server, be it scrubbing and cleaning our data or something else entirely.
Feeding AI Workstations Plentiful High-Speed Storage
With our GPU workstations located in the lab rack, networked with 100GbE to our KIOXIA-based all-flash 1U file server and shares set up, we went off to test this in practice. In our testing setup, we opted for a basic single 100GbE link from each workstation to our Dell Z9100 100GbE switch, which then connected back to the storage server with another 100GbE link.
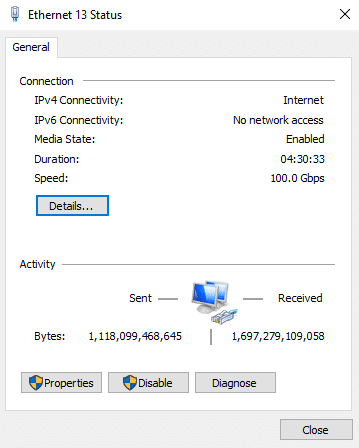
Here we were able to measure an impressive 11.4GB/s read and 11GB/s write from a Windows file share off our KIOXIA storage server.
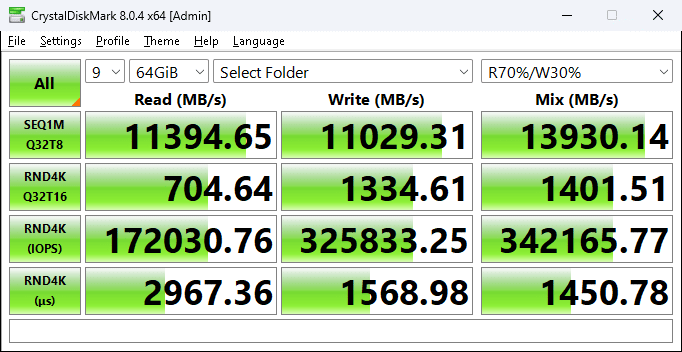
This level of performance and density over the wire to the AI workstations will provide tremendous value. Rather than trying to fill the AI workstations with local storage, we can share even more performant storage over 100GbE that’s more or less limitless in capacity.
GenAI in Practice – LLM Training Data Sets
Large Language Models (LLMs) are the most popular kids on the IT block these days. Training and fine-tuning them is a massive undertaking requiring monumental data sets and even larger GPU horsepower to process them. To load up some GPU workstations and do some real-world style testing, we took a dump of all text Reddit submissions and comments from 2012 to 2021 with some adjustments, as well as the Stanford Alpaca training dataset, to the LLaMa model for multiple finetuning attempts. The aim was to evaluate the efficiency, accuracy, and viability of the LLaMa model when subjected to large-scale real-world datasets.
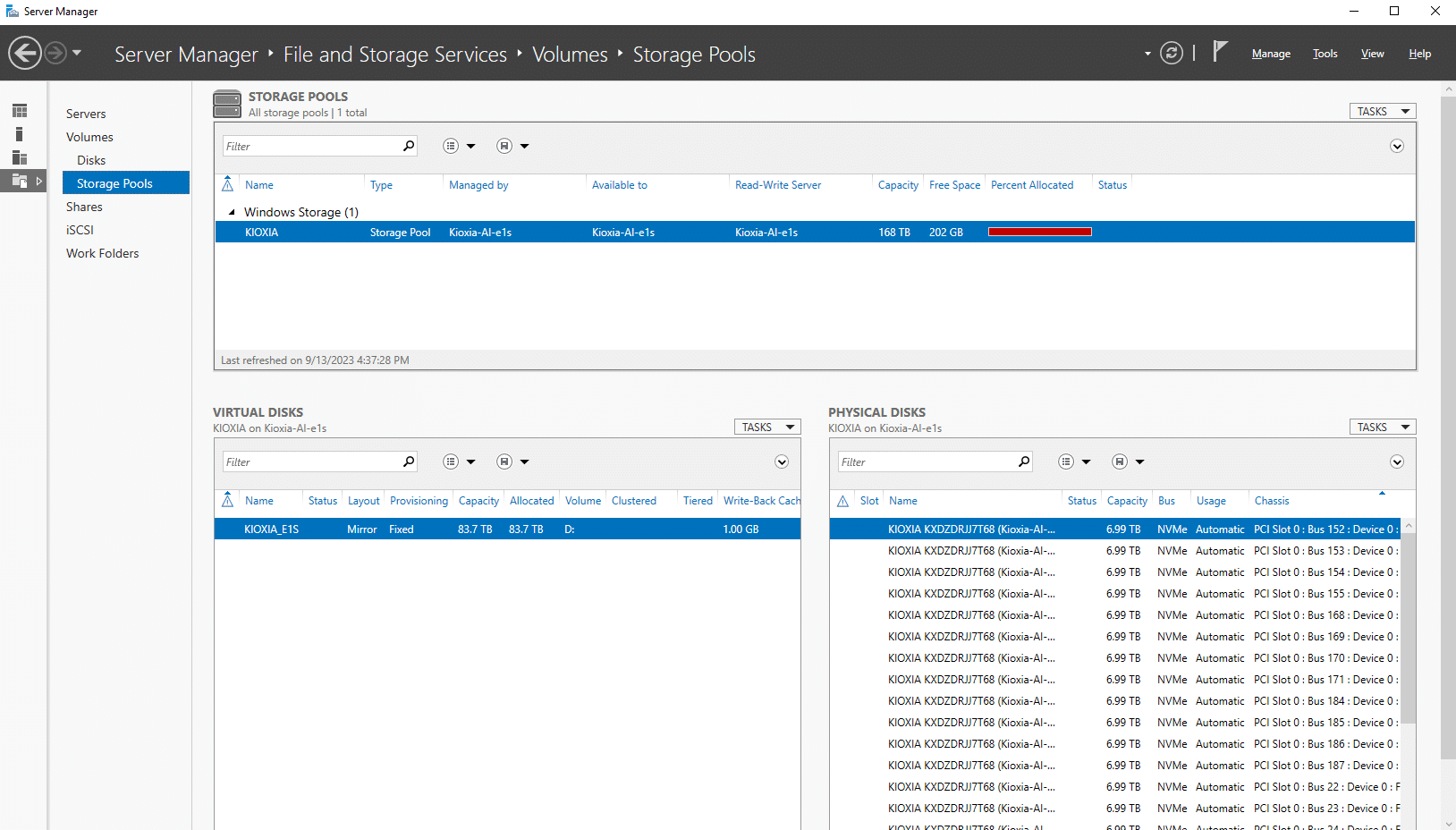
From the Windows Server 2022 platform, the 24 KIOXIA XD7P Series SSDs were grouped together into a 168TB pool and then into an 83.7TB mirrored volume. This volume was then shared across the 100GbE network with a file share to each of the three workstations to leverage. The Supermicro Superserver storage server used can handle a data size filling up the entire volume of 84TB without impacting performance. The current data size used is 5.6TB, but the volume can handle a much larger size.
Each GPU workstation was configured slightly differently in order to provide a diverse environment. We treated each machine as if it were an individual developer working with different models on a shared data set and did not distribute any training. The selection of Windows in this context was to emulate an early research or development scenario.
For context on the scale of data we’re dealing with, our data sets for this test comprised 16,372 files for LLM training data, consuming 3.7TB of disk space, and another 8,501 files for image training data taking up 1.9TB. In total, we worked with 24,873 files amounting to 5.6TB. It’s important to note that we deliberately restricted the size of our data sets and did not utilize the whole capacity of the storage for these experiments; otherwise, the training or fine-tuning process would have been time-prohibitive for this project. With this configuration, all workstations were able to share the datasets and save checkpoints and shards to the server for collaboration.
| Files | Size on Disk | |
| LLM Training Data | 16,372 | 3.7TB |
| Image Training Data | 8,501 | 1.9TB |
| Total | 24,873 | 5.6TB |
The software stack for both of our experiments was a simple configuration, and we leaned on the power of Anaconda and Windows Subsystem for Linux (WSL). Anaconda provides a robust environment for managing our Python-based machine learning libraries and dependencies, allowing for a modular and easily replicable setup across our GPU workstations. WSL helps to bridge the gap between Windows and Linux-based utilities, offering the flexibility to run Linux-specific data manipulation and orchestration tools seamlessly on our Windows workstations. We could run shell scripts for data preprocessing and kick off Python-based training jobs all within a unified workflow. Part of the reason that we selected this route was not only ease of configuration but also to level the playing field with our mixed GPU environment.
In the process of training, a few key observations were made:
- Data Diversity: The amalgamation of Reddit submissions and comments, spanning almost a decade, presented the model with an eclectic mix of topics, lexicons, and conversational contexts. This rich diversity provided a comprehensive platform for the model to understand and adapt to various nuances, sentiments, and cultural shifts over time.
- Model Scalability: Handling such an immense volume of data was a litmus test for the scalability of the LLaMa model. We found that as the training epochs increased, the model’s ability to predict and generate relevant responses improved considerably, highlighting its potential for large-scale applications. Overfitting was a concern after about a half dozen but was not necessarily a concern for this test, as the goal was to load up our GPUs and network share more so than create a general LLM model.
- Resource Optimization: Given the monumental GPU horsepower required, it was crucial to ensure efficient utilization of computational resources. Dynamic load balancing, periodic checkpoints, and on-the-fly data augmentation techniques were employed to ensure optimal performance.
- Transfer Learning Potency: Using the Stanford Alpaca training dataset in conjunction with Reddit data was instrumental in gauging the model’s transfer learning capabilities. The Alpaca dataset’s inherent structure and academic nature, juxtaposed with the informal and varied nature of Reddit data, posed an exciting challenge. The results indicated that LLaMa could seamlessly integrate knowledge from disparate sources, making it versatile and adaptable.
- Ethical Considerations: While the vast Reddit dataset offers a treasure trove of information, it is essential to ensure that personally identifiable information is excluded and the data is used ethically and responsibly. Rigorous data cleaning and anonymization processes would need to be put in place for the publication of the model to uphold user privacy.
This exercise underscored the instrumental role KIOXIA’s high-density drives played in enhancing our training efficiency. Given the colossal size of the datasets and the iterative nature of model training, storage speed, and capacity are often bottlenecks in such experiments. With KIOXIA’s drives, we were afforded the luxury of storing multiple instances of the dataset, intermediate model weights, and dozens of finetuned checkpoints. Their rapid read and write speeds facilitated quick data retrieval, allowing us to process multiple iterations of the finetuning with different hyperparameters in parallel, as depicted below.
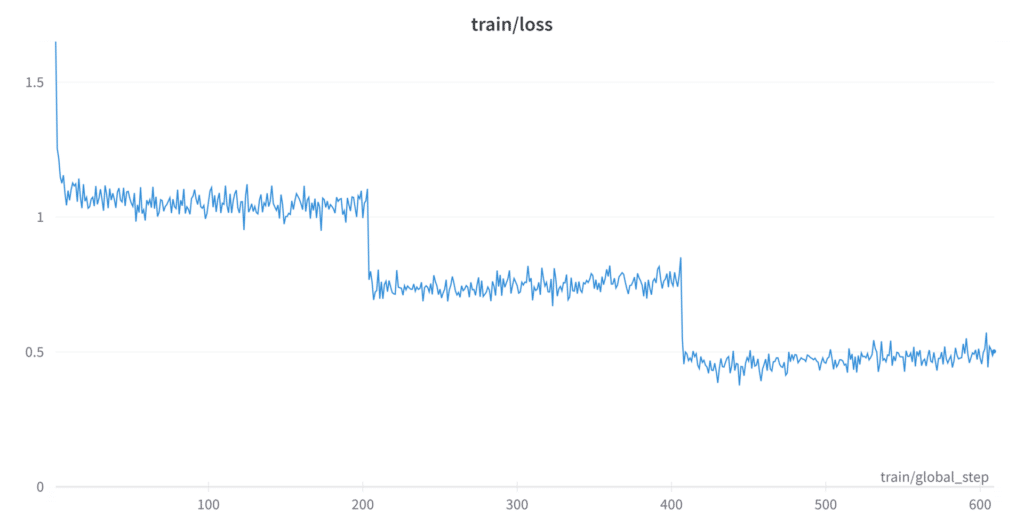
This was crucial in our pursuit to identify an optimal working checkpoint. Thanks to our newly built KIOXIA-powered storage server, we could focus on refining the model, tweaking parameters, and evaluating outcomes rather than being constrained by storage limitations. The high-density drives, therefore, were not just a storage solution but a pivotal asset that significantly accelerated our experimentation phase. This enabled a more thorough and efficient exploration of the LLaMa model’s potential and allowed us to develop our own novel convolutional neural network (CNN).
For the uninitiated, a convolutional neural network (CNN) is a specialized type of deep learning architecture predominantly used in image processing and computer vision tasks. Its distinct feature lies in the convolutional layers that automatically and adaptively learn spatial hierarchies of features from input images. Unlike traditional neural networks that rely on fully connected layers, CNNs take advantage of the spatial structure of the data by applying convolutional filters, which process input data in small chunks or receptive fields. This results in a network that can detect intricate patterns, such as edges, textures, and more complex structures, by building up from simpler ones. As data progresses deeper into the network, these patterns become more abstract, allowing CNNs to recognize and classify diverse and often convoluted visual entities hierarchically.
Through multiple finetuning attempts, the model showcased its capability to process massive datasets efficiently and highlighted its potential to produce relevant, context-aware, and nuanced outputs. As LLMs continue to gain traction, such experiments offer invaluable insights into their practical applications and limitations, paving the way for more sophisticated and user-centric AI solutions in the future.
Server Inference Capabilities
Executing inference operations on the same dataset offers a streamlined structure, simplifying data management intricacies. Our server isn’t merely a storage tool—it’s equipped to handle inference-related activities, including data ingestion and preparation.
To test inferencing on larger datasets, we selected a set of astrophotography images ranging from approximately 1Mb to 20Mb and ran a novel CNN that we are working on against them. In our scenario, the model is loaded to the GPU, and then an image or series of images is loaded for processing through the neural network.
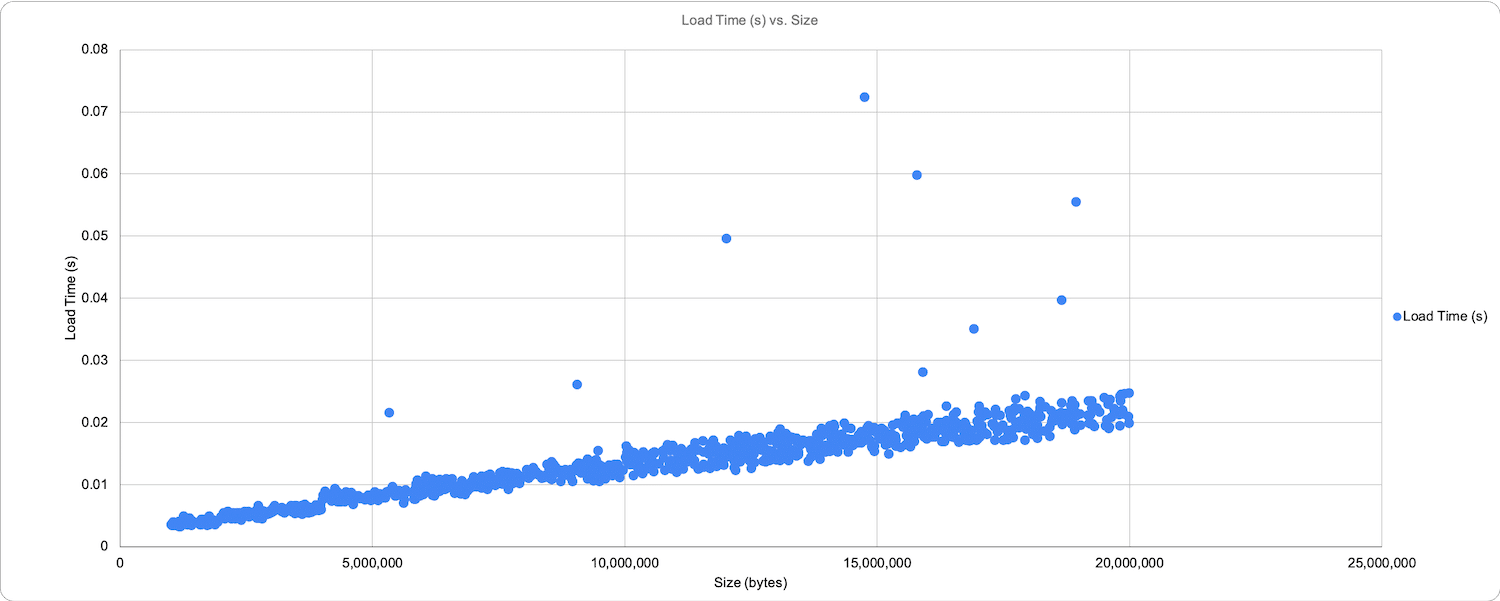
This is a broader storage footprint profile than you would encounter in something like a computer vision object classification from a standardized camera. Still, it illustrated the flexibility and consistency of the platform’s performance. In the graph below, which is sorted by size and not the order in which it was loaded (with the exception of a few outliers), the read-time and write-back times are scaled appropriately.

It is important to remember that this plot is sorted from smallest to largest to illustrate the linear performance of the drives and server. The actual run and dataset were randomized, so there could have been a 1Mb file read and written, followed immediately by a 20Mb file. The sort of the actual processing was in no particular order. Read times ranged from 10ms to 25ms, with outliers reaching into the 70ms+ range.
The chart below illustrates writing out a similarly linear progression with less deviation and shows the writes of the same files ranging from 12ms to 118ms.
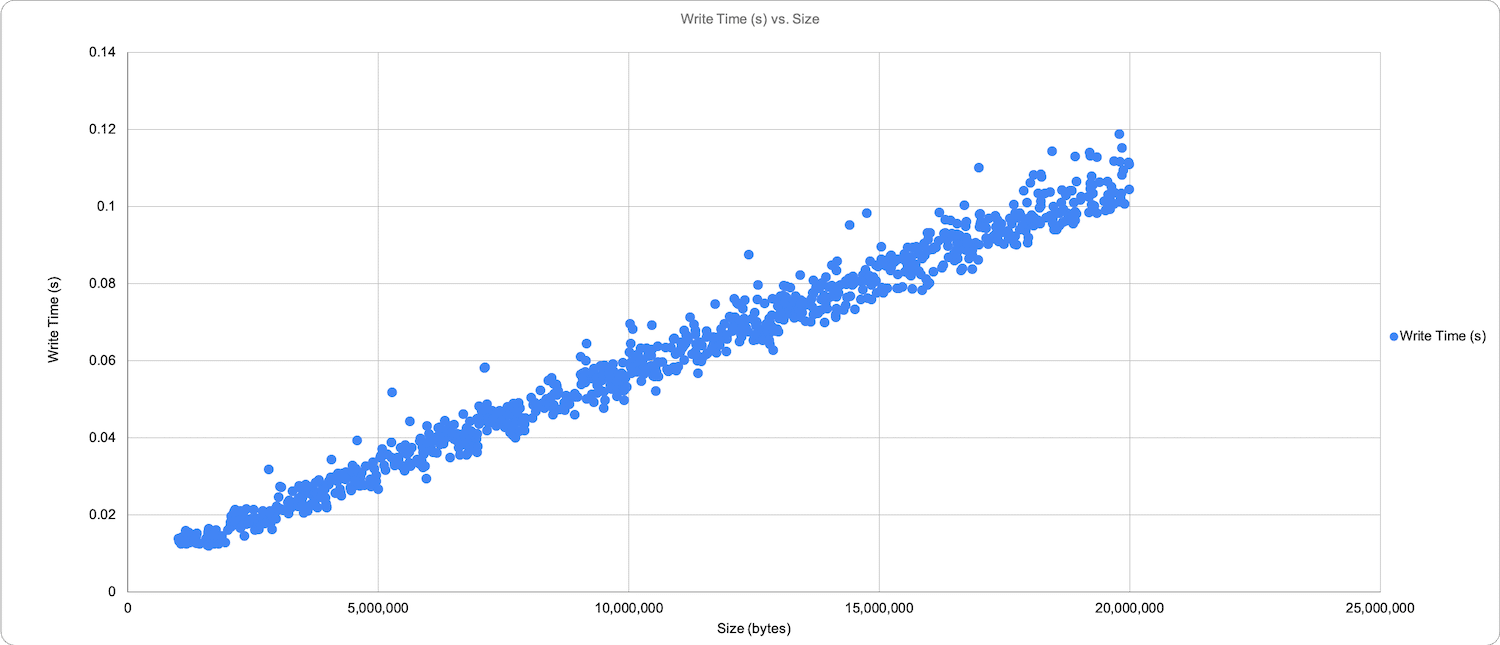
Another essential piece of information to remember is that this plot is an aggregate from tracking across three GPU workstations simultaneously running an inference to the same dataset. The KIOXIA drives were able to serve and write back an impressive 10.5GB to three GPU workstations running inference against a random dataset of 1000 images, excluding the serialized processing that the model uses. The whole process only took 59.62 seconds, or 59ms, to read and write back a single image.
Several options could improve speed and latency as this design scales up to multiple workstations or GPU servers. Implementing NVIDIA’s GPUDirect Storage, combined with the RDMA (Remote Direct Memory Access) protocol, would facilitate seamless data movement from the high-density shared storage straight into GPU memory. This approach would effectively bypass CPU and system memory bottlenecks. By leveraging NVMe over Fabrics and NVIDIA networking gear, large data volumes can be pre-loaded into GPU memory in near real-time. This would be particularly beneficial when dealing with LLMs, given their sizable datasets and computational demands. Such a capability could eliminate the need for data caching and would allow multiple workstations to read and ingest data from the shared storage pool simultaneously.
Final Thoughts
Addressing the I/O bottleneck of larger models is crucial for the continued evolution of machine learning, particularly when dealing with expansive datasets. A centralized, high-speed network share offers a threefold advantage over traditional local storage.
- First, it streamlines operations by eliminating the need to migrate massive datasets to individual workstations for training. This directly combats the I/O bottlenecks that can cripple machine learning projects, especially those involving deep learning models.
- Second, by opting for a centralized approach, you avoid overwhelming the workstation’s valuable PCIe lanes with excessive or even unattainable amounts of local storage. Thanks to the high-speed connection, this could enable more GPUs to process data more efficiently in parallel, making machine learning operations leaner and more agile.
- Third, centralized storage inherently brings better security measures. When data is stored in a secure, single location, it becomes easier to manage access controls and implement security protocols, reducing the risk of data breaches, physical threats, or unauthorized access.
Additionally, centralizing data ensures improved data consistency and an additional layer of data redundancy. Workstations access the most up-to-date data from a single source, minimizing discrepancies in results due to outdated or inconsistent training or fine-tuning data or model checkpoints. This also simplifies data management and conserves storage space.

As scalability, efficiency, and security become increasingly important in the hypersonically evolving landscape of AI and machine learning, the shift to centralized, dense, high-speed storage provided by technology like the KIOXIA E1.S platform presents a compelling case. This is critical not just for enhanced performance but for a fundamental transformation in how we approach data management and model training.
KIOXIA XD7P Series E1.S NVMe Data Center Spec Sheet
This report is sponsored by KIOXIA America, Inc. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed