
To validate the advantages of DRAM in AI systems we conducted a series of tests using eight Kingston KSM56R46BD4PMI-64HAI DDR5 memory modules.
System DRAM plays an important role in AI, particularly in CPU inferencing. As AI applications grow more complex, the demand for faster and more efficient memory solutions becomes increasingly critical. We wanted to look at the significance of system DRAM in AI, focusing on CPU inferencing and the vital role of utilizing multiple memory channels.

Kingston KSM56R46BD4PMI-64HAI DDR5
The Importance of System DRAM in AI
System DRAM is the central hub for data in AI systems. Data is temporarily stored for quick access by the CPU, allowing rapid data processing.
This is particularly crucial in AI applications where dealing with large datasets quickly and efficiently is not just an advantage but a necessity. Here’s a closer look at the multifaceted role of System DRAM in enhancing AI capabilities:
- Speed and Efficiency: AI algorithms, particularly in inferencing, require high-speed memory to process vast amounts of data. System DRAM provides this speed, reducing latency and increasing overall system performance.
- Capacity: Modern AI applications demand large memory capacities. High-capacity DRAM ensures that larger datasets can be processed in memory, avoiding the slower process of fetching data from storage devices.
- Reliability: In AI, data integrity is paramount. System DRAM, with its error-correcting capabilities, ensures that data corruption is minimized, essential in applications where accuracy is critical.
- Scalability: As AI models grow increasingly complex, the ability to scale memory resources becomes extremely important. System DRAM offers the scalability necessary to accommodate the increasing demands of evolving AI applications and their escalating data requirements.
- Bandwidth: System DRAM’s higher bandwidth allows faster data transfer rates, enabling quicker access to data. This is especially beneficial for training complex neural networks and managing large-scale data processing tasks.
CPU Inferencing and DRAM
In artificial intelligence, CPU inferencing– the process of using a trained model to make predictions or decisions–and the role of DRAM are critical components that significantly influence the efficiency and speed of AI applications. This phase is memory-intensive due to the need to quickly access and process large datasets. It’s particularly demanding on system memory due to the complex nature and size of the data involved.

DRAM is pivotal in optimizing CPU inferencing for AI operations through several key enhancements. First, it provides the necessary bandwidth to achieve high data throughput, which is essential for rapid data processing and decision-making in CPU inferencing. This increased throughput directly translates to swifter performance in complex tasks.
Additionally, by storing data close to the CPU, system DRAM significantly reduces the time to access data, thereby minimizing overall inferencing latency. This proximity is crucial for maintaining a quick and responsive system. Lastly, as data is processed fast and access times are shortened, the overall power required for CPU inferencing tasks is notably reduced. This leads to more energy-efficient operations and ensures a more sustainable and cost-effective environment for AI applications.
The Role of Multiple Memory Channels
System memory architecture is an essential element in defining the performance of AI applications. Utilizing multiple memory channels is like widening a highway – it facilitates a greater flow of data traffic concurrently, significantly enhancing the overall system performance. Here’s how employing multiple channels can optimize AI operations:
- Increased Bandwidth: Multiple channels increase the memory bandwidth. This is crucial for AI applications, as they can process and analyze more data simultaneously, leading to faster inferencing times.
- Parallel Processing: With multiple channels, data can be processed in parallel, significantly speeding up AI computations that involve large datasets.
- Reduced Bottlenecks: Multiple memory channels help in reducing system bottlenecks. Distributing the memory load enables each channel to operate more efficiently, enhancing overall system performance.
Test Data
To validate the advantages of DRAM in AI systems, particularly CPU inferencing, we’ve conducted a series of tests using eight Kingston KSM56R46BD4PMI-64HAI DDR5 memory modules across varying channel configurations.

| KSM48R40BD4TMM-64HMR 64GB 2Rx4 8G x 80-Bit PC5-4800 CL40 Registered EC8 288-Pin DIMM | KSM56R46BD4PMI-64HAI 64GB 2Rx4 8G x 80-Bit PC5-5600 CL46 Registered EC8 288-Pin DIMM | |
| Transfer Speed | 4800 MT/s | 5600 MT/s |
| CL(IDD) | 40 cycles | 46 cycles |
| Row Cycle Time (tRCmin) | 48ns(min) | 48ns(min) |
| Refresh to Active/Refresh Command Time (tRFCmin) | 295ns(min) | 295ns(min) |
| Row Active Time | 32ns(min) | 32ns(min) |
| Row Precharge Time | 16ns(min) | 16ns(min) |
| UL Rating | 94 V – 0 | 94 V – 0 |
| Operating Temperature | 0 C to +95 C | 0 C to +95 C |
| Storage Temperature | -55 C to +100 C | -55 C to +100 C |
To establish a baseline, we initiated focused CPU benchmarks and Geekbench tests, gauging the isolated capabilities of the CPU. To seriously stress the entire system, including memory and storage, we selected y-cruncher for its rigorous demands. This approach allows us to assess the cohesion and endurance of the whole system under extreme conditions, providing a clear picture of overall performance and stability.
Ultimately, these results will provide concrete data on how system DRAM and the number of memory channels directly impact computational speed, efficiency, and overall system performance in AI applications.
Geekbench 6
First up is Geekbench 6, a cross-platform benchmark that measures overall system performance. You can find comparisons to any system you want in the Geekbench Browser. Higher scores are better.
| Geekbench 6 | Kingston DDR5 2 Channels |
Kingston DDR5 4 Channels |
Kingston DDR5 8 Channels |
| CPU Benchmark: Single-Core |
2,083 | 2,233 | 2,317 |
| CPU Benchmark: Multi-Core |
14,404 | 18,561 | 19,752 |
The Geekbench 6 results for the Kingston DDR5 show a range of variations when comparing 2, 4, and 8-channel setups. In single-core tests, the scores increase modestly but consistently from 2,083 with two channels to 2,317 with eight channels, indicating improved efficiency and throughput for individual core operations as the number of channels increases. However, the most dramatic performance enhancement is observed in multi-core tests, where the scores leap from 14,404 with two channels to a substantial 19,752 with eight channels.
y-cruncher
y-cruncher, a multi-threaded and scalable program, can compute Pi and other mathematical constants to trillions of digits. Since its launch in 2009, y-cruncher has become a popular benchmarking and stress-testing application for overclockers and hardware enthusiasts. Faster is better in this test.
| y-cruncher (Total Computation time) |
Kingston DDR5 2 Channels |
Kingston DDR5 4 Channels |
Kingston DDR5 8 Channels |
| 1 billion digits | 18.117 Seconds | 10.856 Seconds | 7.552 Seconds |
| 2.5 billion digits | 51.412 Seconds | 31.861 Seconds | 20.981 Seconds |
| 5 billion digits | 110.728 Seconds | 64.609 Seconds | 46.304 Seconds |
| 10 billion digits | 240.666 Seconds | 138.402 Seconds | 103.216 Seconds |
| 25 billion digits | 693.835 Seconds | 396.997 Seconds | N/A |
The y-cruncher benchmark across 2, 4, and 8 channels demonstrates a clear and consistent improvement in computational speed as the number of channels increases. For calculating 1 billion digits of Pi, the total computation time decreases significantly from 18.117 seconds with two channels to just 7.552 seconds with eight channels.
This trend of reduced computation time continues across all tested scales, with the time for calculating 25 billion digits dropping from 693.835 seconds to 396.997 seconds when moving from 2 to 4 channels.
3DMark – CPU Profile
The CPU Profile test in 3DMark specifically measures the processor’s performance across a range of thread counts, offering a detailed look at how different configurations of DDR5 RAM channels impact CPU workload handling and efficiency. This test is beneficial for understanding the performance nuances in memory-intensive operations and multi-threaded applications when using various DDR5 RAM channel setups.
| 3DMark – CPU Profile – Scores | |||
| Thread count | Kingston DDR5 2 Channels |
Kingston DDR5 4 Channels |
Kingston DDR5 8 Channels |
| Max Threads | 15,822 | 15,547 | 15,457 |
| 16 threads | 10,632 | 9,515 | 10,367 |
| 8 threads | 4,957 | 6,019 | 5,053 |
| 4 threads | 3,165 | 3,366 | 3,323 |
| 2 threads | 1,726 | 1,765 | 1,781 |
| 1 thread | 907 | 911 | 884 |
The 3DMark CPU Profile scores for the Kingston DDR5 RAM show a somewhat complex picture, indicating that the optimal number of channels may vary depending on the thread count and specific workload.
At the maximum thread count, the scores are highest with two channels (15,822) and decrease slightly with more channels, suggesting that the additional channels don’t provide a benefit for highly parallel tasks. However, at eight threads, the 4-channel configuration scores the highest (6,019), indicating a sweet spot where the additional channels improve handling of mid-level parallelism. The scores are similar across all channel configurations at lower thread counts (4, 2, and 1 thread).
These results suggest that while more channels can benefit certain multi-threaded operations, the impact varies with the nature of the task and the architecture of the system. That is, more isn’t always better for every use case.
DRAM Channel Effect on AI Inferencing
All tests were performed on an Intel Xeon w9-3475X CPU, utilizing the Intel OpenVINO API through the UL Labs Procyon Benchmark.

Featuring an array of AI inference engines from top-tier vendors, the UL Procyon AI Inference Benchmark caters to a broad spectrum of hardware setups and requirements. The benchmark score provides a convenient and standardized summary of on-device inferencing performance. This enables us to compare and contrast various hardware setups in real-world situations without requiring in-house solutions.
Results are within the margin of error on FP32, but things get interesting when you move to INT, looking at the granular scores rather than the overall score.
Bigger Number Better on Overall Score, Small Number Better on Times.
First up is FP32 Precision
| FP 32 | ||
| Precision | 8 Channel | 2 Channel |
| Overall Score | 629 | 630 |
| MobileNet V3 Average Inference Time | 0.81 | 0.77 |
| ResNet 50 Average Inference Time | 1.96 | 1.82 |
| Inception V4 Average Inference Time | 6.93 | 7.31 |
| DeepLab V3 Average Inference Time | 6.27 | 6.17 |
| YOLO V3 Average Inference Time | 12.99 | 13.99 |
| REAL-ESRGAN Average Inference Time | 280.59 | 282.45 |
Up next is FP16 Precision
| FP 16 | ||
| Precision | 8 Channel | 2 Channel |
| Overall Score | 645 | 603 |
| MobileNet V3 Average Inference Time | 0.81 | 0.76 |
| ResNet 50 Average Inference Time | 1.91 | 1.94 |
| Inception V4 Average Inference Time | 7.11 | 7.27 |
| DeepLab V3 Average Inference Time | 6.27 | 7.13 |
| YOLO V3 Average Inference Time | 12.93 | 15.01 |
| REAL-ESRGAN Average Inference Time | 242.24 | 280.91 |
And Finally INT
| INT | ||
| Precision | 8 Channel | 2 Channel |
| Overall Score | 1,033 | 1004 |
| MobileNet V3 Average Inference Time | 0.71 | 0.73 |
| ResNet 50 Average Inference Time | 1.48 | 1.48 |
| Inception V4 Average Inference Time | 4.42 | 4.47 |
| DeepLab V3 Average Inference Time | 4.33 | 4.99 |
| YOLO V3 Average Inference Time | 5.15 | 5.12 |
| REAL-ESRGAN Average Inference Time | 122.40 | 123.57 |
DRAM Throughput and Latency
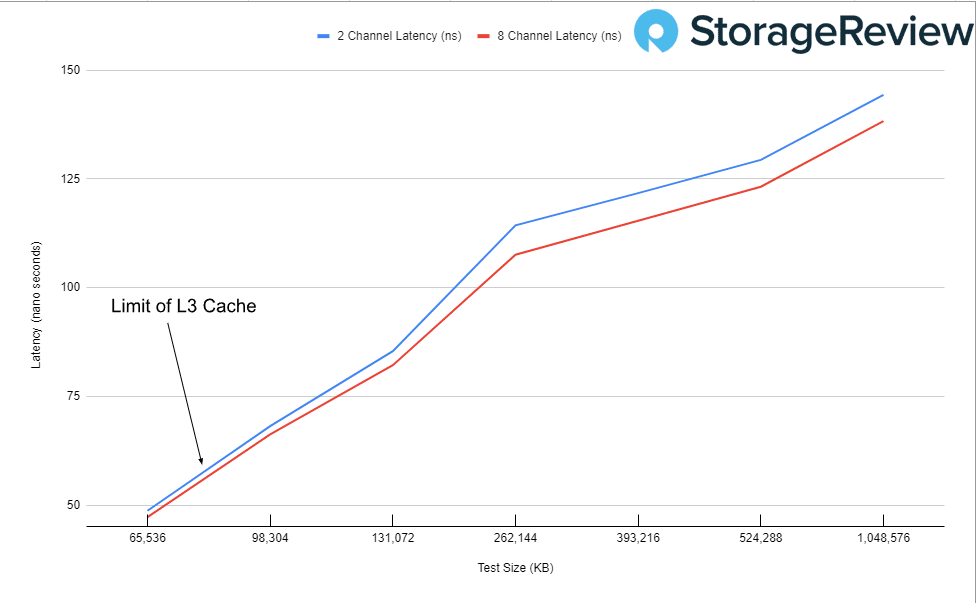
First up, looking at the latency of 2-channel and 8-channel DRAM configuration. We profiled the entire CPU and memory, but our only focus was the transition from the CPU Cache to the DRAM. Since our Xeon W9-3475X CPU only has 82.50MB of L3 cache, we pulled out the chart at the beginning of that transition.
| Test Size (KB) | 2 Channel Bandwidth |
8 Channel Latency (ns)
|
| 65,536 | 48.70080 | 47.24411 |
| 98,304 | 68.16823 | 66.25920 |
| 131,072 | 85.38640 | 82.16685 |
| 262,144 | 114.32570 | 107.57450 |
| 393,216 | 121.74860 | 115.40340 |
| 524,288 | 129.38970 | 123.22100 |
| 1,048,576 | 144.32880 | 138.28380 |
Here, we can see that adding more channels improved the latency by a small margin.
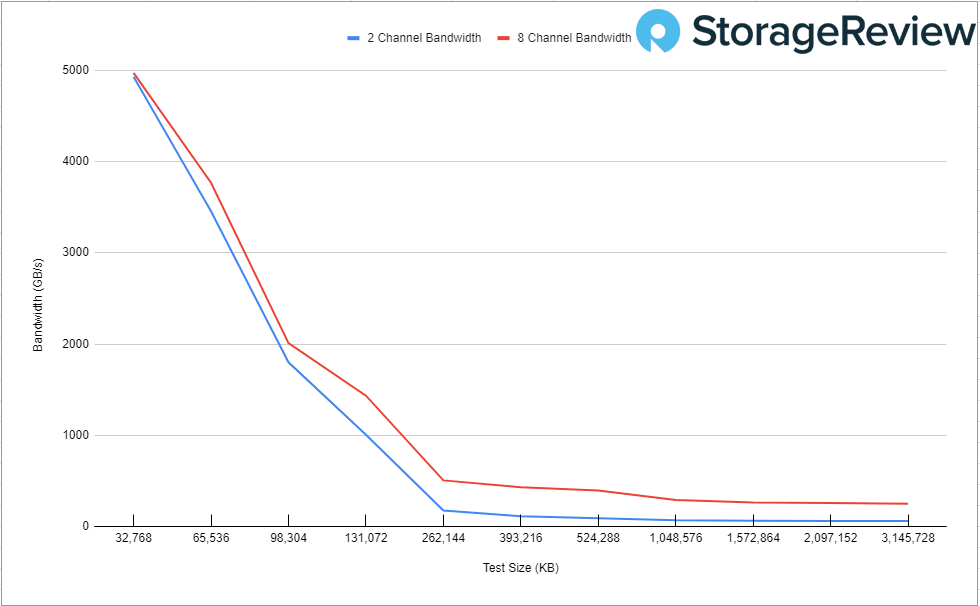
Moving on to bandwidth on the AVX512 instructions, we can see a bit more of a dramatic difference in bandwidth between 2-channel and 8-channel. The Delta here is the performance hit between 2 and 8 channels.
| Test Size (KB) AVX512 | 2 Channel Bandwidth(GB/s) | 8 Channel Bandwidth(GB/s) | Delta(GB/s diff) |
| 65,536 | 3,455.28 | 3,767.91 | -312.63 |
| 98,304 | 1,801.88 | 2,011.83 | -209.95 |
| 131,072 | 1,009.21 | 1,436.50 | -427.28 |
| 262,144 | 178.52 | 508.65 | -330.13 |
| 393,216 | 114.76 | 433.91 | -319.15 |
| 524,288 | 94.81 | 396.90 | -302.09 |
| 1,048,576 | 71.12 | 293.26 | -222.13 |
| 1,572,864 | 66.98 | 267.44 | -200.46 |
| 2,097,152 | 65.08 | 262.50 | -197.42 |
| 3,145,728 | 63.63 | 253.12 | -189.50 |
Conclusion
In summary, system DRAM is a cornerstone in the architecture of AI systems, especially in CPU inferencing. Its ability to provide high-speed, reliable, and extensive memory is indispensable. Furthermore, leveraging multiple memory channels can significantly enhance the performance of AI applications by increasing bandwidth, enabling parallel processing, and minimizing bottlenecks. As AI continues to evolve, optimizing system DRAM will remain a key focus for ensuring the highest levels of performance and efficiency.

AI Generated Image, Prompted by Jordan Ranous
Moreover, the test data reinforces this notion, demonstrating the tangible benefits of enhanced memory configurations. As we push the boundaries of AI and data processing, the strategic enhancement of system memory will be crucial in supporting the next generation of AI innovation and real-world application.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed