
In an astounding display of computational prowess, the StorageReview Lab Team has set a consecutive world record by calculating pi to an incredible 202,112,290,000,000 digits. This remarkable achievement eclipses the previous record of 105 trillion digits, also held by the team. It showcases the unparalleled capabilities of modern high-performance computing and properly designed commodity hardware platforms.
In an astounding display of computational prowess, the StorageReview Lab Team has set a consecutive world record by calculating pi to an incredible 202,112,290,000,000 digits. This remarkable achievement eclipses the previous record of 105 trillion digits, also held by the team. It showcases the unparalleled capabilities of modern high-performance computing and properly designed commodity hardware platforms.
Unprecedented Computational Feat
The StorageReview Lab Team utilized a highly advanced setup to accomplish this feat. Leveraging Intel Xeon 8592+ CPUs and Solidigm P5336 61.44TB NVMe SSDs, the team ran an almost continuous calculation for 85 days, consuming nearly 1.5 Petabytes of space across 28 Solidigm SSDs. This groundbreaking project demonstrates significant advancements in both computational power and efficiency.

“This new record highlights the extraordinary potential of today’s high-performance computing infrastructure,” said Jordan Ranous, the System Architect from the StorageReview Lab Team. “By achieving this milestone, we are not only setting new benchmarks in computational mathematics but also paving the way for future innovations across various scientific and engineering disciplines.”
In March 2024, the StorageReview Lab Team achieved a world record by calculating pi to 105 trillion digits. Utilizing a dual-processor AMD EPYC system with 256 cores and nearly a petabyte of Solidigm QLC SSDs, the team tackled significant technical challenges, including memory and storage limitations. This milestone demonstrated modern hardware’s capabilities and provided valuable insights into optimizing high-performance computing systems.
“Not only did the Solidigm drives and Dell PowerEdge R760 work together flawlessly, the nearly hands-off nature of this new record was a welcomed change after the perils of our last record attempt,” said Kevin O’Brien, StorageReview Lab Director. “After what we went through on the last test run to 105, I am glad that we chose the platform we did for the big record,” he continued. For more details on the previous 105 Trillion digit attempt and the challenges, you can read the full article here.
CompSci and Math Lesson
When we first started looking at fun ways to test large-capacity SSDs, the obvious answer was in our CPU and system reviews: y-cruncher. When utilizing swap space for extensive calculations, the space requirement is roughly 4.7:1 on the digits, so 100 Trillion digits need about 470TiB of space. Without getting too deep into the math and computer science weeds, y-cruncher, the Chudnovsky algorithm, is based on a rapidly converging series derived from the theory of modular functions and elliptic curves. The core of the algorithm relies on the following infinite series:

The number one question we received regarding our 100T and 105T computations was, “Okay, no big deal. Why does this take so long and need so much memory?” This question was among other annoying concerns about open source and Alex Yee’s programming capabilities. Let’s take a step back and look at this from the system level.
Computing an extensive number of digits of Pi, such as 100 trillion, necessitates substantial space due to the large arithmetic operations involved. The challenge primarily lies in multiplying large numbers, which inherently requires significant memory. For instance, the best algorithms for multiplying N-digit numbers need roughly 4N bytes of memory, most of which serve as scratch space. This memory must be accessed multiple times during computation, turning the process into a disk I/O intensive task rather than a CPU-bound one.
The Chudnovsky formula, widely used for computing many digits of Pi, demands extensive arithmetic operations. These multiplication, division, and squaring operations are often reduced to large multiplications. Historically, supercomputers used AGM algorithms, which, despite being slower, were easier to implement and benefited from the brute force of numerous machines. However, modern advancements have shifted the bottleneck from computational power to memory access speeds.
Processor Arithmetic Logic Units (ALUs) and Floating Point Units (FPUs) handle these large multiplication numbers similarly to manual multiplication on paper, breaking them into smaller, manageable operations. Previously, Pi calculations were compute-bound, but today’s computational power surpasses memory access speeds, making storage and reliability the critical factors in setting Pi records. For example, little performance difference was observed between our 128-core Intel machine and a 256-core AMD Bergamo; the focus was on disk I/O efficiency.
Solidigm SSDs play a crucial role in these computations, not due to their inherent speed but because of their exceptional storage density. Consumer-grade NVMe drives can store up to 4TB in a small volume, while enterprise SSDs stack these chips for even greater capacity. Although QLC NAND can be slower than other types of flash memory, the parallelism in these dense SSDs delivers higher aggregate bandwidth, making them ideal for large-scale Pi calculations.
Solidigm QLC NVMe SSDs, Enabling The Madness
Okay, if you’re still awake and with me here, all you need to know is that when computing numbers are too large to fit into memory, computers must use software algorithms for multi-precision arithmetic. These algorithms break down the large numbers into manageable chunks and perform the division using special techniques. This is where the Solidigm P5336 61.44TB NVMe SSDs come in. y-cruncher takes these manageable chunks, accumulates them in system memory first, and then swaps them into a scratch drive space.
Remember, we need about 4.7:1 for the swap, as each part of that scary formula up there has to be represented by many, many bits.
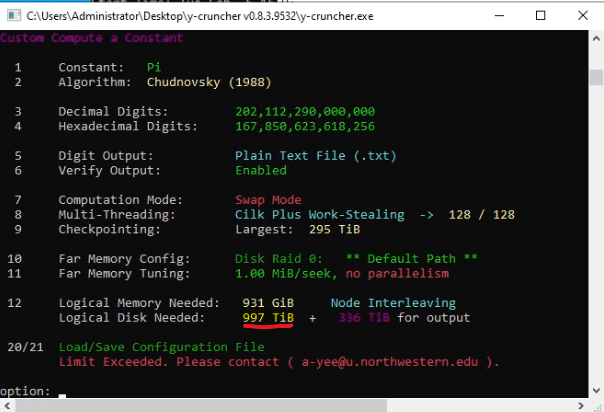
y-cruncher has a built-in estimator for the amount of drive space needed (still labeled disk*cough*) that we found to be perfectly accurate in this, and past runs.
While you could toss some HDDs or some object storage at it, the raw size is only one single part of a very complex equation, as we uncovered in our first round. The ability to get large enough and fast enough storage close to the compute device is a recurring theme across our life at StorageReview these days with the surge of AI. The performance of the swap space is the single biggest bottleneck in this computation. Direct attached NVMe is the highest performance available, and while some options may have the fastest throughput per device, our large, very dense array of QLC, in aggregate, was more than up to the task.
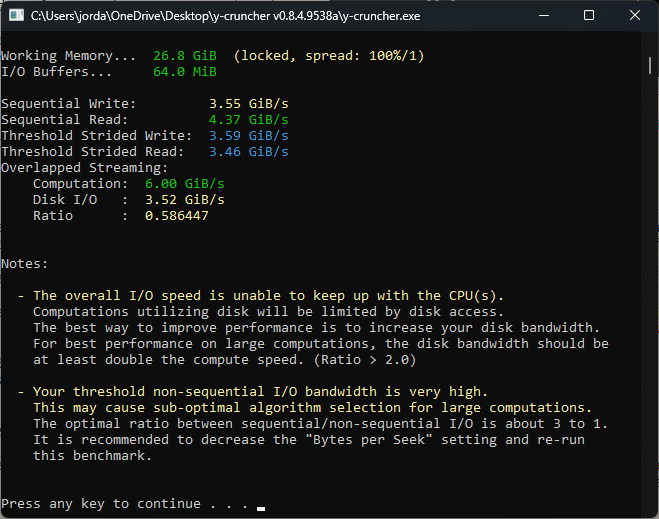
Consumer Drive and CPU performance. NOT the record system
y-cruncher has a built-in benchmark that lets you pull on all the levers and adjust the knobs to find the best performance settings for your array of disks. This is extremely important. The screenshot above shows that the benchmark provides feedback for this consumer system, with metrics about how fast the CPU can crunch through and the SSD performance.
Alex has some extensive documentation available, but to boil it all down, we found through weeks of testing that just letting y-cruncher interact with the drives directly is the best way to go. We have tested network targets, drives behind a SAS RAID card, NVMe RAID cards, and iSCSI targets. When giving control of the hardware to y-cruncher, the performance is night and day. iSCSI also seems acceptable, but we only tested that for the output file, which can utilize “Direct IO” for that interaction. The swap mode RAID code must be relatively well thought out, and we can deduce from our testing and conversation with the developer that it works with the drives at a low level.
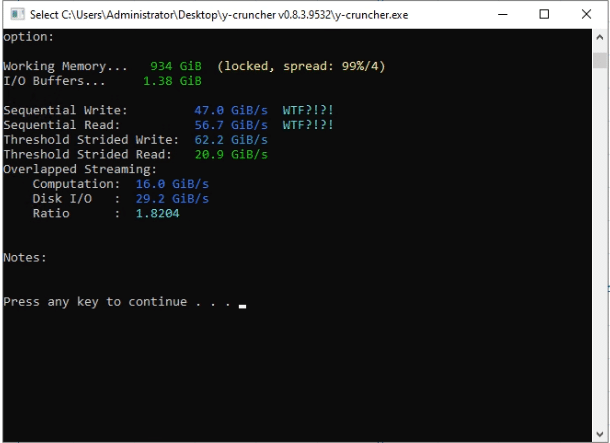
The 61.44TB Solidigm Drives are starting to emerge as the best answer to many pains in that space. Running the benchmark on our system, we see that the drives perform at spec for both read and write. We specifically selected the Intel CPUs to be able to be as close to the optimal 2:1 Drive to Computation ratio. This is the optimal ratio, so you are not wasting time on the CPU waiting for drives to perform. As drive technology gets faster, we can do more extensive, rapid runs by selecting higher core count CPUs.
“Custom” Dell PowerEdge R760 Server
As the saying goes, the third time’s a charm. This isn’t our first rodeo with smashing records with Pi; we took lessons from our first two iterations to build the best Pi platform. Our first build leveraged a 2U server with 16 NVMe bays and three internal SSD sleds. With 30.72TB Solidigm P5316 SSDs, we contained the swap storage for y-cruncher, but we had to leverage an HDD-based storage server for the output file. It was less than optimal, especially during the end of the write-out phase. Our 2nd platform used the same server, with an external NVMe JBOF attached, which gave us additional NVMe bay—but at the cost of sensitive cabling and unbalanced performance. The downside to both platforms was needing to rely on external hardware throughout the entire y-cruncher run at the cost of added power and additional points of failure.

For this run, we wanted to leverage one all-direct-NVMe single server and have enough space for our y-cruncher swap storage and output storage under one sheet-metal roof. Enter the Dell PowerEdge R760 with the 24-bay NVMe Direct Drives backplane. This platform leverages an internal PCIe switch to get all NVMe drives talking to the server simultaneously, bypassing any need for additional hardware or RAID devices. We then pieced together a PCIe riser configuration from multiple R760s in our lab environment, giving us four PCIe slots in the rear for additional U.2 mounted NVMe SSDs. A bonus was taking larger heatsinks off another R760, giving us as much turbo-boost headroom as possible. Direct Liquid Cooling came into our lab a month too late to be implemented in this run.
“The StorageReview Lab Team’s calculation of pi to over 202 trillion digits, achieved using 5th Gen Intel Xeon processor, underscores the power and efficiency of these CPUs. Leveraging the increased core count and advanced performance features of the 5th Gen Xeon processor, this milestone sets a new benchmark in computational mathematics and continues to pave the way for innovations across various scientific and engineering workloads,” said Suzi Jewett, Intel general manager for 5th Gen Intel Xeon Processor Products
While you technically could order a Dell configuration precisely like the one used in this run, it was not something they had lying around and needed to be pieced together. (Maybe Michael will run a limited edition “Pi” batch of R760s with this exact config, custom paint, and the SR logo.)

The power supply size was also critical to this run. While most would immediately think the CPUs draw most of the power, having 28 NVMe SSDs under one roof is a considerable power impact. Our build leveraged the 2400W PSUs, which, as it turned out, only barely worked. We had a few near-critical level power draw moments where we would have been underpowered if the system had dropped one power supply connection. This hit early on; power consumption skyrocketed while the CPU loads peaked, and the system increased I/O activity to all SSDs. If we had to do this again, the 2800W models would have been preferred.
Performance Specs
Technical Highlights
- Total Digits Calculated: 202,112,290,000,000
- Hardware Used: Dell PowerEdge R760 with 2x Intel Xeon 8592+ CPUs, 1TB DDR5 DRAM, 28x Solidigm 61.44TB P5336
- Software and Algorithms: y-cruncher v0.8.3.9532-d2, Chudnovsky
- Data Storage: 3.76PB written per Drive, 82.7PB across the 22 disks for swap array
- Calculation Duration: 100.673 Days
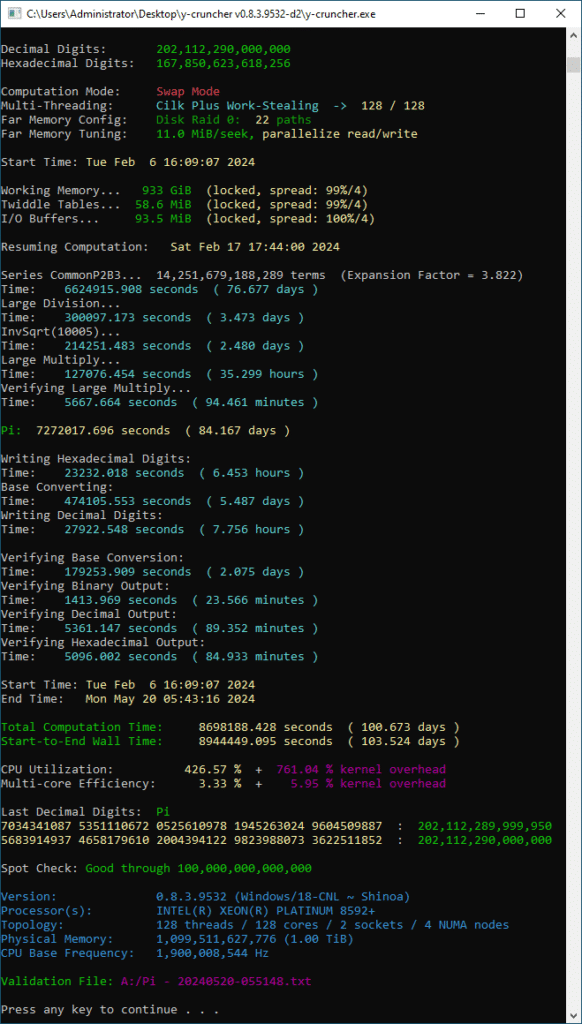
y-cruncher Telemetry
- Logical Largest Checkpoint: 305,175,690,291,376 ( 278 TiB)
- Logical Peak Disk Usage: 1,053,227,481,637,440 ( 958 TiB)
- Logical Disk Bytes Read: 102,614,191,450,271,272 (91.1 PiB)
- Logical Disk Bytes Written: 88,784,496,475,376,328 (78.9 PiB)
- Start Date: Tue Feb 6 16:09:07 2024
- End Date: Mon May 20 05:43:16 2024
- Pi: 7,272,017.696 seconds, 84.167 Days
- Total Computation Time: 8,698,188.428 seconds, 100.673 Days
- Start-to-End Wall Time: 8,944,449.095 seconds, 103.524 Days
The largest known digit of Pi is 2, at position 202,112,290,000,000 (two hundred two trillion, one hundred twelve billion, two hundred ninety million).
Broader Implications
While calculating pi to such a vast number of digits might appear to be an abstract challenge, the practical applications and techniques developed during this project have far-reaching implications. These advancements can enhance various computational tasks, from cryptography to complex simulations in physics and engineering.
The recent 202 trillion digit pi calculation highlights significant advancements in storage density and total cost of ownership (TCO). Our setup achieved an astonishing 1.720 petabytes of NVMe SSD storage within a single 2U chassis. This density represents a leap forward in data storage capabilities, especially considering the total power consumption peaked at only 2.4kW under full CPU and drive load.
This energy efficiency contrasts traditional HPC record runs that consume significantly more power and generate excessive heat. Power consumption increases exponentially when you factor in additional nodes for scale-out storage systems if you need to expand low-capacity shared storage compared to high-density local storage. Heat management is critical, especially for smaller data centers and server closets. Cooling traditional HPC record systems is no small feat, requiring data center chillers that can draw more power than the equipment running alone. By minimizing power consumption and heat output, our setup offers a more sustainable and manageable solution for small businesses. As a bonus, most of our run was performed with fresh air cooling.
To put this into perspective, imagine the challenges those running with networked shared storage and un-optimized platforms face. Those setups would require one or more data center chillers to keep temps in check. In these environments, every watt saved translates to less cooling required and lower operational costs, making our high-density, low-power approach an ideal choice. Another critical benefit to running a lean and efficient platform for a record run is protecting the entire setup with battery backup hardware. As mentioned earlier, you would need battery backups for compute servers, switching, storage servers, chillers, and water pumps to keep it alive for a good chunk of the year.
Overall, this record-breaking achievement showcases the potential of current HPC technologies and underscores the importance of energy efficiency and thermal management in modern computing environments.
Ensuring Accuracy: The Bailey–Borwein–Plouffe Formula
Calculating pi to 202 trillion digits is a monumental task, but ensuring the accuracy of those digits is equally crucial. This is where the Bailey–Borwein–Plouffe (BBP) formula comes into play.
The BBP formula allows us to verify pi’s binary digits in hexadecimal (base 16) format without needing to compute all preceding digits. This is particularly useful for cross-checking sections of our massive calculation.
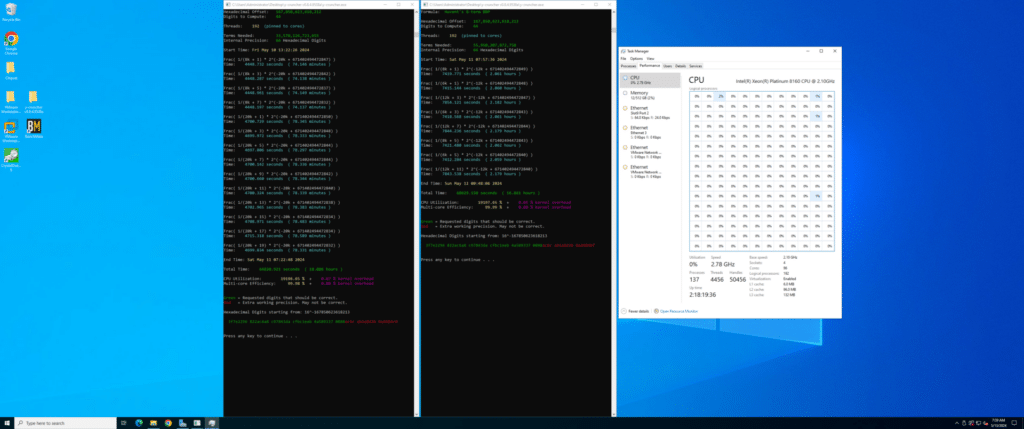
Two of the verification computations.
Here’s a simplified explanation:
- Hexadecimal Output: We first generate pi’s digits in hexadecimal during the main calculation. The BBP formula can compute any arbitrary individual digit of pi in base 16 directly. You can do this with other programs like GPUPI, but y-cruncher also has a built-in function. If you prefer an open-source approach, the formulas are well-known.
- Cross-Verification: We can compare these results with our main calculation by calculating specific positions of pi’s hexadecimal digits independently with the BBP formula. If they match, it strongly indicates that our entire sequence is correct. We did this cross-check over six times; here are two of them.
For instance, if our primary calculation produces the same hexadecimal digits as those obtained from the BBP formula at various points, we can confidently assert the accuracy of our digits. This method is not just theoretical; it’s been practically applied in all significant pi calculations, ensuring robustness and reliability in results.
R= Official Run Result, V= Verification Result
- R: f3f7e2296 822ac6a8c9 7843dacfbc 1eeb4a5893 37088*
- V: *3f7e2296 822ac6a8c9 7843dacfbc 1eeb4a5893 370888
Astute readers will note that the verifications from the screenshots and the above comparison are a bit shifted(*). While not necessary, since the hex would be affected at the end, we also spot-checked a few other locations (like 100 Trillion and 105 Trillion digits) to ensure the run matched. While it is theoretically possible to calculate any decimal digit of pi using a similar method, it is unclear if that would have precision past a mere 100 Million digits or be even computationally efficient to do so, rather than do the Chudnovsky math and get all of them. (If Eric Weisstein sees this, reach out; I’d like to take a stab at it.)
By integrating this mathematical cross-checking process, we can assure the integrity of our record-breaking 202 trillion digit pi computation, demonstrating our computational precision and commitment to scientific accuracy.
The Road Ahead
The achievement of calculating pi to over 202 trillion digits by the StorageReview Lab Team is a testament to the remarkable advancements in high-performance computing and storage technology. This record-breaking feat, utilizing Intel Xeon 8592+ CPUs in our Dell PowerEdge R760 and Solidigm 61.44TB QLC NVMe SSDs, highlights the capabilities of modern hardware to handle complex and resource-intensive tasks with unprecedented efficiency. The project’s success not only showcases the prowess of the StorageReview team but also underscores the potential of today’s HPC infrastructure to push the boundaries of computational mathematics and other scientific disciplines.
“This new Pi world record is an exciting accomplishment because this computational workload is as intense as many of the AI workloads we are seeing today. Solidigm D5-P5336 61.44TB SSDs have proven, yet again, that the powerful combination of ultra-high capacity, PCIe 4 saturating read performance and high Petabytes written, can withstand and unleash some of today’s most demanding applications,” said Greg Matson, VP, Solidigm’s Data Center Storage Group. “We are thrilled to have had the opportunity to enable another record-breaking attempt to calculate Pi with our partners at Dell Technologies and the experts at StorageReview.”
This endeavor also offers valuable insights into optimizing storage density and energy efficiency, paving the way for more sustainable and manageable computing solutions. As we continue to explore the possibilities of HPC, the lessons learned from this project will undoubtedly drive future innovations, benefiting various fields, from cryptography to engineering. The StorageReview Lab Team’s achievement stands as a landmark in computational history, demonstrating that we can reach new heights of scientific discovery and technological advancement with the right combination of hardware and expertise.
Acknowledgments
The StorageReview Lab Team thanks Solidigm, Dell Technologies, Intel, and y-cruncher Alex Yee for their unwavering support and contributions to this project.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed