

The Comino Grando H100 Server offers 2x NVIDIA H100 GPUs, liquid cooling, and AMD Threadripper PRO 7995WX, designed for AI and HPC workloads.
The Comino Grando H100 Server is the latest release in the company’s lineup. It caters to users who need power with refined, liquid-cooled precision. This Grando configuration introduces different hardware and design enhancements. However, it is still well-suited for high-demand applications, from AI and machine learning to complex data analytics and visual rendering.

In our new H100 configuration, Comino has chosen a powerhouse CPU: the AMD Ryzen Threadripper PRO 7995WX, which is a standout for high-core, high-thread computing tasks.

This 96-core CPU is ideal for parallelized processing, where users may run extensive datasets or handle multi-threaded applications that thrive on more cores and threads. The ASUS SAGE WRX90 motherboard complements this CPU and provides the architecture to support the H100’s enhanced memory and connectivity needs.
Comino Grando H100: Processor and Memory options
With 96 cores/192 threads, Zen 4 architecture, and advanced 5nm technology, it’s built to easily tackle tasks like 3D rendering, video editing, and complex simulations. It features a base clock of 2.5 GHz (boosting up to 5.1 GHz), making it ideal for multi-threaded and single-threaded tasks. It supports up to 2TB of DDR5 memory across eight channels, providing massive bandwidth for massive datasets. Moreover, its compatibility with the WRX90 platform means ample PCIe Gen5 lanes for high-speed storage and GPU setups.

The GPU setup in this Grando model features two NVIDIA H100 NVL GPUs boasting 94GB of memory each. This dual-GPU configuration delivers an impressive 188GB of GPU memory, enhancing performance for demanding applications. It is especially beneficial for professionals in artificial intelligence, 3D rendering, and scientific simulations, where GPU memory limitations can impact productivity. The Grando model is an excellent choice for those needing powerful computing resources to handle large datasets and complex tasks efficiently. And thanks to Comino’s liquid cooling, these high-power GPUs can operate in a single-slot form factor, achieving densities that traditional air-cooled systems can’t match.
NVIDIA H100 NVL GPU Specifications
| FP64 | 30 teraFLOPs |
| FP64 Tensor Core | 60 teraFLOPs |
| FP32 | 60 teraFLOPs |
| TF32 Tensor Core* | 835 teraFLOPs |
| BFLOAT16 Tensor Core* | 1,671 teraFLOPS |
| FP16 Tensor Core* | 1,671 teraFLOPS |
| FP8 Tensor Core* | 3,341 teraFLOPS |
| INT8 Tensor Core* | 3,341 TOPS |
| GPU Memory | 94GB |
| GPU Memory Bandwidth | 3.9TB/s |
| Decoders | 7 NVDEC 7 JPEG |
| Max Thermal Design Power (TDP) | 350-400W (configurable) |
| Multi-Instance GPUs | Up to 7 MIGS @ 12GB each |
| Form Factor | PCIe dual-slot air-cooled |
| Interconnect | NVIDIA NVLink: 600GB/s PCIe Gen5: 128GB/s |
| Server Options | Partner and NVIDIA-Certified Systems with 1–8 GPUs |
| NVIDIA AI Enterprise | Included |
Users can choose between high-speed desktop-grade memory with Kingston Fury (ideal for tasks with lower latency) or a larger 512GB capacity with Kingston Server Premier for enterprise-grade reliability and higher memory-intensive workloads.
Comino Grando H100: Cooling and Power
As with previous Grando iterations, the design philosophy here is as much about practicality as it is about performance. Its advanced internal cooling system features a custom-built water block setup that keeps all components cool, even under heavy workloads.

This liquid-cooling system ensures GPUs maintain peak performance without thermal throttling while reducing noise levels. Unlike conventional server builds that rely on large, noisy fans, the Grando’s liquid-cooling solution is efficient and well-designed. The cooling architecture includes a centralized water distribution block with dripless quick-disconnect fittings, allowing easy servicing with minimal risk of leaks or spills.

With four separate 1600W PSUs, the Grando H100 can maintain uptime even with a power supply failure, a feature critical for enterprise environments where downtime needs to be avoided at all costs. These power supplies work together seamlessly to ensure consistent power delivery, even under extreme loads from the 7995WX and dual H100 GPUs.
Comino Grando H100: Design and Build
Beyond power and cooling, the Comino Grando H100’s layout is organized to provide easy access to critical components. We’ve reviewed the design and build in detail in our previous Comino Grando Review, so we’ll cover the highlights.

The front panel has a comprehensive I/O array, including audio jacks, multiple USB ports, and network connectivity options, making it suitable for rack-mounted environments and standalone use. The built-in LED display is more than just a decorative touch. It delivers real-time telemetry data, including air and coolant temperatures, fan speeds, and pump status.
The backlit menu buttons make it easy for users to navigate through this information. They also allow access to deeper settings and diagnostics for monitoring and adjustments, enhancing usability and convenience for regular maintenance.
Inside, each component is arranged to prevent movement during transit, with additional bracing around sensitive parts like the GPUs and SSDs. This reflects Grando’s dedication to ensuring their servers are durable and safely delivered.

The Comino server is also easy to maintain and service. The cables, tubes, and components are very nicely routed, giving the interior a clean, almost modular appearance. This also plays a practical role in airflow and maintenance ease, making it easier to isolate and address any component without disrupting the rest of the setup.
Comino Grando Server H100 Performance
Now, we’ll delve into how these build choices impact real-world performance. We’ll compare this setup against the two Comino Grando models we reviewed earlier this year and discuss specific benchmarks in computational and graphical tasks. We’ll also compare it to the Supermicro AS-2115HV-TNRT.
Tested Systems
Our Grando Server H100 build features the AMD Threadripper PRO 7995WX processor, which provides 96 cores and 192 threads, making it the most core-dense CPU in this lineup. The system is powered by 512GB of Kingston Server Premier DDR5 memory, designed for high-bandwidth workloads and intensive multitasking. The GPU setup includes two NVIDIA H100 NVL GPUs with 94GB of memory each.

The Supermicro AS-2115HV-TNRT system uses the same AMD Threadripper PRO 7995WX but includes 520GB of DDR5-4800 ECC memory and four NVIDIA RTX 6000 Ada GPUs. These GPUs are oriented towards high-end graphical rendering and professional visualization tasks. The Supermicro system also has a Micron 7450 Max 3.2TB NVMe.
The Grando Server we reviewed earlier this year featured the AMD Threadripper PRO 5995WX processor, a 64-core, 128-thread CPU, alongside 512GB of RAM and six NVIDIA RTX 4090 GPUs. This configuration focused heavily on graphical performance, with the RTX 4090s delivering high throughput for rendering and general-purpose GPU workloads. The system also included 4x 1600W PSUs and a 2TB NVMe SSD.
The other Comino system is the 3975W-powered Grando Workstation, which offers 32 cores and 64 threads. Its GPU configuration consists of four NVIDIA A100 GPUs, emphasizing a balance between compute-focused workloads and visualization tasks. It was paired with 512GB of RAM and a 2TB NVMe SSD, making it less computationally dense than the newer systems but capable of handling demanding workflows.
It’s important to note that the previous Grando Server we reviewed will likely deliver superior performance in GPU-focused benchmarks, particularly those related to rendering and visualization tasks. The RTX 4090 GPUs are designed for high-end graphical workloads, providing substantial computational power for such applications.
The Nvidia H100 GPUs are purpose-built compute accelerators that deliberately omit display outputs and consumer features, making them purely focused on data center workloads. Unlike their Consumer and Workstation counterparts, H100s don’t include display ports or Windows graphics drivers since they’re designed for headless server operation. The absence of NVENC encoding hardware further emphasizes their compute-only nature, optimizing die space for AI and HPC tasks rather than media encoding.
Benchmark Results
Blender 4.0
Our first benchmark is Blender–a comprehensive open-source 3D creation suite for modeling, animation, simulation, and rendering projects. Blender benchmarks evaluate a system’s performance in rendering complex scenes, a crucial aspect for professionals in visual effects, animation, and game development. This benchmark measures CPU and GPU rendering capabilities, which are relevant for servers and workstations designed for high-end graphics processing and computational tasks.
Here, the Grando H100 Server configuration excels in CPU-based tests due to the high core count of the AMD Threadripper PRO 7995WX. It consistently outpaces the other systems like the Supermicro AS-2115HV-TNRT in rendering tasks like Monster, Junkshop, and Classroom scenes. However, the GPU tests reveal the limitations of the H100 GPUs in graphics-rendering workloads. While the H100 configuration delivers decent results, systems with more general-purpose GPUs perform significantly better, like the RTX 6000 Ada or RTX 4090. This highlights the H100’s specialization in computational rather than graphical tasks.
| Blender (Samples per minute; Higher is better) |
Grando Server (AMD 7995WX, 2x H100) |
Supermicro AS-2115HV-TNRT (AMD 7995WX, 4x RTX 6000 Ada) | Supermicro AS-2115HV-TNRT Overclocked (AMD 7995WX, 4x RTX 6000 Ada) |
| Blender 4.2 CPU Tests | |||
| Monster | 1,352.19 | 931 | 969 |
| Junkshop | 969.44 | 682 | 640 |
| Classroom | 683.30 | 451 | 472 |
| Blender 4.2 GPU Tests | |||
| Monster | 2,521 | 5,745 | N/A |
| Junkshop | 1,888.28 | 2,698 | N/A |
| Classroom | 1,401.96 | 2,824 | N/A |
The previously reviewed Grando servers were tested under Blender version 4.0. Here are the results:
| Blender (Samples per minute; Higher is better) |
Grando Server (TR W5995WX, 512GB, 6x 4090) |
Grando Workstation (TR 3975WX, 512GB, 4x A100) |
| Blender 4.0 CPU Tests | ||
| Monster | 568.02 | 334.40 |
| Junkshop | 386.53 | 231.90 |
| Classroom | 293.91 | 174.21 |
| Blender 4.0 GPU Tests | ||
| Monster | 5,880.71 | 1,656.34 |
| Junkshop | 2,809.36 | 1,137.73 |
| Classroom | 2,895.54 | 953.46 |
Blackmagic RAW Speed Test
The Blackmagic RAW Speed Test measures the processing speed for high-quality video formats, an essential aspect for servers and workstations in video production and editing. It evaluates how systems manage RAW video files, affecting workflow efficiency and productivity in media production environments.
In the Blackmagic RAW Speed Test, the Grando Server H100 demonstrates strong CPU performance in 8K RAW video decoding but falls short in CUDA-based activities as the smaller T1000 handled that in this system. Systems with GPUs like the RTX 4090 and RTX 6000 Ada offer DirectX support in Windows, whereas the enterprise-focused GPUs don’t have that support natively.
| Blackmagic RAW Speed Test | Grando Server (AMD 7995WX, 2x H100) |
Grando Server (TR W5995WX, 512GB, 6x 4090) |
Grando Workstation (TR 3975WX, 512GB, 4x A100) |
Supermicro AS-2115HV-TNRT (AMD 7995WX, 4x RTX 6000 Ada) |
| 8K CPU | 156 FPS | 132 FPS | 135 FPS | 132 fps |
| 8K CUDA | 144 FPS | 345 FPS | 309 FPS | 664 fps |
7-zip Compression
The 7-zip Compression benchmark tests a system’s efficiency in handling data compression and decompression, which is crucial for managing large datasets and optimizing storage. This benchmark reflects the performance of servers and workstations in data-intensive operations, where speed and efficiency in data manipulation are vital.
Here, the Grando Servers delivered the best compression and decompression results among the systems tested. However, in overall efficiency, the overclocked Supermicro AS-2115HV-TNRT configuration comes close.
| 7-Zip Compression Benchmark (Higher is better) | Grando Server (AMD 7995WX, 2x H100) |
Grando Server (TR W5995WX, 512GB, 6x 4090) |
Grando Workstation (TR 3975WX, 512GB, 4x A100) |
Supermicro AS-2115HV-TNRT (AMD 7995WX, 4x RTX 6000 Ada) |
Supermicro AS-2115HV-TNRT – Overclocked (AMD 7995WX, 4x RTX 6000 Ada) |
| Compressing | |||||
| Current CPU Usage | 5,582% | 3,379% | 3,439% | 5,571% | 6,456% |
| Current Rating/Usage | 8.627 GIPS | 7.630 GIPS | 7.094 GIPS | 7.835 GIPS | 9.373 GIPS |
| Current Rating | 481.539 GIPS | 257.832 GIPS | 243.994 GIPS | 436.490 GIPS | 605.097 GIPS |
| Resulting CPU Usage | 5,561% | 3,362% | 3,406% | 5,599% | 6,433% |
| Resulting Rating/Usage | 8.631 GIPS | 7.697 GIPS | 7.264 GIPS | 7.863 GIPS | 9.420 GIPS |
| Resulting Rating | 480.006 GIPS | 258.756 GIPS | 247.396 GIPS | 440.288 GIPS | 605.984 GIPS |
| Decompressing | |||||
| Current CPU Usage | 6,270% | 6,015% | 6,286% | 6,223% | 6,343% |
| Current Rating/Usage | 7.411 GIPS | 5.585 GIPS | 5.434 GIPS | 7.215 GIPS | 9.810 GIPS |
| Current Rating | 464.701 GIPS | 335.958 GIPS | 341.599 GIPS | 449.012 GIPS | 622.250 GIPS |
| Resulting CPU Usage | 6,238% | 6,053% | 6,269% | 6,213% | 6,312% |
| Resulting Rating/Usage | 7.589 GIPS | 5.603 GIPS | 5.468 GIPS | 7.165 GIPS | 9.834 GIPS |
| Resulting Rating | 473.375 GIPS | 339.171 GIPS | 342.766 GIPS | 445.130 GIPS | 620.749 GIPS |
| Total Ratings | |||||
| Total CPU Usage | 5,900% | 4,708% | 4,837% | 5,906% | 6,373% |
| Total Rating/Usage | 8.110 GIPS | 6.650 GIPS | 6.366 GIPS | 7.514 GIPS | 9.627 GIPS |
| Total Rating | 476.690 GIPS | 298.963 GIPS | 295.081 GIPS | 442.709 GIPS | 613.366 GIPS |
Y-Cruncher
Y-Cruncher is a computational benchmark that tests a system’s ability to handle complex mathematical operations, precisely calculating Pi to trillions of digits. This benchmark indicates the computational power of servers and workstations, particularly for use in scientific research and simulations requiring intensive number-crunching.
In Y-Cruncher, the Grando Server H100 configuration excels in total computation time for calculating Pi across all digit levels. The AMD Threadripper PRO 7995WX’s high core count ensures this system leads in CPU-intensive tasks. However, the overclocked Supermicro AS-2115HV-TNRT configuration narrows the gap significantly, showcasing the benefits of optimized performance tuning for these workloads.
| Y-Cruncher (Total Computation Time) | Grando Server (AMD 7995WX, 2x H100) |
Grando Server (TR W5995WX, 512GB, 6x 4090) |
Grando Workstation (TR 3975WX, 512GB, 4x A100) |
Supermicro AS-2115HV-TNRT (AMD 7995WX, 4x RTX 6000 Ada) | Supermicro AS-2115HV-TNRT – Overlocked (AMD 7995WX, 4x RTX 6000 Ada) |
| 1 Billion Digits | 7.523 Seconds | 11.023 Seconds | 11.759 Seconds | 8.547 seconds | 6.009 seconds |
| 2.5 Billion Digits | 15.392 Seconds | 28.693 Seconds | 32.073 Seconds | 17.493 seconds | 13.838 seconds |
| 5 Billion Digits | 29.420 Seconds | 61.786 Seconds | 69.869 Seconds | 33.584 seconds | 27.184 seconds |
| 10 Billion Digits | 60.089 Seconds | 130.547 Seconds | 151.820 Seconds | 67.849 seconds | 58.283 seconds |
| 25 Billion Digits | 214.246 Seconds | 353.858 Seconds | 425.824 Seconds | 182.880 seconds | 161.913 seconds |
| 50 Billion Digits | 594.939 Seconds | 788.912 Seconds | 971.086 Seconds | 417.853 seconds | N/A |
y-cruncher BBP
This y-cruncher benchmark utilizes the Bailey-Borwein-Plouffe (BBP) formulas to compute massive hexadecimal digits of Pi, measuring the CPU’s total computation time, utilization, and multi-core efficiency.
The y-cruncher BBP benchmark highlights the Grando Server H100’s efficiency in handling massive computational tasks. Across all tests, the Grando Server performs well, achieving the fastest total computation time for 1 BBP and 10 BBP calculations. Its multi-core efficiency in the 100 BBP test, at 98.68%, is slightly lower than the Supermicro AS-2115HV-TNRT systems but still highly effective. The overclocked Supermicro configuration outpaces the standard Supermicro in total time for all BBP levels. Still, the Grando H100 consistently leads in real-world computation speed for smaller BBP tasks, likely due to its optimized multi-threading capabilities and rapid context switching.
However, regarding CPU utilization, the Supermicro systems demonstrate slightly better core usage efficiency, indicating they may leverage their architecture more effectively for sustained parallel workloads.
| Benchmark | Grando Server (AMD 7995WX, 2x H100) |
Supermicro AS-2115HV-TNRT (AMD 7995WX, 4x RTX 6000 Ada) |
Supermicro AS-2115HV-TNRT – Overlocked (AMD 7995WX, 4x RTX 6000 Ada) |
| 1 BBP |
|
|
|
| 10 BBP |
|
|
|
| 100 BBP |
|
|
|
Geekbench 6
Geekbench 6 measures the computational performance of CPUs and GPUs, spanning single-core and multi-core capabilities and graphical processing power. This benchmark is essential for assessing the overall computing efficiency of servers and workstations across various tasks, including simulations, data analysis, and graphics rendering.
The Geekbench 6 results demonstrate that the Grando Server H100 is a top-tier performer in multi-core CPU tasks, thanks to its 96-core processor. However, in GPU scores, the H100 configuration outpaces the Supermicro AS-2115HV-TNRT, which leverages the RTX 6000 Ada GPUs for superior graphical performance.
| Geekbench 6 (Higher is Better) | Grando Server (AMD 7995WX, 2x H100) |
Grando Server (TR W5995WX, 512GB, 6x 4090) | Grando Workstation (TR 3975WX, 512GB, 4x A100) | Supermicro AS-2115HV-TNRT (AMD 7995WX, 4x RTX 6000 Ada) |
| CPU Single-Core | 2,893 | 2,127 | 2,131 | 2,875 |
| CPU Multi-Core | 28,600 | 21,621 | 20,411 | 24,985 |
| GPU | 298,220 | 294,894 | 193,447 | 307,510 |
Cinebench R23
Cinebench R23 measures the CPU’s rendering capability, focusing on single-core and multi-core performance. It’s an essential benchmark for evaluating how well a server or workstation can perform in content creation, 3D rendering, and other CPU-intensive tasks. The MP Ratio (multi-core performance ratio) further provides insight into how effectively a system utilizes its multiple cores.
The H100 configuration leads in multi-core performance, leveraging the Threadripper PRO 7995WX’s massive core count. However, its single-core performance is on par with the other systems. The MP Ratio emphasizes the 7995WX’s scalability in multi-threaded applications. Still, this benchmark’s GPU-agnostic nature prevents the H100 configuration from showing any GPU-related limitations, making it appear more competitive across the board.
| Cinebench R23 (Higher is Better) |
Grando Server (AMD 7995WX, 2x H100) |
Grando Server (TR W5995WX, 512GB, 6x 4090) | Grando Workstation (TR 3975WX, 512GB, 4x A100) | Supermicro AS-2115HV-TNRT (AMD 7995WX, 4x RTX 6000 Ada) | Supermicro AS-2115HV-TNRT – Overlocked (AMD 7995WX, 4x RTX 6000 Ada) |
| CPU Multi-Core | 159,930 pts | 73,556 pts | 49,534 pts | 111,792 pts | 132,044 points |
| CPU Single-Core | 1,876 pts | 1,484 pts | 1,468 pts | 1,864 points | 1,887 points |
| MP Ratio | 85.26 x | 49.56x | 33.75x | 59.98x | 69.99x |
GPU Direct Storage
One of the tests we conducted on this server was the Magnum IO GPU Direct Storage (GDS) test. GDS is a feature developed by NVIDIA that allows GPUs to bypass the CPU when accessing data stored on NVMe drives or other high-speed storage devices. Instead of routing data through the CPU and system memory, GDS enables direct communication between the GPU and the storage device, significantly reducing latency and improving data throughput.
How GPU Direct Storage Works
Traditionally, when a GPU processes data stored on an NVMe drive, the data must first travel through the CPU and system memory before reaching the GPU. This process introduces bottlenecks, as the CPU becomes a middleman, adding latency and consuming valuable system resources. GPU Direct Storage eliminates this inefficiency by enabling the GPU to access data directly from the storage device via the PCIe bus. This direct path reduces the overhead associated with data movement, allowing faster and more efficient data transfers.
AI workloads, especially those involving deep learning, are highly data-intensive. Training large neural networks usually requires processing terabytes of data, and any delay in data transfer can lead to underutilized GPUs and longer training times. GPU Direct Storage addresses this challenge by ensuring that data is delivered to the GPU as quickly as possible, minimizing idle time and maximizing computational efficiency.
In addition, GDS is particularly beneficial for workloads that involve streaming large datasets, such as video processing, natural language processing, or real-time inference. By reducing the reliance on the CPU, GDS accelerates data movement and frees up CPU resources for other tasks, further enhancing overall system performance.

We thoroughly tested the server by conducting an extensive GDSIO evaluation on the Comino Grando, exploring various configurations to assess its performance across different scenarios. This type of testing is crucial for a server of this caliber, as it simulates workstation-like environments and provides insights into its capabilities during ablative tests for training large models. For storage, we leveraged a Solidigm D7-PS1010 Gen5 SSD.
Testing Configuration Matrix
We systematically tested every combination of the following parameters:
- Block Sizes: 1M, 128K, 64K, 16K, 8K
- Thread Counts: 128, 64, 32, 16, 8, 4, 1
- Job Counts: 16, 8, 4, 1
- Batch Sizes: 32, 16, 8, 4, 1
For this review, we focused on sequential read and write throughput. We performed each GDSIO workload at its given block size and thread count across multiple job and batch sizes. The reported figures are the averages of each job and batch count combination.
Performance Analysis
AI workloads, particularly in the training phase, require efficient processing of massive amounts of data. These workloads typically benefit from large block sizes that can maximize throughput when reading training datasets or writing model checkpoints. In our comprehensive GPU Direct Storage capabilities tests, we focused on various I/O patterns and configurations to understand the system’s performance characteristics.
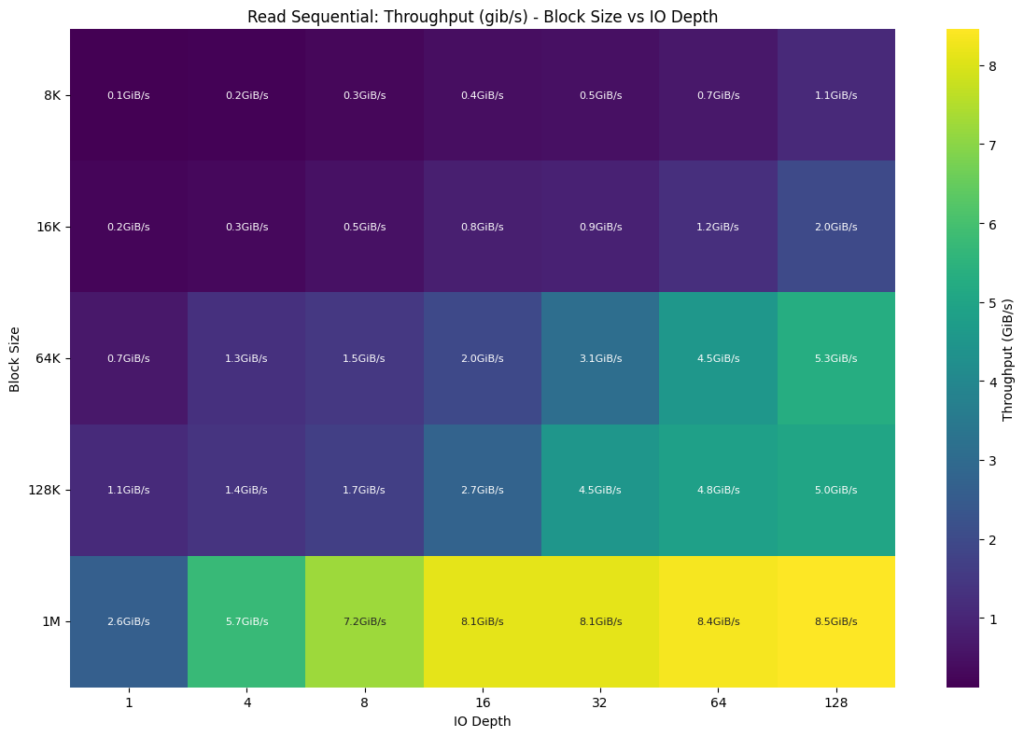
The sequential I/O performance with 1M block sizes demonstrated impressive results among our testing configurations. The system achieved a remarkable sequential read throughput of 8.56 GiB/s (1M block size, batch size 4, IO depth 128, and 128 threads across 16 jobs). This level of performance is particularly beneficial for workloads that involve loading large pre-trained models, processing extensive datasets during training phases, or handling sequential data streams such as video processing for computer vision applications.
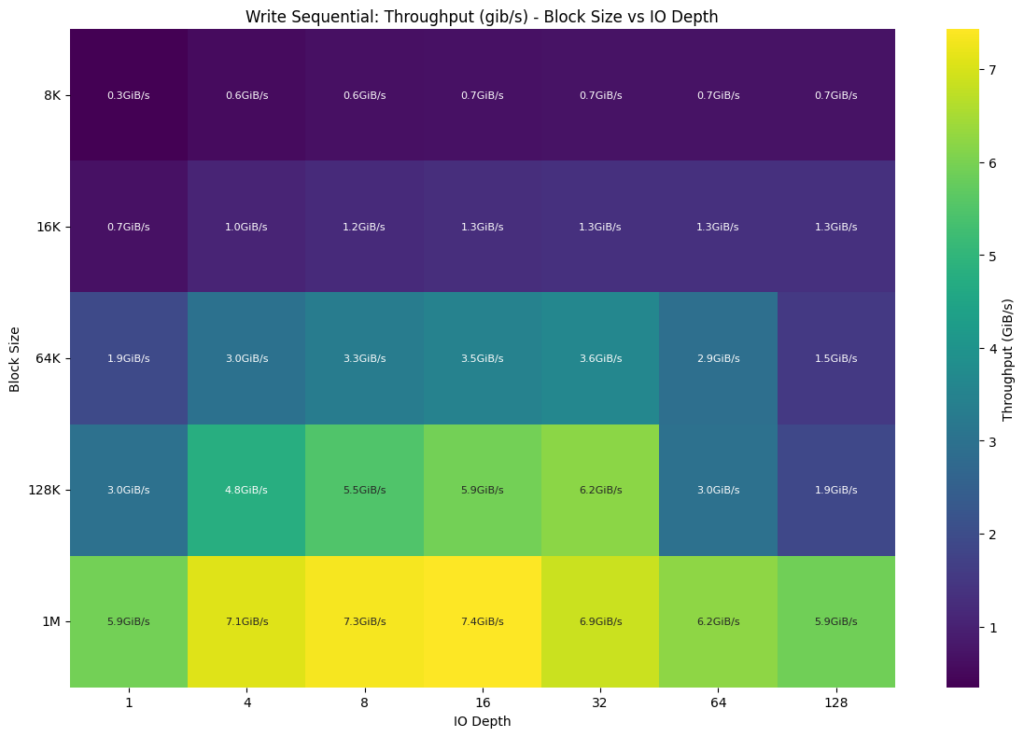
For sequential write operations, the system delivered 7.57 GiB/s (1M block size, batch size 8, IO depth 16, with 16 threads across 8 jobs), making it highly effective for scenarios requiring frequent model checkpointing during distributed training, saving intermediate results, or writing processed data in batch operations.
Conclusion
The Comino Grando H100 server is an impressive addition to the company’s lineup, offering a unique alternative to their other configurations. Powered by an AMD Threadripper PRO 7995WX CPU and 512GB of DDR5 memory, expandable up to 1TB, the Grando system is highlighted by two NVIDIA H100 NVL GPUs. While this setup provides exceptional performance for AI-driven workflows, it does come at the cost of GPU performance in traditional rendering benchmarks (such as Luxmark and OctaneBench), where systems like the RTX 4090-equipped Grando Server and RTX 6000 Ada-powered Supermicro configurations lead. That said, the H100’s performance in CPU-intensive tests such as Blender’s multi-core rendering, 7-Zip compression, and Y-Cruncher consistently outperforms the other tested systems.
Regarding design, the Comino Grando H100 Server can accommodate high-performance components in a compact form factor, something that’s often a challenge for standard chassis. Thanks to its custom Direct Liquid Cooling (DLC) system, the server can easily handle configurations like dual NVIDIA H100 GPUs. This advanced cooling solution keeps heat in check and ensures the system remains stable during demanding, high-performance tasks. What’s particularly unique about this new Comino system is how it manages to leverage mainly consumer-grade hardware to create a solution that’s both efficient and relatively affordable, making it a compelling option for professionals and enterprises looking to maximize GPU power without breaking the bank.
Overall, the Comino Grando H100 is an excellent choice for enterprises and professionals prioritizing AI optimization, computational tasks, and reliability in demanding environments. Its unique design and cooling innovations offer flexibility and performance for AI-driven workloads. However, alternative configurations like the RTX 4090-equipped Grando Server or RTX 6000 Ada-powered systems may be more suitable for users focused on traditional GPU rendering.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed