

Optimize LLM inference with Pliops and vLLM. Enhance performance, reduce costs, and scale AI workloads with KV cache acceleration.
Pliops has announced a strategic partnership with the vLLM Production Stack, an open-source, cluster-wide reference implementation designed to optimize large language model (LLM) inference workloads. This partnership is pivotal as the AI community prepares to gather at the GTC 2025 conference. By combining Pliops’ advanced key-value (KV) storage backend with the robust architecture of the vLLM Production Stack, the collaboration sets a new benchmark for AI performance, efficiency, and scalability.
Junchen Jiang, Head of the LMCache Lab at the University of Chicago, highlighted the collaboration’s potential, underscoring its ability to enhance LLM inference efficiency and performance. The joint solution brings advanced Vector Search and Retrieval capabilities by introducing a new petabyte-scale memory tier below High Bandwidth Memory (HBM). Computed KV caches are efficiently retained and retrieved using disaggregated smart storage, accelerating vLLM inference.
For a primer on Pliops, check out our deep dive article.
About that KVCache
Most large language models use transformer architectures, which rely on attention mechanisms involving Query, Key, and Value matrices. When generating tokens sequentially, transformers repeatedly compute attention, requiring the recalculation of previous Key and Value (KV) matrices, leading to increased computational cost. KV caching addresses this by storing previously computed KV matrices, allowing reuse in subsequent token predictions, significantly improving generation efficiency and throughput.
However, this introduces new challenges. KV caches can become quite large, particularly during lengthy generations or batched inference with typical batch sizes of 32, eventually exceeding available memory. To address this limitation, a KV cache storage backend becomes essential.
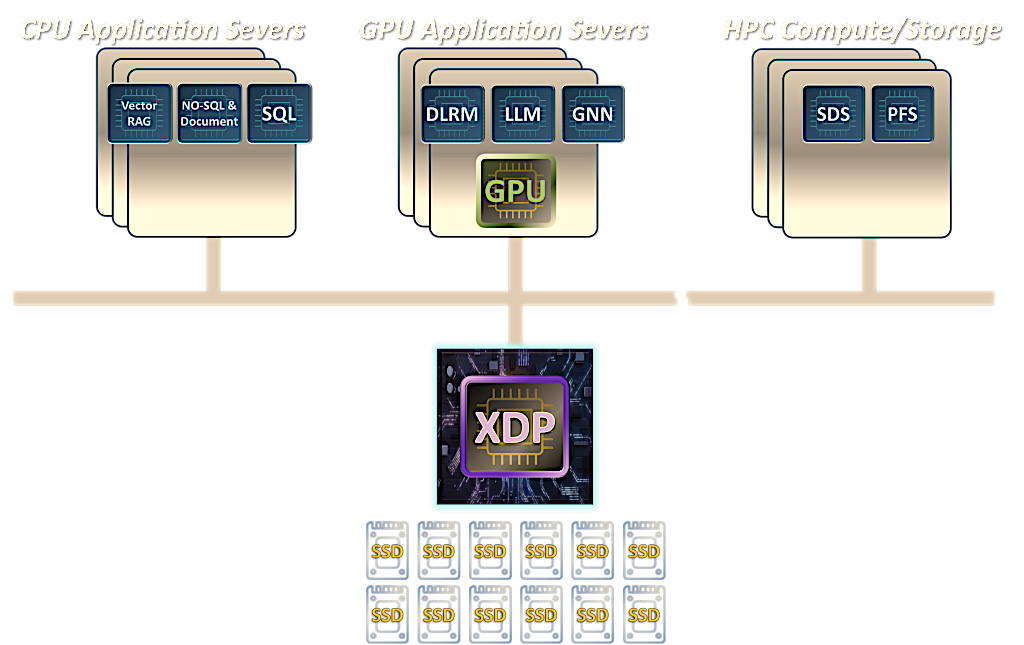
Pliops XDP LightningAI
Deploying Pliops’ XDP LightningAI in data centers represents a paradigm shift in cost-effectiveness, providing substantial cost savings compared to traditional architectures. By adding dedicated XDP LightningAI servers alongside existing infrastructure, organizations can achieve remarkable savings, including a 67% optimization in rack space, a 66% reduction in power consumption, a 58% annual OpEx savings, and a 69% decrease in initial investment costs.
Pliops continues to advance with its Extreme Data Processor (XDP), the XDP-PRO ASIC, complemented by a comprehensive AI software stack and distributed nodes. Utilizing a GPU-initiated Key-Value I/O interface, this solution enables unprecedented scalability and performance. Pliops’ XDP LightningAI delivers substantial end-to-end performance improvements, achieving up to 8X gains for vLLM inference, significantly accelerating Generative AI (GenAI) workloads. With the integration of cutting-edge industry trends such as DeepSeek, Pliops ensures robust adaptability for future AI developments.
Pliops showcased these advancements at AI DevWorld, highlighting how XDP LightningAI revolutionizes LLM performance by significantly reducing computational power and cost. This demonstration illustrated Pliops’ commitment to enabling enterprise-scale sustainable AI innovation.
Ongoing Collaboration
Pliops positions organizations to maximize the potential of AI-driven insights and maintain a competitive advantage in a rapidly evolving technology landscape by providing instant access to actionable data and ensuring a seamless integration path.
The future roadmap for the collaboration includes essential integration of Pliops’ KV-IO stack into the production stack, progressing towards advanced capabilities such as prompt caching across multi-turn conversations, scalable KV-cache offloading, and streamlined routing strategies.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed