
 Datrium delivers “open convergence,” which is what they call the next generation of converged infrastructure. There may be as many riffs on convergence as there are vendors in the enterprise IT space, and for their part, Datrium isn’t shy about promoting their vision of what infrastructure can look like. Datrium’s view sees compute, primary storage, secondary storage and cloud coming together in a highly resilient configuration that is scalable and easy to manage without a silo for each class of storage. Furthermore, because most data calls will hit compute nodes with on-board flash cache, Datrium can deliver tremendous performance without having to go to the data nodes in nearly all cases. This translates to 200GB/s and 16GB/s in peak 32K read and write bandwidth and 18M IOPS 4K random read.
Datrium delivers “open convergence,” which is what they call the next generation of converged infrastructure. There may be as many riffs on convergence as there are vendors in the enterprise IT space, and for their part, Datrium isn’t shy about promoting their vision of what infrastructure can look like. Datrium’s view sees compute, primary storage, secondary storage and cloud coming together in a highly resilient configuration that is scalable and easy to manage without a silo for each class of storage. Furthermore, because most data calls will hit compute nodes with on-board flash cache, Datrium can deliver tremendous performance without having to go to the data nodes in nearly all cases. This translates to 200GB/s and 16GB/s in peak 32K read and write bandwidth and 18M IOPS 4K random read.
Datrium delivers “open convergence,” which is what they call the next generation of converged infrastructure. There may be as many riffs on convergence as there are vendors in the enterprise IT space, and for their part, Datrium isn’t shy about promoting their vision of what infrastructure can look like. Datrium’s view sees compute, primary storage, secondary storage and cloud coming together in a highly resilient configuration that is scalable and easy to manage without a silo for each class of storage. Furthermore, because most data calls will hit compute nodes with on-board flash cache, Datrium can deliver tremendous performance without having to go to the data nodes in nearly all cases. This translates to 200GB/s and 16GB/s in peak 32K read and write bandwidth and 18M IOPS 4K random read.

Fundamentally, Datrium is made of compute nodes and storage nodes that make up the DVX system. Compute nodes can be supplied by Datrium, or customers may leverage their own existing server infrastructure. Compute nodes handle IO processing, keeping a cache locally on flash. Flash can be just about anything, from lower-cost, high-capacity SATA drives, to high-performance NVMe. The decision on flash is entirely workload dependent and can be tuned to meet customer needs. Because persistent data resides on the data nodes, compute nodes are stateless and can go offline without risking data loss or corruption, maintaining n-1 availability. Datrium supports a variety of environments including vSphere 5.5-6.5, Red Hat 7.3, CentOS 7 1611, and bare metal Docker 1.2.


Data nodes maintain persistent copies of data and are available in either disk or flash configurations. Within Datrium DVX, data is always compressed, globally deduped, and erasure coded with double fault tolerance. Datrium also offers encryption, snapshots and replication within DVX. The data nodes rely on the compute nodes for all of the processing, keeping the storage system free to deliver IO via dual hot-swappable controllers. Data nodes include mirrored, battery-backed NVRAM for fast writes, and high-speed Ethernet networking with load balancing and path failover. The latest nodes by Datrium includes DVX with Flash End-to-End. This means there is flash in the compute nodes, along with all-flash DVX data nodes. The F12X2 data node has 16TB usable storage (12×1.92TB SSDs), with up to 32-96TB effective capacity with 2-6x data reduction and support for 25GbE networking. The latest compute node, CN2100, adds new Skylake CPUs, NVMe support and up to 25GbE networking.
This review is somewhat unique in that we had access to a Datrium test environment remotely, configured with 32 Dell PowerEdge C6320 compute nodes and 10 Datrium DVX all-flash data nodes.
- 32 x Dell PowerEdge C6320 Servers
- VMware ESXi 6.0 Update3 installed
- Dual Xeon CPU E5-2697 v4 CPUs
- 128GB memory
- 4 x 1.92TB Samsung PM863a SSD as data cache
- 2 x 10Gb/s NIC (management/data)
- Networking Configuration
- 10 F12X2 Data-nodes on core switch
- 32 Compute-nodes on 8 TOR switches
- Each TOR switch has 160Gbps uplink to the core switch
Management
The DVX is managed with a HTML5-based user interface via the browser, or as a VMware vCenter plug-in. The entire premise of the DVX UI relies on simplicity, removing the need to manage storage in the traditional way. Everything happens from the same UI from storage provisioning to replications management.
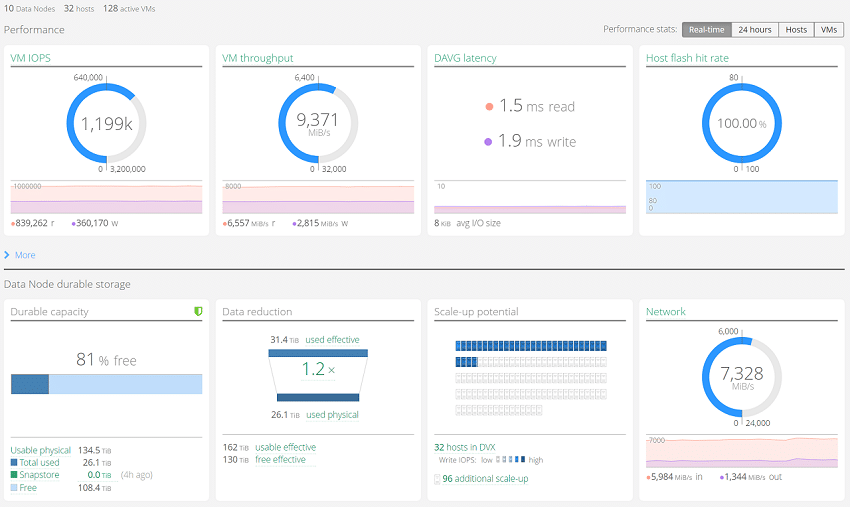
At a quick glance, users are able to find performance information regarding cluster VM IOPS, throughput, network transfer speeds, as well as Datrium average read/write latency alongside host flash hit rates. Given the tiered structure of the Datrium DVX platform, checking the performance levels between the hosts and the underlying data nodes is helpful in measuring overall performance. In addition to performance metrics, total usable capacity showing total data footprint alongside snapshot space is provided as well as current data-reduction metrics.
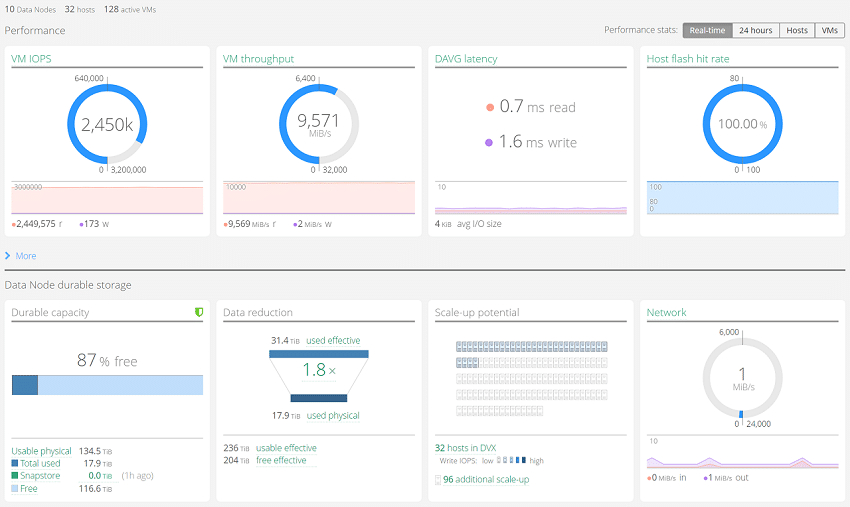
One interesting item to note in the screenshots above is the network traffic (where one shows 4K random-write activity and the other read activity). Since Datrium DVX leverages host-side flash for read activity and commits write activity down to the data-nodes, you can see that represented in network speeds. In our 4K random test, network activity was measured at 7.3GB/s, whereas in our read test where data was pulled from internal-host flash, network traffic was non-existent.
Performance Benchmarks
To measure the performance of such a large cluster, we chose HCIBench from VMware for its ease of deployment and ability to aggregate performance data across hundreds of vdbench VMs. For a large cluster, this tool allowed us to quickly ramp up workloads commonly used to measure enterprise storage, as well as allow us to work with data that has a user-defined repeating pattern. For platforms offering data-reduction services, it gives users the chance to show performance in closer to real-world situations. In this case, we used a 2:1 compression setting for each of our workloads. It should be noted for all the benchmarks, compression, deduplication and inline erasure coding were running. In other words, all benchmarks were conducted in a full real-world operating condition.
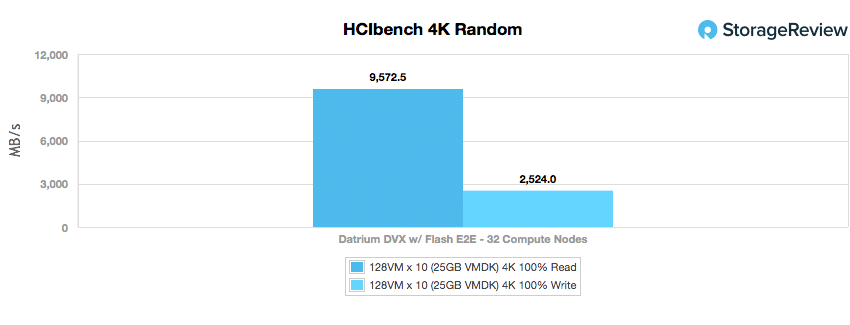
In our HCIbench 4K, we look at peak random throughput with a fully random 4K workload profile. The Datrium DVX was able to hit 9.5725GB/s read and 2.524GB/s write.
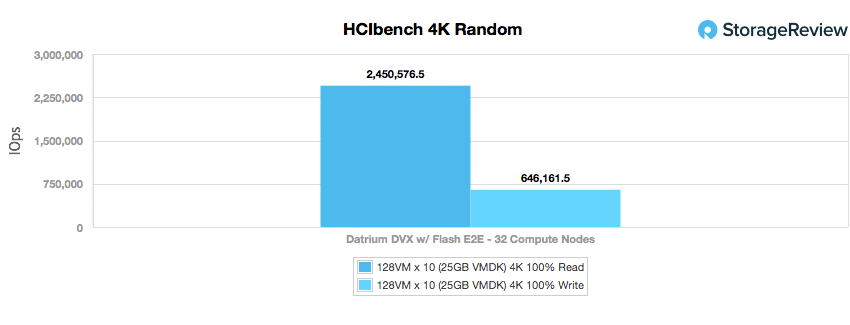
Next we look at peak I/O in the same 4K profile. Here the Datrium DVX had another impressive showing with over 2.45 million IOPS read and 646,162 IOPS write.
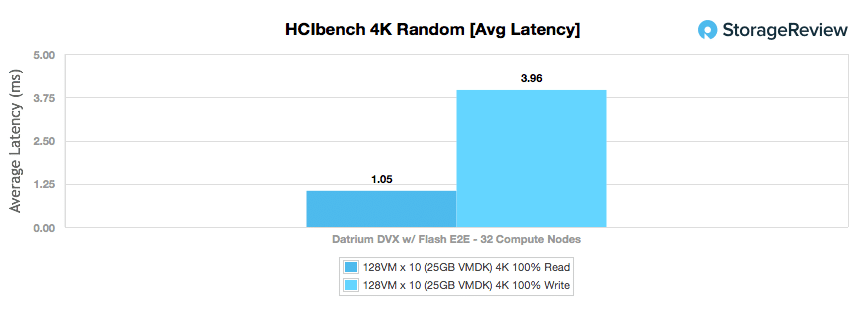
The next metric looks at the fully random 4K workload profile’s average latency. While not quite sub-millisecond latency, the DVX was still able to hit a very impressive 1.05ms read and 3.96ms write.
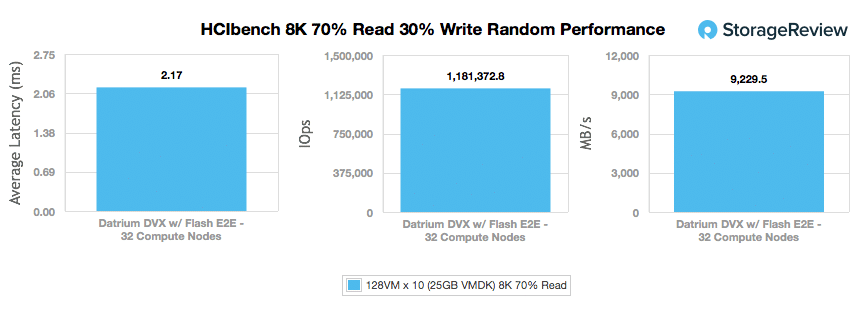
Our next test looks at a larger 8K random data profile with a mixture of 70% read and 30% write activity. The DVX’s throughput here was 9,229.5GB/s. Looking at peak I/O, the DVX was able to hit over 1.18 million IOPS. The 8K 70/30 latency came out to be only 2.17ms.
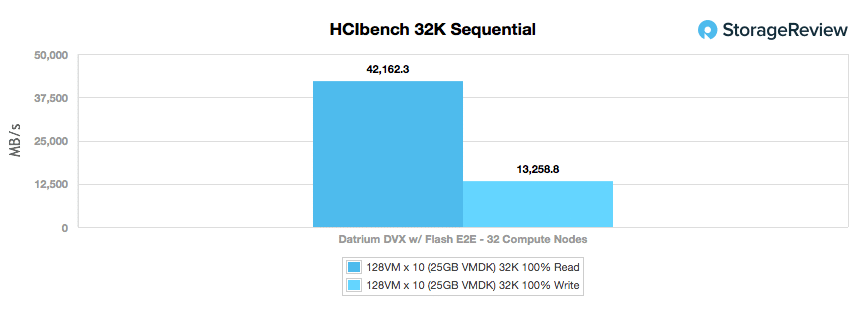
The last workload switches to a peak bandwidth focus, consisting of a 32K sequential read and write profile. Here the DVX was able to hit a massive 42.16GB/s read and 13.26GB/s write.
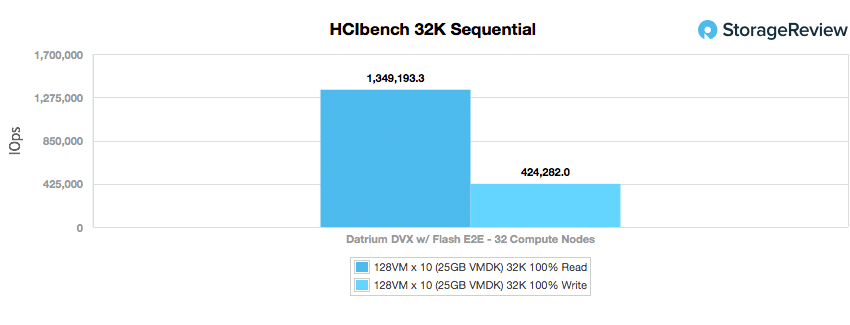
Looking at peak I/O for the same workload, the DVX continues to put up some impressive numbers with over 1.349 million IOPS read and 424,282 IOPS write.
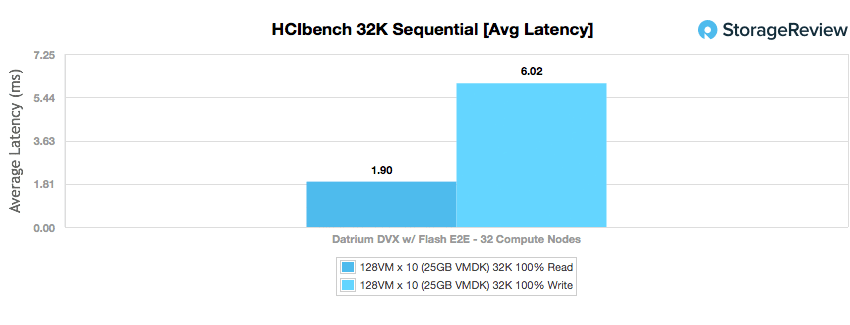
With all of the high numbers the DVX was putting up in the 32K test, it topped everything off with fairly low latency of 1.9ms read and 6.02ms write.
Being a converged platform, CPU utilization is an important factor to consider since some of the storage overhead comes out of the same systems leveraged for operating the workloads themselves. While monitoring the platform during each workload, we looked at total cluster performance (both sides of the equation), including the HCIbench workers leveraging vdbench, spread out across the cluster combined with the overhead of the storage VMs themselves.
During the heavy sequential write activity (where much of the work is offloaded directly to the flash nodes), we saw less than 40% of the total system resources used. During heavy read activity, such as in the 4K random read workload, this metric increased to just over 60%. So even with the system both serving the workload and VMs consuming the workload, we had 60% of the CPU resources left over for other applications and workloads, and worst case that dropped down to 40%. So, with Insane Mode running (40% max host utilization vs. 20% normally) in a worst case scenario with full inline data services going, the Datrium platform still had plenty of system resources left over.
Conclusion
The Datrium DVX family has been updated to support the latest generation of storage and compute resources. In this case, we took a look at the end-to-end flash configuration, which includes a flash cache in the compute nodes, along with all-flash data nodes for persistent storage. Datrium’s “open convergence” platform also includes the data services generally found on more mature products; with Datrium DVX, data is always compressed, globally deduped, and erasure coded with double fault-tolerance. Customers can opt to use Datrium’s compute nodes, but as is the case in this review, that isn’t required (our testing leveraged 32 Dell PowerEdge nodes). These compute nodes handle the IO processing and cache with minimal overhead of up to 20%. For instances demanding more storage performance, however, DVX can be put in Insane Mode where DVX can utilize up to 40% of compute resources.
On the performance side of things, we opted for HCIbench benchmarks as they would best reflect what the Datrium DVX is truly capable of doing in a larger-scale environment. Right off the bat, the all-flash DVX was putting up very impressive numbers. In 4K benchmarks, the DVX hit a throughput over 9.57GB/s and 2.45 million IOPS read and over 2.52GB/s and 646K IOPS write. The DVX pulled off these numbers with latency as low as 1.05ms read and 3.96ms write. Switching over to 8K 70% read 30% write, the DVX once again impressed with a throughput over 9.2GB/s, over 1.18 million IOPS, all with a latency of 2.17ms. On our 32K sequential test, the DVX hit an amazing 42.16GB/s read and over 1.349 million IOPS, with a latency of 1.9ms.
Clearly Datrium’s spin on convergence is a unique one. Leveraging “leftover” CPU from the compute nodes with localized flash makes a good deal of sense, while still being able to keep flash for persistent storage for all the TCO benefits. A key driver to making this work are the storage efficiencies that the DVX system offers, which are critical to getting the most out of the flash in the data nodes. For those that need even more performance, it’s easy enough to drop in NVMe storage in the compute nodes, though we clearly did very well with a lower-cost option. However, none of the performance means much without resiliency. With DVX, compute nodes are stateless and support an N-1 server failure tolerance model. That means we could lose 31 of the 32 servers in our test config and all data remains available. Even if all servers were lost, DVX will not lose data since the authoritative copy of data is stored and protected on the data nodes, not in compute nodes.
Ultimately there’s little as exciting in enterprise IT right now as converged infrastructure. While there are many ways to execute on that vision, Datrium has put together their pitch for DVX which includes deep data management services paired with an excellent performance profile. However, few in the convergence space have executed on both performance and features, making Datrium’s DVX a well-armed offering that distinctly stands out from the crowd.
Sign up for the StorageReview newsletter