
 Primary Data officially came out of stealth today, announcing preliminary details about its new platform to virtualize data throughout a datacenter environment with a single global dataspace. The new solution, currently in testing by early access partners, is an attempt to decouple storage management from the data residence by use of a policy engine that automatically places data on appropriate storage resources across file, block, and object in real time. The Primary Data Platform represents the efforts of a startup venture that has been created specifically to advance a vision for the roles and functionality for software-defined storage as part of a broader virtualized, converged datacenter infrastructure.
Primary Data officially came out of stealth today, announcing preliminary details about its new platform to virtualize data throughout a datacenter environment with a single global dataspace. The new solution, currently in testing by early access partners, is an attempt to decouple storage management from the data residence by use of a policy engine that automatically places data on appropriate storage resources across file, block, and object in real time. The Primary Data Platform represents the efforts of a startup venture that has been created specifically to advance a vision for the roles and functionality for software-defined storage as part of a broader virtualized, converged datacenter infrastructure.
Primary Data officially came out of stealth today, announcing preliminary details about its new platform to virtualize data throughout a datacenter environment with a single global dataspace. The new solution, currently in testing by early access partners, is an attempt to decouple storage management from the data residence by use of a policy engine that automatically places data on appropriate storage resources across file, block, and object in real time. The Primary Data Platform represents the efforts of a startup venture that has been created specifically to advance a vision for the roles and functionality for software-defined storage as part of a broader virtualized, converged datacenter infrastructure.
Software-defined storage and storage virtualization abstracts physical and virtual storage resources and embodies an approach that incorporates all storage across geography or performance tier including direct-attached, network-attached, private and public cloud storage. The solution includes two core components, the data director and the data hypervisor. The director manages the metadata about all of the data within the ecosystem, regardless of its location. The data director runs on a physical box that is flash-based and can handle billions of data objects. The hypervisor is a standards-based open solution that provides access to the data via parallel NFS client.
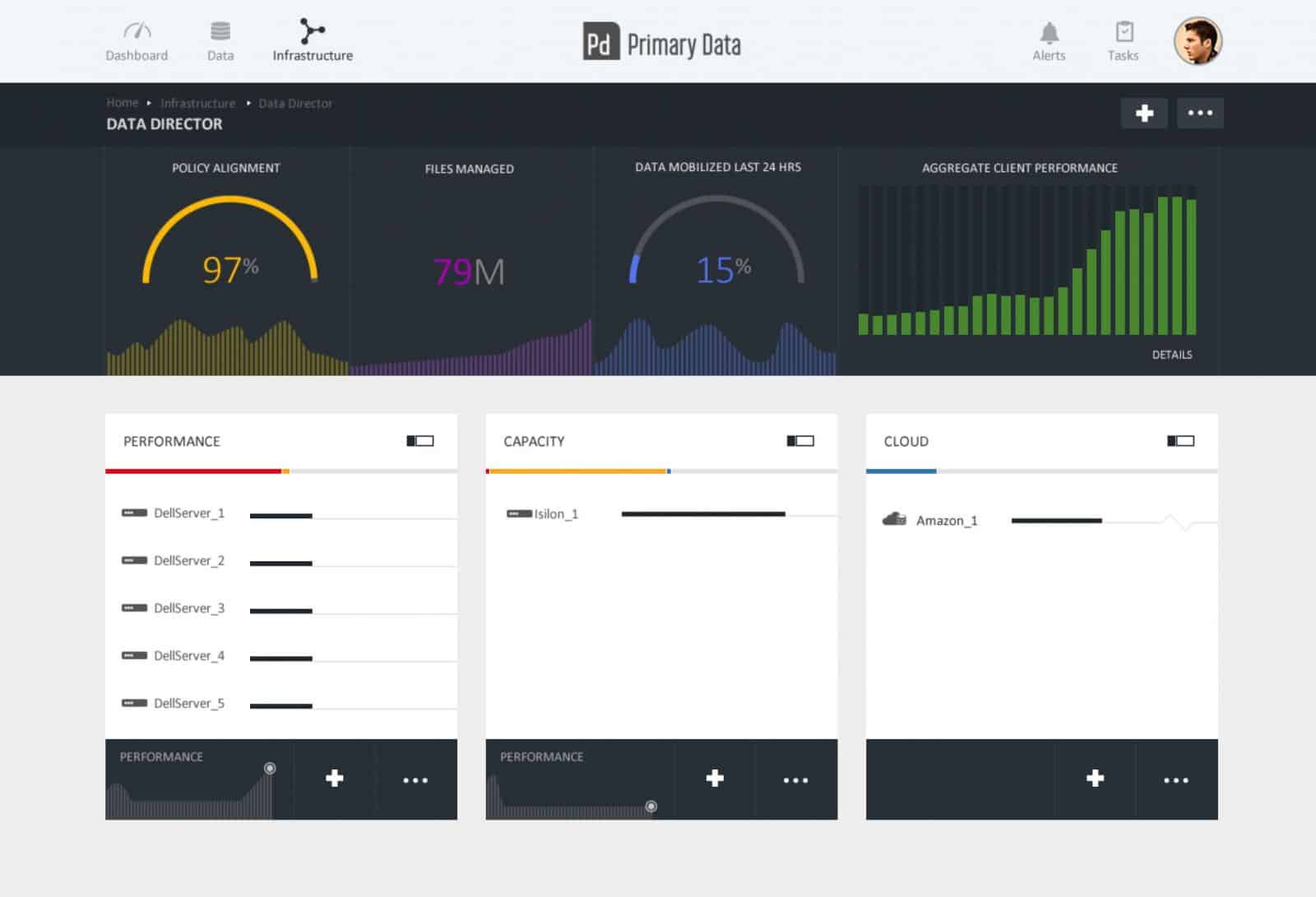
In their DEMO demonstration today, Primary Data showed their engine working against local high-speed storage within Dell servers, capacity storage on EMC Isilon and low-cost storage on Amazon's cloud. Primary Data is able to use a policy-driven process to move data within these three systems to optimize based on the policies that can be driven based on needs like performance, security and availability.
The use of a single namespace promises to better align enterprise-wide data demands with existing capacity. The Primary Data Platform also separates metadata from data to better support data mobility across types and tiers of storage and across file, block, and object stores. According to Primary Data, the solution will offer linear scalability of both performance and capacity. It will be made available initially as an integrated solution, however third-party storage vendors will also be supported.
Primary Data has raised over $60 million to date and is lead by an experienced team of storage veterans including Lance Smith (CEO), David Flynn (Co-Founder/CTO) and Rick White (Co-Founder), all from Fusion-io previously. Steve Wozniak has also come on board as Chief Scientist.
Pricing and Availability
Pricing and general availability will be announced in 2015.