
![]() Heute hat Alluxio auf dem AWS Global Summit die neueste Version seiner Datenorchestrierungstechnologie Alluxio 2.0 angekündigt. Die neueste Version bringt neue Innovationen für Dateningenieure mit und ist auf Multi-Cloud-Analysen und KI ausgerichtet.
Heute hat Alluxio auf dem AWS Global Summit die neueste Version seiner Datenorchestrierungstechnologie Alluxio 2.0 angekündigt. Die neueste Version bringt neue Innovationen für Dateningenieure mit und ist auf Multi-Cloud-Analysen und KI ausgerichtet.
Heute hat Alluxio auf dem AWS Global Summit die neueste Version seiner Datenorchestrierungstechnologie Alluxio 2.0 angekündigt. Die neueste Version bringt neue Innovationen für Dateningenieure mit und ist auf Multi-Cloud-Analysen und KI ausgerichtet.
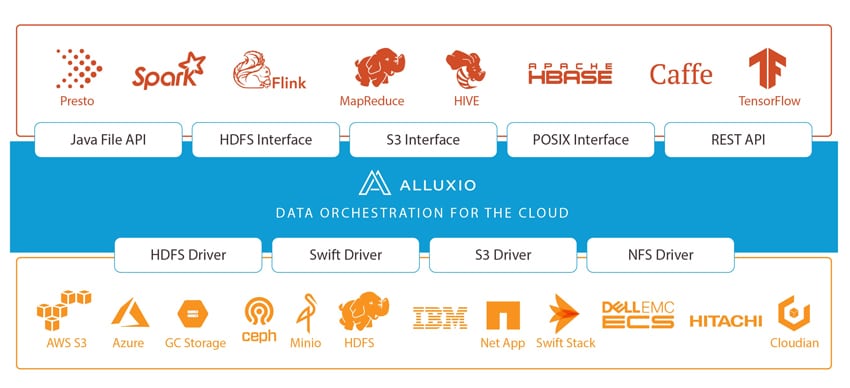
Wie bereits eingangs erwähnt, gibt Alluxio an, dass es sich um das weltweit erste System handelt, das Daten mit Speichergeschwindigkeit vereinheitlicht. Die „Speichergeschwindigkeit“ würde es Unternehmen ermöglichen, über unterschiedliche Speichersysteme hinweg schnell auf Daten zuzugreifen, was wiederum bedeutet, dass sie ihre Daten effizienter verwalten, schneller wertvolle Erkenntnisse gewinnen und die Einführung der Hybrid Cloud erleichtern können. Derzeit führt Alluxio kritische Workloads für Unternehmen wie Alibaba, Baidu, Barclay's Bank, CERN, ESRI, Huawei, Intel und Juniper aus.
Die Welt verlagert sich hin zu cloudbasierten, rechenintensiven Arbeitslasten. Dieser neue Schwerpunkt bedeutet, dass die Datenverarbeitung unabhängig vom Speicher auf elastische Weise skaliert werden muss. Aus Leistungssicht bietet dies zwar mehrere Vorteile, für Dateningenieure kann es jedoch auch zu Problemen führen. Alluxio möchte dieses Problem beheben, indem es eine Abstraktionsschicht hinzufügt, die Datenlokalität, Datenzugänglichkeit und Datenelastizität für die Berechnung über Datensilos, Zonen, Regionen und sogar Clouds hinweg ermöglicht.
Zu den Funktionen und Fähigkeiten gehören:
- Datenorchestrierungsinnovation für Multi-Cloud:
- Richtliniengesteuertes Datenmanagement
- Alluxio 2.0 umfasst eine neue Funktion, die es Dateningenieuren ermöglicht, die Datenverschiebung zwischen Speichersystemen basierend auf vordefinierten Richtlinien automatisiert und fortlaufend zu automatisieren. Das bedeutet, dass Alluxio bei der Erstellung von Daten und der Verwaltung heißer, warmer und kalter Daten das Tiering von Daten über eine beliebige Anzahl von Speichersystemen vor Ort und in allen Clouds automatisieren kann.
- Datenplattformteams können jetzt die Speicherkosten senken, indem sie automatisch nur die wichtigsten Daten in teuren Speichersystemen verwalten und andere Daten auf günstigere Speicheralternativen verschieben.
- Verbesserte Verwaltung von Datenzugriffsrichtlinien: Zusätzlich zu fein abgestuften Richtlinien auf Dateiebene können Benutzer jetzt Richtlinien auf jeder Verzeichnis- und Ordnerebene konfigurieren, um den Zugriff auf Daten sowie die Leistung von Arbeitslasten zu optimieren. Dazu gehört die Definition von Verhaltensweisen für einzelne Datensätze bei verschiedenen Kernfunktionen wie dem Schreiben von Daten oder der Synchronisierung von Daten mit Speichersystemen unter Alluxio.
- Effiziente Datenverschiebung über Cloud-Speicher hinweg über einen Datendienst: Der neue Datendienst ermöglicht eine hocheffiziente Datenverschiebung, auch über Cloud-Speicher wie AWS S3 und Google GCS hinweg, wodurch teure Vorgänge auf dem Objektspeicher nahtlos in das Rechen-Framework integriert werden.
- Richtliniengesteuertes Datenmanagement
- Computeroptimierter Datenzugriff für Cloud Analytics:
- Rechenorientierte Cluster-Partitionierung: Benutzer können jetzt ein einzelnes Alluxio basierend auf einer beliebigen Dimension partitionieren, sodass Datensätze für jedes Framework oder jede Arbeitslast nicht durch das andere verunreinigt werden. Die häufigste Verwendung umfasst die Partitionierung des Clusters nach Framework Spark, Presto usw. Darüber hinaus ermöglicht dies geringere Datenübertragungskosten, da die Daten auf eine bestimmte Zone oder Region beschränkt bleiben.
- Integration mit externen Datenquellen über REST: Benutzer können jetzt Daten sogar aus webbasierten Datenquellen einbringen, um sie in Alluxio zu aggregieren und ihre Analysen durchzuführen. Jeder Webspeicherort mit Dateien kann einfach auf Alluxio verwiesen werden, um sie bei Bedarf basierend auf der Abfrage oder dem Modelllauf abzurufen.
- Zu den weiteren Funktionen gehören:
- Hochverteilte Datendienste – 2.0 führt den Alluxio Data Service ein, einen verteilten Clusterdienst, der Datenoperationen wie Replikation und Persistenz ermöglicht, um hohe Leistung und enorme Skalierbarkeit zu ermöglichen.
- Adaptive Replikation für erhöhte Datenlokalität – Neue Funktion zum Konfigurieren eines Bereichs für die Anzahl der Kopien der in Alluxio gespeicherten Daten, die automatisch verwaltet werden.
- Hohe Verfügbarkeit mit eingebettetem Journal – Ein neuer Fehlertoleranz- und Hochverfügbarkeitsmodus für Datei- und Objektmetadaten, das sogenannte eingebettete Journal, das den RAFT-Konsensalgorithmus verwendet und unabhängig von anderen externen Speichersystemen ist. Dies ist besonders hilfreich für die Abstraktion der Objektspeicherung.
- Alluxio POSIX API – Die FUSE-Funktion von Alluxio ermöglicht eine POSIX-kompatible API, sodass Frameworks wie Tensorflow, Caffe und andere Python-basierte Modelle über Alluxio mithilfe des herkömmlichen Dateisystemzugriffs direkt auf Daten aus jedem Speichersystem zugreifen können.
- Amazon AWS-Support:
- AWS Elastic Map Reduce (EMR)-Serviceintegration: Da Benutzer auf Cloud-Services umsteigen, um Analyse- und KI-Workloads bereitzustellen, werden Services wie AWS EMR zunehmend genutzt. Alluxio kann jetzt nahtlos in einen AWS EMR-Cluster eingebunden werden, sodass es als Datenschicht innerhalb von EMR für Spark-, Presto- und Hive-Frameworks verfügbar ist. Benutzer haben jetzt eine leistungsstarke Alternative zum Zwischenspeichern von Daten aus S3 oder Remote-Daten und können gleichzeitig die in EMR verwalteten Datenkopien reduzieren.
Verfügbarkeit
Sowohl die Alluxio 2.0 Community als auch die Enterprise Edition sind jetzt verfügbar.
Diskutiere diese Geschichte
Melden Sie sich für den StorageReview-Newsletter an