
Die KI-Modelle Google Gemma 3 und AMD Instella verbessern die multimodalen und unternehmensweiten KI-Fähigkeiten und definieren neue KI-Leistungsstandards.
Google und AMD haben bedeutende Entwicklungen im Bereich der künstlichen Intelligenz angekündigt. Google stellte Gemma 3 vor, die neueste Generation seiner Open-Source-KI-Modellreihe. Gleichzeitig kündigte AMD die Integration mit der Open Platform for Enterprise AI (OPEA) an und stellte seine Instella-Sprachmodelle vor.
Googles Gemma 3: Multimodale KI-Effizienz auf minimaler Hardware
Die Veröffentlichung von Gemma 12 am 3. März baut auf dem Erfolg von Gemma 2 auf. Das neue Modell bietet multimodale Funktionen, mehrsprachige Unterstützung und verbesserte Effizienz und ermöglicht so eine erweiterte KI-Leistung selbst auf eingeschränkter Hardware.
Gemma 3 ist in vier Größen erhältlich: 1B, 4B, 12B und 27B Parameter. Jede Variante ist sowohl in einer Basisversion (vortrainiert) als auch in einer befehlsoptimierten Version erhältlich. Die größeren Modelle (4B, 12B und 27B) bieten multimodale Funktionalität und verarbeiten nahtlos Text, Bilder und kurze Videos. Googles SigLIP Vision Encoder wandelt visuelle Eingaben in vom Sprachmodell interpretierbare Token um. Dadurch kann Gemma 3 bildbasierte Fragen beantworten, Objekte identifizieren und eingebetteten Text lesen.
Gemma 3 erweitert zudem sein Kontextfenster deutlich und unterstützt bis zu 128,000 Token im Vergleich zu den 2 Token von Gemma 80,000. Dadurch kann das Modell mehr Informationen in einer einzigen Eingabeaufforderung verarbeiten. Darüber hinaus unterstützt Gemma 3 über 140 Sprachen und verbessert so die globale Zugänglichkeit.
LMSYS Chatbot Arena-Rangliste
Gemma 3 hat sich schnell als eines der leistungsstärksten KI-Modelle etabliert. LMSYS Chatbot Arena, ein Benchmark zur Bewertung großer Sprachmodelle basierend auf menschlichen Präferenzen. Gemma-3-27B erreichte einen Elo-Score von 1338 und belegte damit weltweit den neunten Platz. Damit liegt es vor namhaften Konkurrenten wie DeepSeek-V3 (1318), Llama3-405B (1257), Qwen2.5-72B (1257), Mistral Large und Googles vorherigen Gemma-2-Modellen.
AMD stärkt Enterprise-KI mit OPEA-Integration
AMD gab am 12. März 2025 seine Unterstützung für die Open Platform for Enterprise AI (OPEA) bekannt. Diese Integration verbindet das OPEA GenAI-Framework mit dem ROCm-Software-Stack von AMD und ermöglicht Unternehmen die effiziente Bereitstellung skalierbarer generativer KI-Anwendungen auf AMD-Rechenzentrums-GPUs.
Die Zusammenarbeit befasst sich mit zentralen Herausforderungen der Unternehmens-KI, darunter Komplexität der Modellintegration, GPU-Ressourcenmanagement, Sicherheit und Workflow-Flexibilität. Als Mitglied des technischen Lenkungsausschusses der OPEA arbeitet AMD mit Branchenführern zusammen, um zusammensetzbare generative KI-Lösungen zu ermöglichen, die in öffentlichen und privaten Cloud-Umgebungen eingesetzt werden können.
OPEA bietet wesentliche KI-Anwendungskomponenten, darunter vorgefertigte Workflows, Evaluierungsfunktionen, eingebettete Modelle und Vektordatenbanken. Die Cloud-native, auf Microservices basierende Architektur gewährleistet eine nahtlose Integration durch API-gesteuerte Workflows.
AMD bringt Instella auf den Markt: Vollständig offene 3B-Parameter-Sprachmodelle
AMD stellte außerdem Instella vor, eine Familie vollständig Open Source-Sprachmodelle mit 3 Milliarden Parametern, die vollständig auf AMD-Hardware entwickelt wurden.
Technische Innovationen und Trainingsansatz
Instella-Modelle verwenden eine textbasierte autoregressive Transformer-Architektur mit 36 Decoder-Ebenen und 32 Attention Heads pro Ebene und unterstützen Sequenzen mit bis zu 4,096 Token. Die Modelle nutzen über den OLMo-Tokenizer ein Vokabular von ca. 50,000 Token.
Nach einer mehrstufigen Pipeline erfolgte das Training auf 128 AMD Instinct MI300X GPUs auf 16 Knoten. Das anfängliche Vortraining umfasste rund 4.065 Billionen Token aus verschiedenen Datensätzen aus den Bereichen Programmierung, Wissenschaft, Mathematik und Allgemeinwissen. In einer zweiten Vortrainingsphase wurden die Problemlösungsfähigkeiten mithilfe von weiteren 57.575 Milliarden Token aus spezialisierten Benchmarks wie MMLU, BBH und GSM8k verfeinert.
Nach dem Vortraining wurde Instella einer überwachten Feinabstimmung (SFT) mit 8.9 Milliarden Token kuratierter Anweisungs-Antwort-Daten unterzogen, um die interaktiven Fähigkeiten zu verbessern. Eine abschließende Phase der direkten Präferenzoptimierung (DPO) passte das Modell mithilfe von 760 Millionen Token sorgfältig ausgewählter Daten eng an menschliche Präferenzen an.
Beeindruckende Benchmark-Leistung
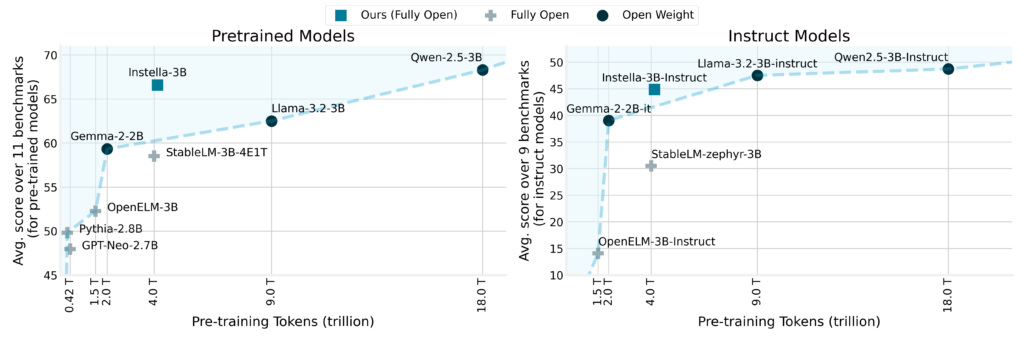
Benchmark-Ergebnisse unterstreichen die bemerkenswerten Leistungssteigerungen von Instella. Das Modell übertraf bestehende vollständig offene Modelle im Durchschnitt um über 8 % und erzielte beeindruckende Ergebnisse in Benchmarks wie ARC Challenge (+8.02 %), ARC Easy (+3.51 %), Winograde (+4.7 %), OpenBookQA (+3.88 %), MMLU (+13.12 %) und GSM8k (+48.98 %).
Im Gegensatz zu führenden Open-Weight-Modellen wie Llama-3.2-3B und Gemma-2-2B zeigte Instella bei mehreren Aufgaben eine überlegene oder sogar sehr konkurrenzfähige Leistung. Die befehlsoptimierte Variante, Instella-3B-Instruct, zeigte deutliche Vorteile gegenüber anderen vollständig offenen, befehlsoptimierten Modellen mit einem durchschnittlichen Leistungsvorsprung von über 14 % und war gleichzeitig konkurrenzfähig gegenüber führenden Open-Weight-, befehlsoptimierten Modellen.
Vollständige Open-Source-Veröffentlichung und Verfügbarkeit
Im Einklang mit AMDs Engagement für Open-Source-Prinzipien hat das Unternehmen alle Artefakte der Instella-Modelle veröffentlicht, einschließlich Modellgewichten, detaillierten Trainingskonfigurationen, Datensätzen und Code. Diese vollständige Transparenz ermöglicht der KI-Community die Zusammenarbeit, Replikation und Innovation mit diesen Modellen.
Fazit
Diese Ankündigungen von Google und AMD legen den Grundstein für ein spannendes Jahr der KI-Innovation. Die Dynamik in der Branche ist deutlich spürbar: Gemma 3 definiert multimodale Effizienz neu, und AMDs Instella-Modelle und die OPEA-Integration stärken die Unternehmens-KI. Mit Blick auf die NVIDIA GTC-Konferenz und die Erwartung weiterer bahnbrechender Veröffentlichungen ist klar, dass diese Entwicklungen nur der Anfang dessen sind, was noch kommen wird.
Beteiligen Sie sich an StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed