
Große Sprachmodelle bieten unglaubliche neue Möglichkeiten und erweitern die Grenzen dessen, was mit KI möglich ist. Aufgrund ihrer Größe und einzigartigen Ausführungsmerkmale kann es jedoch schwierig sein, sie kosteneffizient einzusetzen. NVIDIA TensorRT-LLM wurde als Open-Source-Lösung bereitgestellt, um die Entwicklung von LLMs zu beschleunigen.
Große Sprachmodelle bieten unglaubliche neue Möglichkeiten und erweitern die Grenzen dessen, was mit KI möglich ist. Aufgrund ihrer Größe und einzigartigen Ausführungsmerkmale kann es jedoch schwierig sein, sie kosteneffizient einzusetzen. NVIDIA TensorRT-LLM wurde als Open-Source-Lösung bereitgestellt, um die Entwicklung von LLMs zu beschleunigen.
Was ist NVIDIA TensorRT-LLM?
NVIDIA hat eng mit führenden Unternehmen zusammengearbeitet, darunter Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (jetzt Teil von Databricks), OctoML, Tabnine und Together AI, um die LLM-Inferenz zu beschleunigen und zu optimieren.

Diese Innovationen wurden in die Open-Source-Software integriert NVIDIA TensorRT-LLM Software, deren Veröffentlichung in den kommenden Wochen geplant ist. TensorRT-LLM besteht aus dem TensorRT Deep-Learning-Compiler und umfasst optimierte Kernel, Vor- und Nachverarbeitungsschritte sowie Multi-GPU-/Multi-Node-Kommunikationsprimitive für bahnbrechende Leistung auf NVIDIA-GPUs. Es ermöglicht Entwicklern, mit neuen LLMs zu experimentieren und bietet Spitzenleistung und schnelle Anpassungsmöglichkeiten, ohne dass tiefe C++- oder NVIDIA CUDA-Kenntnisse erforderlich sind.
TensorRT-LLM verbessert die Benutzerfreundlichkeit und Erweiterbarkeit durch eine modulare Open-Source-Python-API zum Definieren, Optimieren und Ausführen neuer Architekturen und Erweiterungen, während sich LLMs weiterentwickeln und einfach angepasst werden können.
Beispielsweise hat MosaicML spezifische Funktionen, die es zusätzlich zu TensorRT-LLM benötigt, nahtlos hinzugefügt und sie in seinen bestehenden Serving-Stack integriert. Naveen Rao, Vizepräsident für Technik bei Databricks, bemerkt: „Es war ein Kinderspiel.“
NVIDIA TensorRT-LLM-Leistung
Das Zusammenfassen von Artikeln ist nur eine der vielen Anwendungen von LLMs. Die folgenden Benchmarks zeigen Leistungsverbesserungen, die TensorRT-LLM auf der neuesten NVIDIA Hopper-Architektur erzielt.
Die folgenden Abbildungen spiegeln die Artikelzusammenfassung unter Verwendung einer NVIDIA A100 und NVIDIA H100 mit CNN/Daily Mail wider, einem bekannten Datensatz zur Bewertung der Zusammenfassungsleistung.
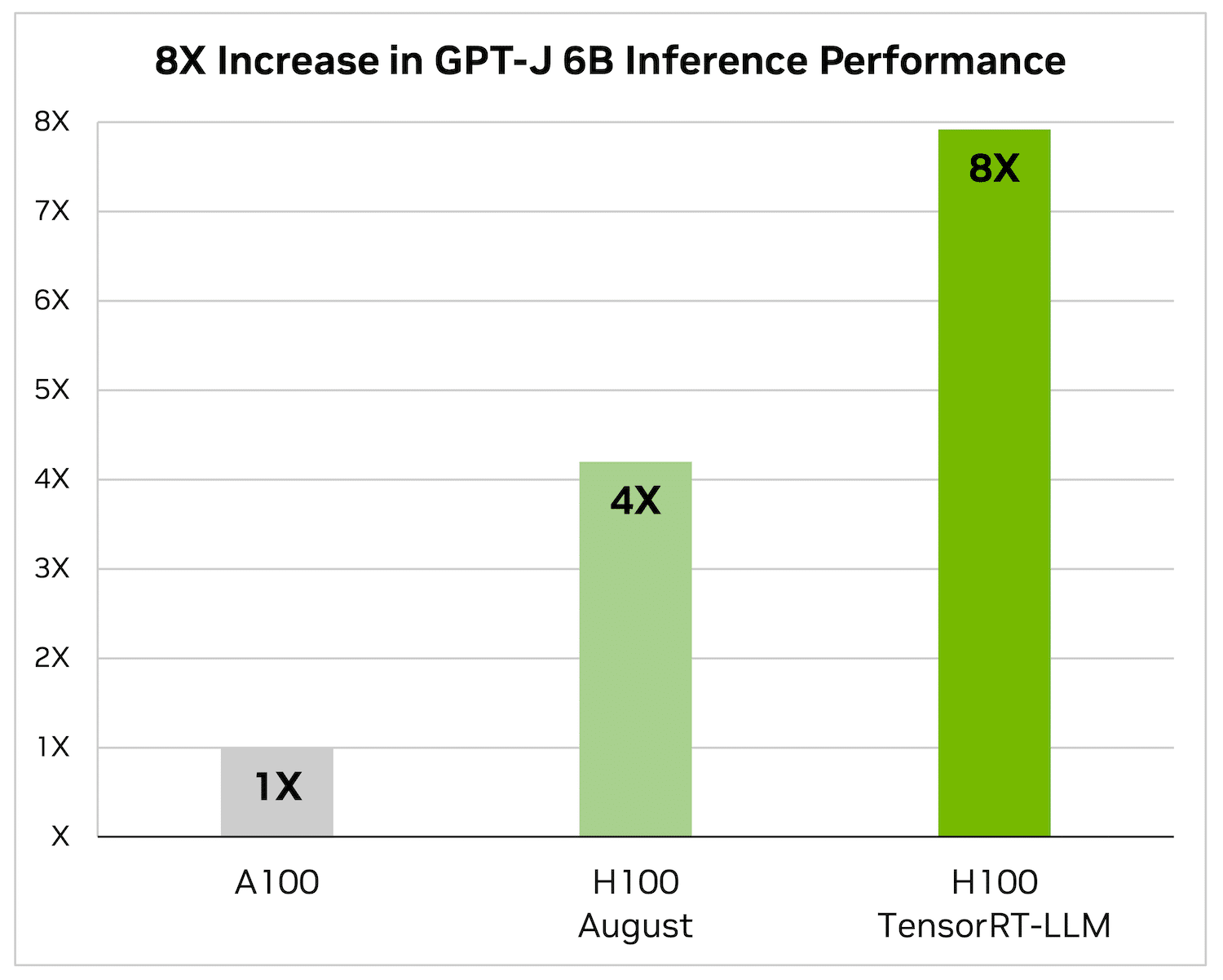
H100 allein ist 4x schneller als A100. Die Hinzufügung von TensorRT-LLM und seinen Vorteilen, einschließlich der Batchverarbeitung während des Flugs, führt zu einer 8-fachen Steigerung, um den höchsten Durchsatz zu erzielen.
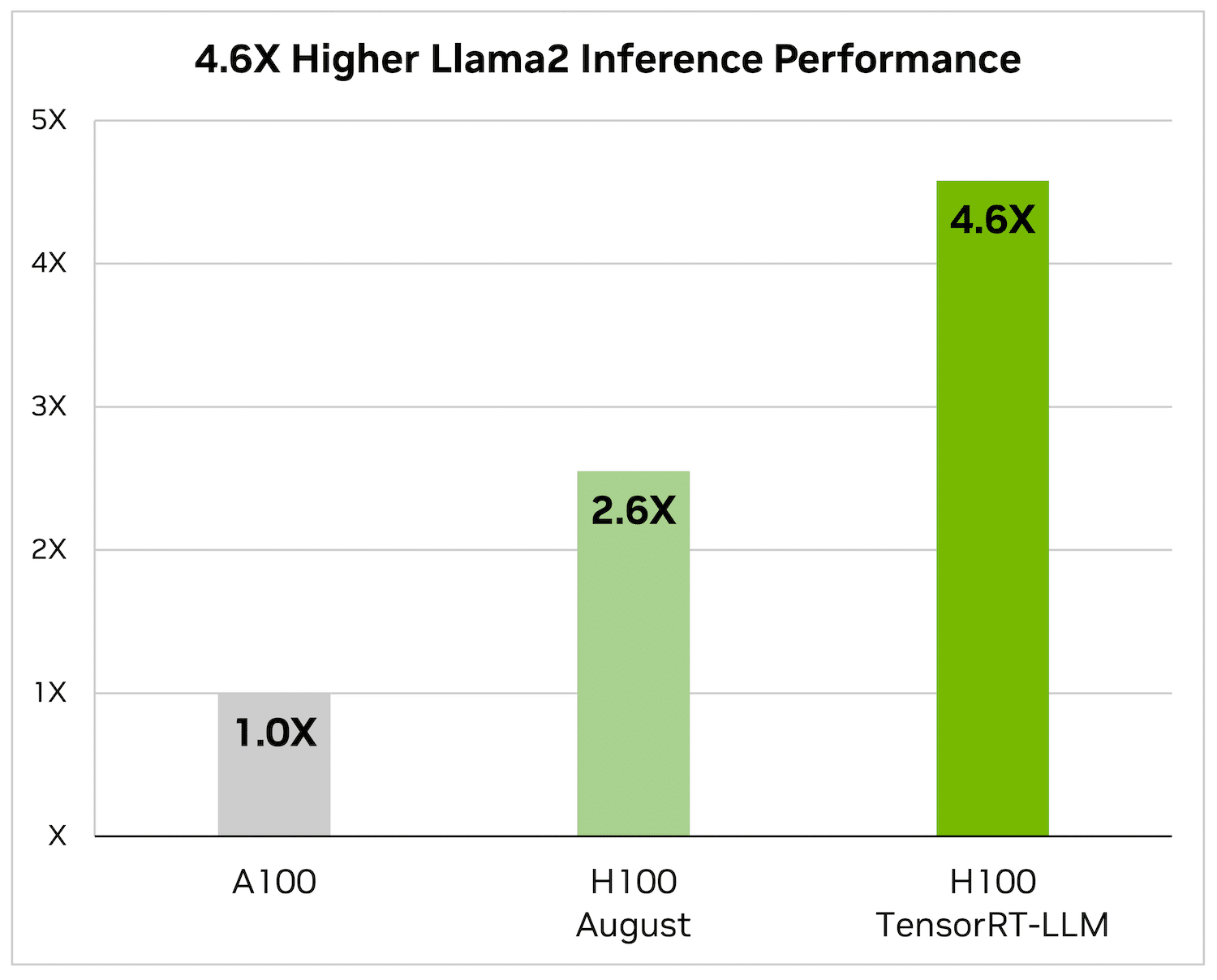
Auf Llama 2 – einem beliebten Sprachmodell, das kürzlich von Meta veröffentlicht wurde und häufig von Organisationen verwendet wird, die generative KI integrieren möchten – kann TensorRT-LLM die Inferenzleistung im Vergleich zu A4.6-GPUs um das 100-fache beschleunigen.
Die Innovation des LLM-Ökosystems entwickelt sich schnell weiter
Das Large Language Model (LLM)-Ökosystem entwickelt sich rasant weiter und führt zu vielfältigen Modellarchitekturen mit erweiterten Funktionen. Einige der größten und fortschrittlichsten LLMs, wie Metas Llama 70 mit 2 Milliarden Parametern, erfordern mehrere GPUs, um Echtzeitantworten bereitzustellen. Bisher umfasste die Optimierung der LLM-Inferenz für Spitzenleistungen komplexe Aufgaben wie die manuelle Aufteilung von KI-Modellen und die Koordinierung der GPU-Ausführung.
TensorRT-LLM vereinfacht diesen Prozess durch den Einsatz von Tensorparallelität, einer Form der Modellparallelität, die Gewichtsmatrizen auf Geräte verteilt. Dieser Ansatz ermöglicht eine effiziente Scale-out-Inferenz über mehrere GPUs, die über NVLink miteinander verbunden sind, und mehrere Server, ohne dass Entwickler eingreifen oder Modelländerungen vornehmen müssen.
Wenn neue LLMs und Modellarchitekturen auftauchen, können Entwickler ihre Modelle mit den neuesten NVIDIA-KI-Kerneln optimieren, die in TensorRT-LLM verfügbar sind, einschließlich modernster Implementierungen wie FlashAttention und maskierter Multi-Head-Aufmerksamkeit.
Darüber hinaus enthält TensorRT-LLM voroptimierte Versionen weit verbreiteter LLMs wie Meta Llama 2, OpenAI GPT-2, GPT-3, Falcon, Mosaic MPT, BLOOM und andere. Diese können mit der benutzerfreundlichen TensorRT-LLM-Python-API einfach implementiert werden und ermöglichen Entwicklern die Erstellung maßgeschneiderter LLMs, die auf verschiedene Branchen zugeschnitten sind.
Um der dynamischen Natur von LLM-Workloads gerecht zu werden, führt TensorRT-LLM In-Flight-Batching ein und optimiert so die Planung von Anforderungen. Diese Technik verbessert die GPU-Auslastung und verdoppelt den Durchsatz bei realen LLM-Anfragen nahezu, wodurch die Gesamtbetriebskosten (TCO) gesenkt werden.

Dell XE9680 GPU-Block
Darüber hinaus verwendet TensorRT-LLM Quantisierungstechniken, um Modellgewichte und -aktivierungen mit geringerer Präzision darzustellen (z. B. FP8). Dadurch wird der Speicherverbrauch reduziert, sodass größere Modelle effizient auf derselben Hardware ausgeführt werden können und gleichzeitig der speicherbezogene Overhead während der Ausführung minimiert wird.
Das LLM-Ökosystem entwickelt sich rasant weiter und bietet branchenübergreifend immer mehr Möglichkeiten und Anwendungen. TensorRT-LLM optimiert die LLM-Inferenz und verbessert so Leistung und Gesamtbetriebskosten. Es ermöglicht Entwicklern, Modelle einfach und effizient zu optimieren. Um auf TensorRT-LLM zuzugreifen, können Entwickler und Forscher über das NVIDIA NeMo-Framework oder GitHub am Early-Access-Programm teilnehmen, sofern sie mit der E-Mail-Adresse einer Organisation im NVIDIA-Entwicklerprogramm registriert sind.
Abschließende Gedanken
Wir haben in The Lab schon lange darauf hingewiesen, dass es Overhead gibt, der vom Software-Stack nicht ausreichend genutzt wird, und TensorRT-LLM macht deutlich, dass es äußerst wertvoll sein kann, den Fokus wieder auf Optimierungen und nicht nur auf Innovation zu legen. Während wir weiterhin lokal mit verschiedenen Frameworks und modernster Technologie experimentieren, planen wir, diese Vorteile aus den verbesserten Bibliotheks- und SDK-Versionen unabhängig zu testen und zu validieren.
NVIDIA investiert eindeutig Entwicklungszeit und -ressourcen, um das letzte bisschen Leistung aus seiner Hardware herauszuholen, seine Position als Branchenführer weiter zu festigen und seinen Beitrag zur Community und zur Demokratisierung der KI fortzusetzen, indem das Unternehmen den Open-Source-Charakter der Tools beibehält .
Beteiligen Sie sich an StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed