
 Die Informatik hat sich insbesondere in den letzten zehn Jahren dramatisch verändert. Laut IDC haben der Aufstieg von Web- und Mobilanwendungen und die Kommerzialisierung von Tools zur Inhaltserstellung den Konsum und die Erstellung von Inhalten am Endpunkt um mindestens das 30-fache erhöht. Daher sind Unternehmen heute bestrebt, aus den Petabytes an Daten, die sie derzeit üblicherweise speichern, einen größeren Nutzen zu ziehen. Echte Self-Service-Clouds, die auf Anwendungs- und Infrastrukturebene betrieben werden, sind mittlerweile Multimilliarden-Dollar-Unternehmen. Sensornetzwerke und andere Maschine-zu-Maschine-Interaktionen versprechen einen weiteren exponentiellen Sprung bei der Datenbewegung und -speicherung. Doch trotz all dieser monumentalen Veränderungen bei der Nutzung von Daten und Inhalten sind die gängigen Speicherarchitekturen, abgesehen von Kapazitäts- und Prozessorleistungssteigerungen, in den letzten zwanzig Jahren im Wesentlichen unverändert geblieben. Wir versuchen, mit Architekturen, die für Terabyte ausgelegt sind, im Multi-Petabyte-Bereich zu rechnen.
Die Informatik hat sich insbesondere in den letzten zehn Jahren dramatisch verändert. Laut IDC haben der Aufstieg von Web- und Mobilanwendungen und die Kommerzialisierung von Tools zur Inhaltserstellung den Konsum und die Erstellung von Inhalten am Endpunkt um mindestens das 30-fache erhöht. Daher sind Unternehmen heute bestrebt, aus den Petabytes an Daten, die sie derzeit üblicherweise speichern, einen größeren Nutzen zu ziehen. Echte Self-Service-Clouds, die auf Anwendungs- und Infrastrukturebene betrieben werden, sind mittlerweile Multimilliarden-Dollar-Unternehmen. Sensornetzwerke und andere Maschine-zu-Maschine-Interaktionen versprechen einen weiteren exponentiellen Sprung bei der Datenbewegung und -speicherung. Doch trotz all dieser monumentalen Veränderungen bei der Nutzung von Daten und Inhalten sind die gängigen Speicherarchitekturen, abgesehen von Kapazitäts- und Prozessorleistungssteigerungen, in den letzten zwanzig Jahren im Wesentlichen unverändert geblieben. Wir versuchen, mit Architekturen, die für Terabyte ausgelegt sind, im Multi-Petabyte-Bereich zu rechnen.
Von Leo Leung, Vizepräsident für Unternehmensmarketing, Scality
Die Informatik hat sich insbesondere in den letzten zehn Jahren dramatisch verändert. Laut IDC haben der Aufstieg von Web- und Mobilanwendungen und die Kommerzialisierung von Tools zur Inhaltserstellung den Konsum und die Erstellung von Inhalten am Endpunkt um mindestens das 30-fache erhöht. Daher sind Unternehmen heute bestrebt, aus den Petabytes an Daten, die sie derzeit üblicherweise speichern, einen größeren Nutzen zu ziehen. Echte Self-Service-Clouds, die auf Anwendungs- und Infrastrukturebene betrieben werden, sind mittlerweile Multimilliarden-Dollar-Unternehmen. Sensornetzwerke und andere Maschine-zu-Maschine-Interaktionen versprechen einen weiteren exponentiellen Sprung bei der Datenbewegung und -speicherung. Doch trotz all dieser monumentalen Veränderungen bei der Nutzung von Daten und Inhalten sind die gängigen Speicherarchitekturen, abgesehen von Kapazitäts- und Prozessorleistungssteigerungen, in den letzten zwanzig Jahren im Wesentlichen unverändert geblieben. Wir versuchen, mit Architekturen, die für Terabyte ausgelegt sind, im Multi-Petabyte-Bereich zu rechnen.
Software-Defined Storage (SDS) verspricht ein flexibleres Speichermodell, bei dem die Speicherung wirklich zu einem der Dienste neben anderen Computerdiensten wird. Hardware-Unabhängigkeit ist Teil dieser Architektur, da Daten und Dienste freier fließen müssen, wenn sich Anwendungen ändern und Systeme vergrößert oder verkleinert werden. Anstatt Datenverwaltungsfunktionen in proprietäre geschlossene Appliances einzubetten, entkoppelt SDS diese Funktionalität von der Hardware – ermöglicht eine Funktionalität, die sich auf Daten konzentriert – und erstreckt sich natürlich über die Hardware. Wie andere Kommerzialisierungsmuster der Infrastruktur im Laufe der Zeit (z. B. Soft Switches) macht diese Entkopplung auch die überhöhten Margen (60 Prozent) deutlich, die heute in Speichergeräten enthalten sind.
Da SDS oft im Multi-Petabyte-Bereich eingesetzt wird, muss die Verfügbarkeit extrem hoch sein und darf bei bekannten Fehlerszenarien keinen Eingriff erfordern. Anwendungsschnittstellen müssen sowohl für bestehende Anwendungen als auch für neuere web- und mobilbasierte Apps geeignet sein. Die Leistung sollte stark, linear skalierbar und für gemischte Arbeitslasten geeignet sein. Dienste wie Datenschutz und Datenwiederherstellung müssen auf das gleiche Maß an Dynamik und Skalierung ausgelegt sein.
Dies steht in starkem Gegensatz zu älteren Speicherarchitekturen, die vollständig an physische Hardware gebunden sind und Verfügbarkeits-, Datenzugriffs-, Leistungs-, Verwaltungs- und Haltbarkeitsfunktionen in den begrenzten Umfang proprietärer Appliances einbetten. Diese Legacy-Architekturen sind für kleinere Skalierungen in allen oben genannten Dimensionen konzipiert.
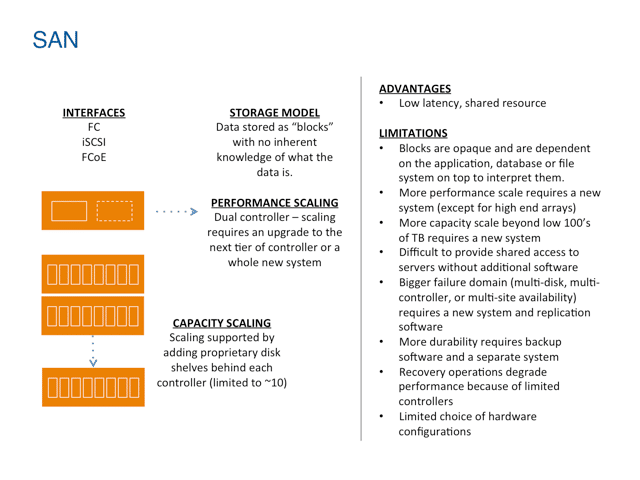
SAN ist immer noch ein guter Ansatz für den Zugriff auf Daten mit geringer Latenz, ist jedoch im großen Maßstab unzureichend
SAN wurde als einfachste Möglichkeit zur Verbindung mit Speicher über ein dediziertes lokales Netzwerk konzipiert. Es steuert Datenblöcke in kleinen logischen Volumina, hat jedoch keinen Kontext zu den Daten und hängt vollständig von der Anwendung ab, um die Daten zu organisieren, zu katalogisieren und zu strukturieren. SANs sind konstruktionsbedingt in Größe, Schnittstellen und Umfang begrenzt und aufgrund der dedizierten Netzwerkinfrastruktur in der Regel teurer.
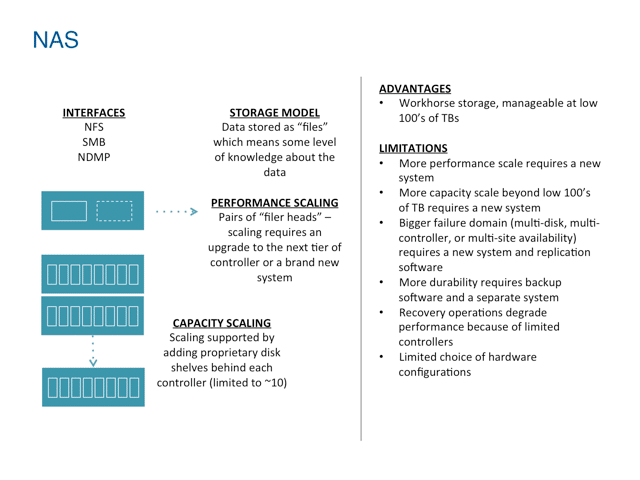
Die Datei dominiert immer noch und NAS ist ein Arbeitstier, wird jedoch bei der Skalierung vor Herausforderungen gestellt
NAS wurde ebenfalls als Schnittstelle zu lokal vernetzten Speichern konzipiert, bietet jedoch mehr Struktur in Form von Dateisystemen und Dateien. Dateisysteme unterliegen natürlichen Grenzen, die auf den lokalen internen Strukturen basieren, die zur Verwaltung der Dateihierarchie und des Dateizugriffs verwendet werden. Aufgrund der Informationen innerhalb der verwalteten Dateihierarchie besteht eine grundlegendere Kenntnis des Inhalts im System, diese ist jedoch vollständig auf einen physischen Speichercontroller beschränkt. Auch konstruktionsbedingt sind NAS-Systeme in Größe und Umfang begrenzt. Geclusterte NAS-Systeme erweitern die Skalierbarkeit der Technologie, weisen aber auch natürliche Grenzen auf, die an physische Controller (Nummerierung im Zehnerbereich) und die zentrale Datenbank gebunden sind, die zur Verfolgung der Dateihierarchie und der Dateien verwendet wird.
Object Storage ist skalierbar, bietet aber nur sehr begrenzte Workload-Unterstützung
Object Storage ist eine Technologie, die zusätzliche Abstraktion schafft, oft zusätzlich zu und über lokale Dateisysteme hinweg. Das bedeutet, dass Daten im System als Objekte (anstelle von Blöcken oder Dateien) in einem globalen Namensraum verwaltet werden, mit eindeutigen Kennungen für jedes Objekt. Dieser Namespace kann Hunderte von Servern umfassen und ermöglicht so eine einfachere Kapazitätsskalierung als SAN- oder NAS-Modelle.
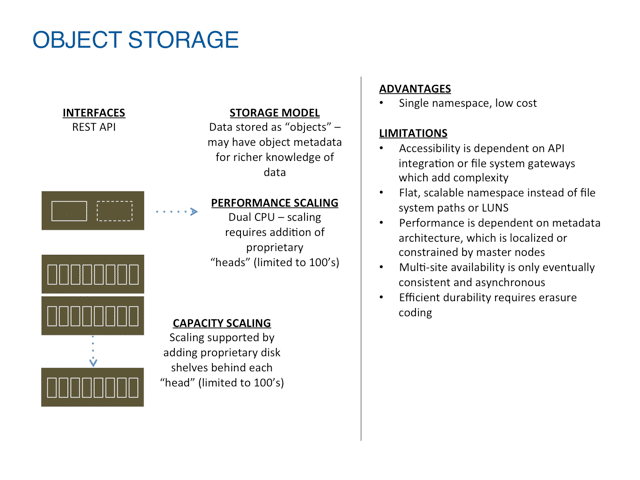
Die Anwendungsunterstützung von Objektspeichern ist jedoch grundsätzlich eingeschränkt, da sie erfordern, dass Anwendungen auf eine bestimmte Variante der HTTP-API umgeschrieben werden müssen und die Leistung typischerweise auf Szenarios „Einmal schreiben, viele lesen“ (WORM) oder „Einmal schreiben, nie lesen“ beschränkt. Dieser Leistungsmangel ist auf Architekturen zurückzuführen, die den Datenverkehr durch eine begrenzte Anzahl von Metadatenknoten erzwingen, was mitunter zu zusätzlichem Overhead für diese begrenzten Knoten durch Dienste wie Erasure Coding führt.
Software-Defined Storage ist ganzheitlich für große Skalierungen konzipiert
Software-Defined Storage ist ein neuer Ansatz, der die Speicherfunktionalität vollständig von spezifischer Hardware entkoppelt und dadurch eine flexiblere Bereitstellung, Skalierbarkeit, Zugänglichkeit und Bedienung ermöglicht.

Durch die Entkopplung von SDS kann die Software die Hardware unabhängig nutzen und Kapazität, Leistung und Zugänglichkeit je nach Anwendungsfall unabhängig skalieren. Diese Art der Anpassung ist außerhalb des herkömmlichen Speichers der Spitzenklasse, der über speziell für diesen Zweck entwickelte Hardwarekomponenten verfügt, nicht möglich, was letztendlich immer noch die Flexibilität und Gesamtskalierung einschränkt.
Die Entkopplung der Speicherfunktionalität von der Hardware erleichtert auch die Identifizierung von Problemen im Gesamtsystem, anstatt Geräte zu beheben, die Hardware- und Software-Ausnahmebehandlung in einem Stack mit geringem Signal-Rausch-Verhältnis kombinieren.
Über die grundlegende Trennung von Software und Hardware hinaus nutzen die SDS-Speicherdienste auch die Vorteile der Entkopplung, indem sie Kapazitäts-, Verfügbarkeits-, Haltbarkeits- und Zugänglichkeitsdienste anbieten, die physische Grenzen überbrücken können. Ein gemeinsames Merkmal von SDS ist die Verwendung von Objektspeicher zur Erstellung eines nahezu unbegrenzten Namensraums einzigartiger Objekte. Dies geht über die Verwaltungseinheiten von Logical Unit Numbers (LUNs) und Dateisystemen hinaus, die konstruktionsbedingt grundlegende Skalierungsbeschränkungen aufweisen. Dies ermöglicht die Skalierung eines SDS-Systems, indem einfach mehr physische Kapazität hinzugefügt wird, ohne dass neue Verwaltungseinheiten hinzugefügt werden müssen.
Auch die Verfügbarkeit von SDS-Systemen kann erheblich verbessert werden, da der private Netzwerkraum zwischen SDS-Knoten genutzt wird. Anstelle der begrenzten Aktiv/Passiv-Controller-Anordnung der meisten SAN- und NAS-Systeme oder der Cluster-Anordnung von Scale-out-NAS können SDS-Systeme weiterhin auf Tausende von Adressen innerhalb einer Domäne skaliert werden. Darüber hinaus können SDS-Systeme auch die Vorteile fortschrittlicher Routing-Algorithmen nutzen, um eine Reaktion selbst in Topologien großen Maßstabs und bei mehreren Fehlerszenarien zu gewährleisten. Dies geht weit über die einfachen Switched Fabrics oder Daisy Chains herkömmlicher Speicher hinaus, bei denen aufgrund eines einfachen Verkabelungsfehlers ein ganzes Array ausfallen kann.
Die Haltbarkeit herkömmlicher Speichersysteme ist darauf ausgelegt, den gelegentlichen Ausfall einer oder zweier Festplatten zu überstehen, sodass ein nahezu sofortiger Austausch erforderlich ist. In einem System im Petabyte-Bereich beginnt die Anzahl der Festplatten bei Hunderten und wächst oft auf Tausende an. Selbst bei einer hohen mittleren Zeit zwischen Ausfällen (MTBF) sind immer mehrere Festplatten ausgefallen. SDS-Systeme sind darauf ausgelegt, viele Ausfälle und viele verschiedene Fehlerdomänen zu erwarten. Sie nutzen die verteilte Kapazität und Verarbeitung auf natürliche Weise für verteilte Schutzsysteme und extrem schnelle Wiederherstellungen. Dies ist im großen Maßstab erforderlich, im Gegensatz zum Dual-Controller-Schema von Scale-Up-Architekturen, bei denen es bei Festplattenneuerstellungen oder anderen Speicherdiensten zu erheblichen Engpässen kommt.
Bei herkömmlichen Speichersystemen war die Zugänglichkeit von untergeordneter Bedeutung. Anwendungsserver oder Mainframes befanden sich in lokalen, speicherspezifischen Netzwerken mit einigen ausgereiften Protokollen. Gemeinsam genutzte Ethernet-Netzwerke und gemischter öffentlicher und privater Zugang sind mittlerweile die Norm. SDS-Systeme müssen ein viel breiteres Spektrum an Anforderungen unterstützen. Vom webbasierten bis zum Ethernet-basierten Zugriff, von netzwerkbasierten Speicherressourcen bis hin zur Bereitstellung als lokale Ressource auf dem Anwendungsserver – SDS muss sie alle unterstützen.
Wie in diesem Artikel bereits erwähnt, ist herkömmlicher Speicher hochspezialisiert, was in einem typischen Großunternehmen zu vielen Funktions- und Datensilos führt. Dies ist nicht nur aus betrieblicher Sicht höchst ineffizient, sondern bringt auch keine Skaleneffekte mit sich und schränkt die Möglichkeiten für den Datenaustausch und die Wiederverwendung drastisch ein.
SDS ist darauf ausgelegt, die meisten Anwendungsintegrationsanforderungen zu erfüllen, wobei die Protokolle von persistent bis zustandslos, von einfach bis hochgradig interaktiv und semantisch umfangreich reichen. Dies ermöglicht eine Allzweckumgebung, in der die Speicherung ein allgemeiner Dienst für Anwendungen sein kann, unabhängig davon, ob es sich um kleine oder große Dateien, unterschiedliche Schutzanforderungen und unterschiedliche Protokollanforderungen handelt. Dadurch werden die derzeitigen Grenzen zwischen NAS-, Objekt- und Bandspeicherung aufgehoben, die Hebelwirkung freigesetzt, die die Hyperscale-Player seit Jahren genießen, und die Speicherdienste werden für eine Welt aktualisiert, in der sich die Konnektivität auf Milliarden von Endpunkten ausgeweitet hat.
Zusammenfassend lässt sich sagen, dass sich Anwendungen und Anforderungen dramatisch verändert haben. Da 90 Prozent aller Daten allein in den letzten zwei Jahren erstellt wurden; Wir befinden uns direkt im Petabyte-Zeitalter, und die Exabytes stehen vor der Tür. Der Schmerz im Petabyte-Bereich und das Streben nach einem besseren Datenwert sind zum Auslöser für die Überlegung neuer Ansätze geworden, da jahrzehntealte traditionelle Ansätze an ihre vorgesehenen Grenzen stoßen und überfordert sind.
Besprechen Sie diese Geschichte
Über den Autor
Sie können Leo Leung folgen auf Twitter oder schauen Sie sich seine Website an techexpectations.org.