
Meta dévoile Llama 4, une puissante famille de modèles d'IA basée sur MoE offrant une efficacité, une évolutivité et des performances multimodales améliorées.
Meta a présenté sa dernière innovation en matière d'IA, Llama 4, un ensemble de modèles améliorant les capacités d'intelligence multimodale. Llama 4 repose sur l'architecture Mixture-of-Experts (MoE), qui offre une efficacité et des performances exceptionnelles.
Comprendre les modèles MoE et la parcimonie
Les modèles à mélange d'experts (MoE) diffèrent considérablement des modèles denses traditionnels, où le modèle entier traite chaque entrée. Dans ces modèles, seul un sous-ensemble des paramètres, appelé « experts », est activé pour chaque entrée. Cette activation sélective dépend des caractéristiques de l'entrée, ce qui permet au modèle d'allouer les ressources de manière dynamique et d'améliorer son efficacité.
La parcimonie est un concept essentiel des modèles MoE, indiquant le ratio de paramètres inactifs pour une entrée spécifique. Les modèles MoE peuvent réduire considérablement les coûts de calcul en exploitant la parcimonie tout en maintenant ou en améliorant les performances.
Découvrez la famille Llama 4 : Scout, Maverick et Behemoth
La suite Llama 4 comprend trois modèles : Llama 4 Scout, Llama 4 Maverick et Llama 4 Behemoth. Chaque modèle est conçu pour répondre à différents cas d'utilisation et exigences.
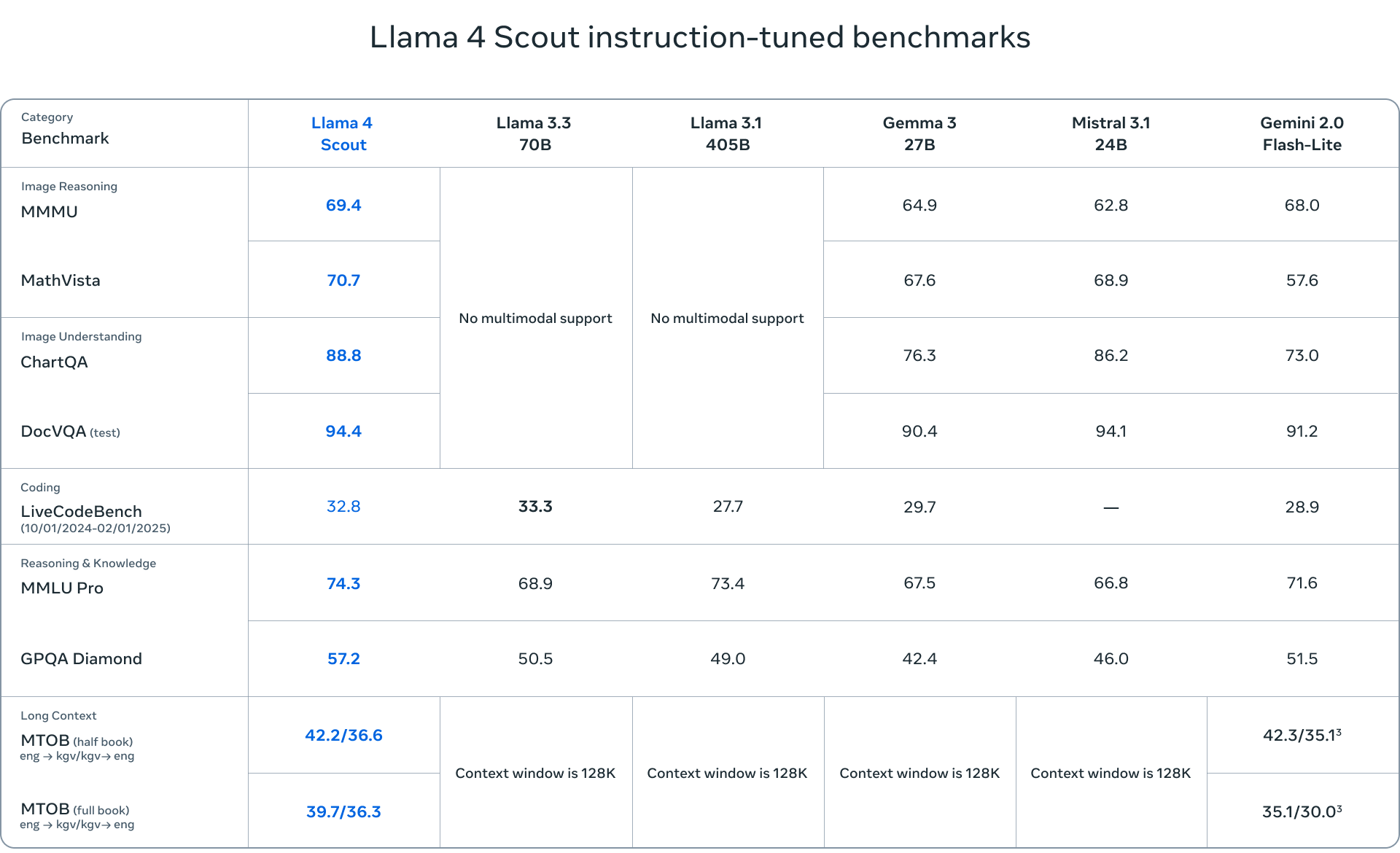
- Llama 4 Scout est un modèle compact avec 17 milliards de paramètres actifs et 109 milliards de paramètres au total pour 16 experts. Optimisé pour son efficacité, il peut fonctionner sur un seul GPU NVIDIA H100 (FP4 Quantized). Scout dispose d'une impressionnante fenêtre contextuelle de 10 millions de jetons, ce qui le rend idéal pour les applications nécessitant une compréhension approfondie du contexte.
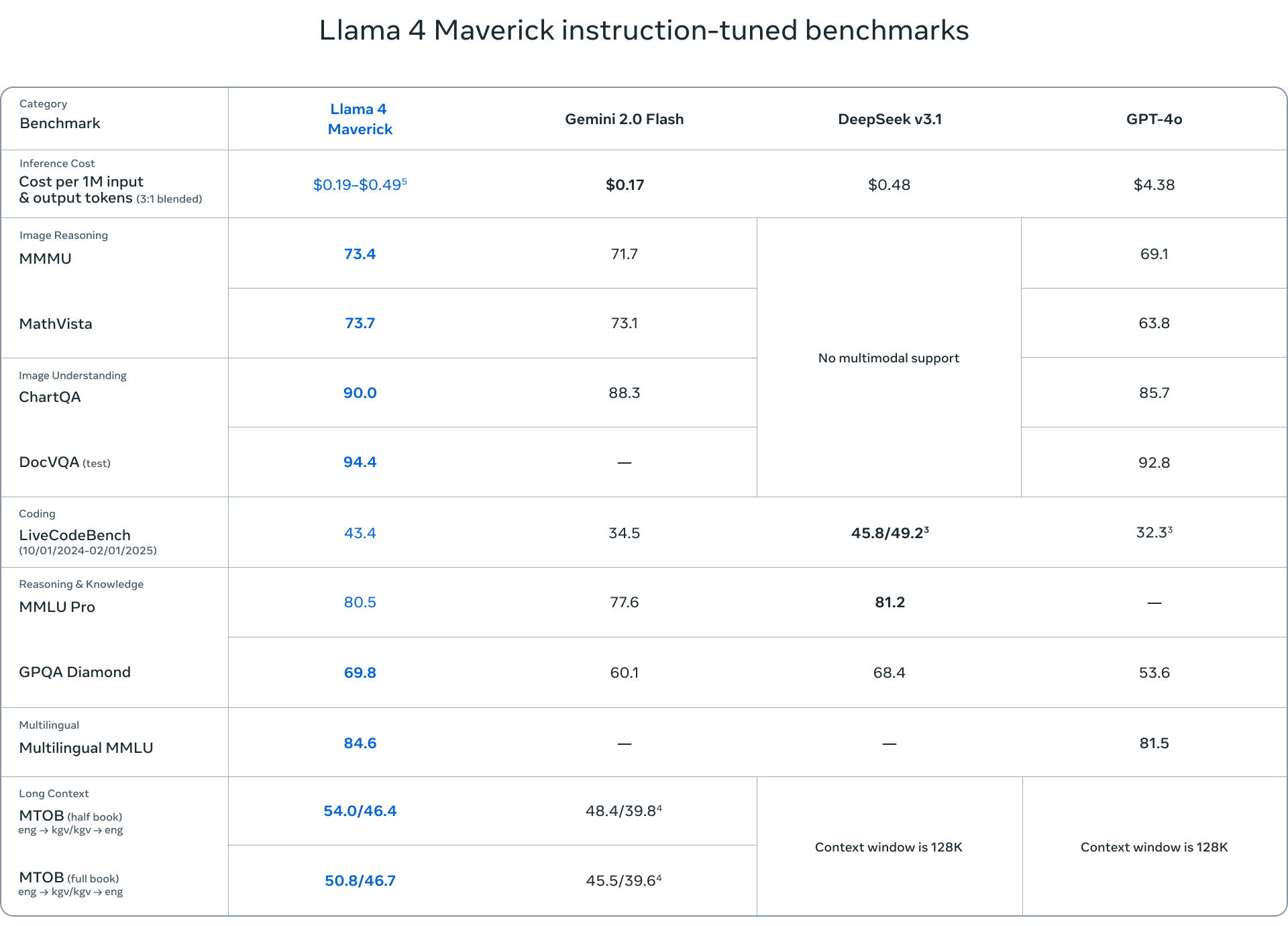
- Llama 4 Maverick est un modèle plus robuste, avec les mêmes 17 milliards de paramètres actifs, mais avec 128 experts, pour un total de 400 milliards de paramètres. Maverick excelle dans la compréhension multimodale, les tâches multilingues et le codage, surpassant des concurrents comme GPT-4o et Gemini 2.0 Flash.
- Llama 4 Behemoth est le plus grand modèle de la suite, avec 288 milliards de paramètres actifs et près de 2 16 milliards de paramètres au total, répartis sur 4.5 experts. Bien qu'encore en phase de développement, Behemoth a déjà démontré des performances de pointe sur divers benchmarks, surpassant des modèles comme GPT-3.7 et Claude Sonnet XNUMX.
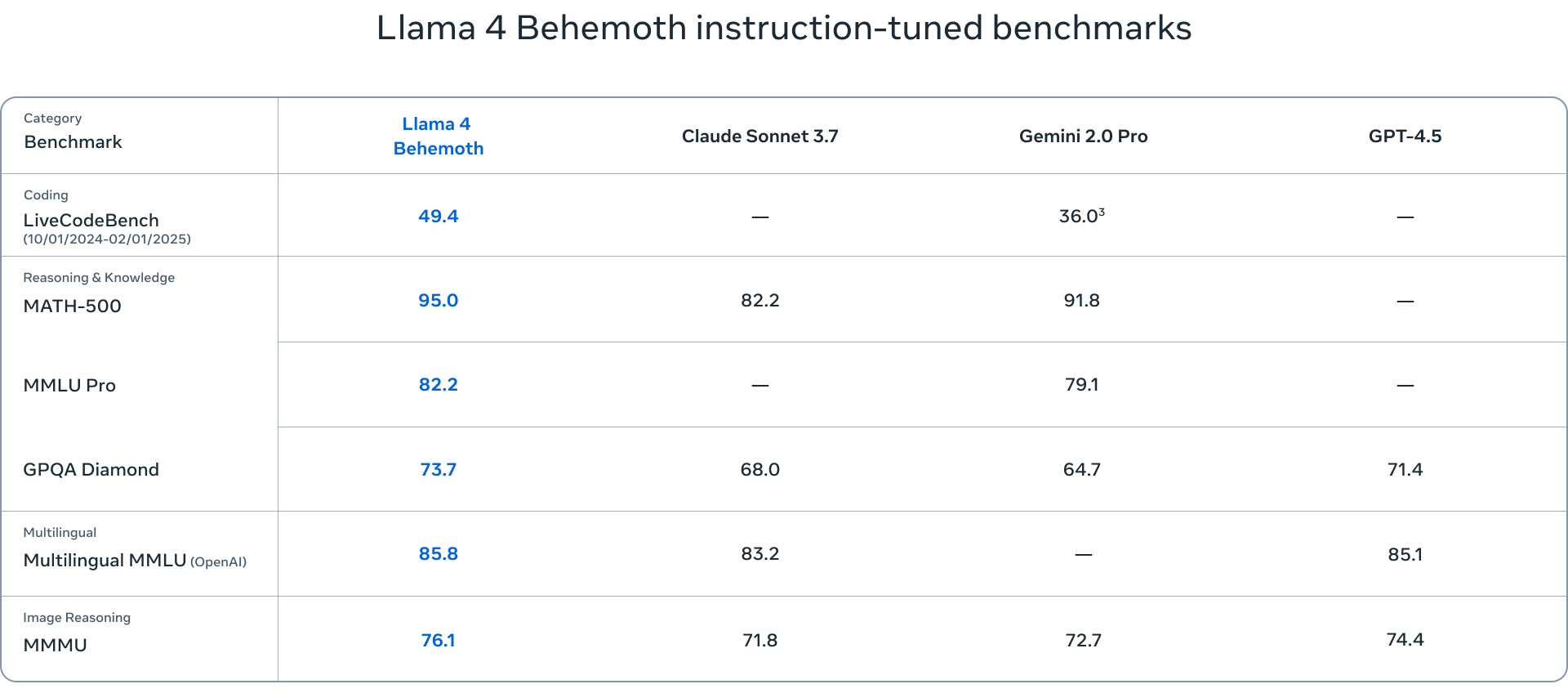
Les critères d'évaluation des modèles Llama 4 couvrent un large éventail de tâches, notamment la compréhension du langage (MMLU – Massive Multitask Language Understanding, GPQA – Google-Proof Question Answering), la résolution de problèmes mathématiques (MATH – Mathematical Problem-Solving, MathVista – un critère de référence pour la résolution de problèmes mathématiques en contexte visuel) et la compréhension multimodale (MMMU – Massive Multimodal Multitask Understanding). Ces critères standard fournissent une évaluation complète des capacités des modèles et aident à identifier leurs points forts ou leurs points à améliorer.
Le rôle des modèles enseignants dans Llama 4
Un modèle enseignant est un grand modèle pré-entraîné qui guide les modèles plus petits et leur transfère ses connaissances et ses capacités par distillation. Dans le cas de Llama 4, Behemoth joue le rôle de modèle enseignant et transmet ses connaissances à Scout et Maverick. Le processus de distillation consiste à entraîner les modèles plus petits à imiter le comportement du modèle enseignant, leur permettant ainsi d'apprendre de ses forces et de ses faiblesses. Cette approche permet aux modèles plus petits d'atteindre des performances impressionnantes tout en étant plus efficaces et évolutifs.
Implications et orientations futures
La sortie de Llama 4 marque une étape importante dans le paysage de l'IA, avec des implications considérables pour la recherche, le développement et les applications. Historiquement, les modèles Llama ont été un catalyseur pour la recherche en aval, inspirant diverses études et innovations. La version 4 de Llama devrait poursuivre cette tendance, permettant aux chercheurs de développer et d'affiner les modèles pour relever des défis et des tâches complexes.
De nombreux modèles ont été optimisés et développés à partir des modèles Llama, démontrant ainsi la polyvalence et le potentiel de l'architecture Llama. La version Llama 4 devrait accélérer cette tendance, les chercheurs et développeurs exploitant ces modèles pour créer des applications innovantes. Cet aspect est important car Llama 4 est une version performante et permettra un large éventail d'activités de recherche et développement.
Il est important de noter que les modèles Llama 4, comme leurs prédécesseurs, sont non-penseurs. Par conséquent, les futures versions de la série Llama 4 pourraient être post-entraînées au raisonnement, améliorant ainsi leurs performances.
S'engager avec StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | Flux RSS