
Meta continua la sua innovazione nel campo dell’intelligenza artificiale attraverso investimenti strategici nell’infrastruttura hardware, cruciale per il progresso delle tecnologie di intelligenza artificiale. La società ha recentemente svelato i dettagli su due iterazioni del suo cluster su scala data center da 24,576 GPU, che è determinante nella guida di modelli IA di prossima generazione, compreso lo sviluppo di Llama 3.
Meta continua la sua innovazione nel campo dell’intelligenza artificiale attraverso investimenti strategici nell’infrastruttura hardware, cruciale per il progresso delle tecnologie di intelligenza artificiale. L'azienda ha recentemente svelato i dettagli su due iterazioni del suo cluster su scala data center da 24,576 GPU, che è determinante nella guida di modelli di intelligenza artificiale di prossima generazione, compreso lo sviluppo di Llama 3. Questa iniziativa è alla base della visione di Meta di generare sistemi aperti e costruiti in modo responsabile intelligenza generale artificiale (AGI) accessibile a tutti.
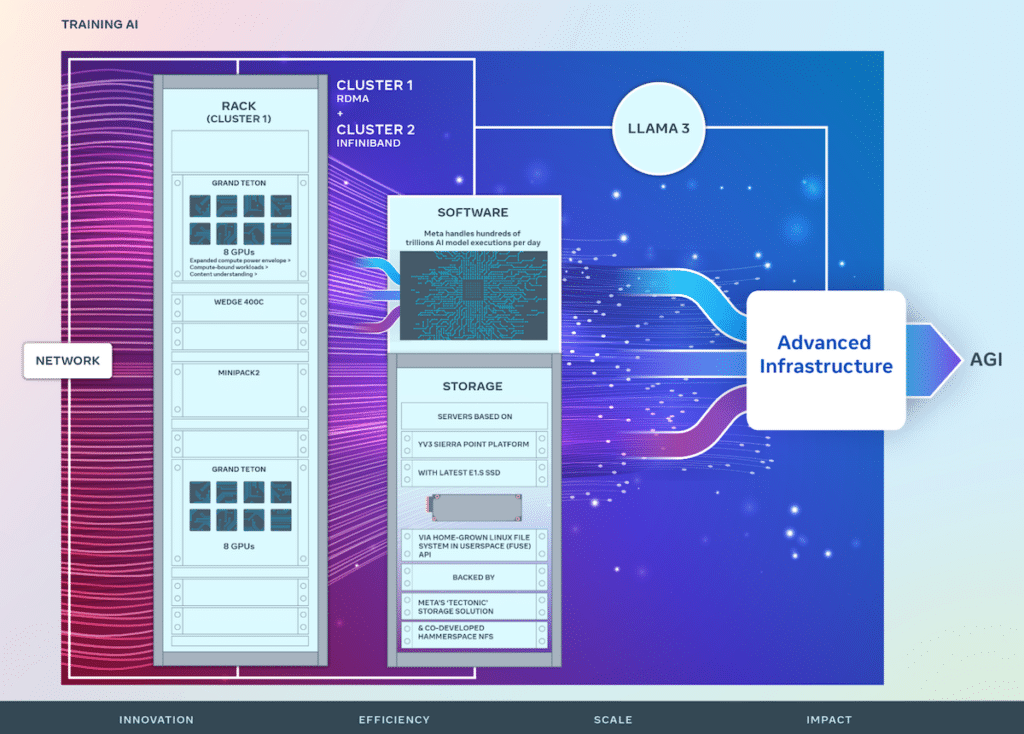
Foto per gentile concessione di META Engineering
Nel suo percorso in corso, Meta ha perfezionato il suo AI Research SuperCluster (RSC), inizialmente presentato nel 2022, con 16,000 GPU NVIDIA A100. L’RSC è stato fondamentale nel far avanzare la ricerca sull’intelligenza artificiale aperta e nel promuovere la creazione di sofisticati modelli di intelligenza artificiale con applicazioni che abbracciano molti domini, tra cui la visione artificiale, l’elaborazione del linguaggio naturale (NLP), il riconoscimento vocale e altro ancora.
Basandosi sui successi di RSC, i nuovi cluster AI di Meta migliorano lo sviluppo del sistema AI end-to-end con un'enfasi sull'ottimizzazione dell'esperienza del ricercatore e dello sviluppatore. Questi cluster integrano 24,576 GPU NVIDIA Tensor Core H100 e sfruttano i tessuti di rete ad alte prestazioni per supportare modelli più complessi di quanto possibile in precedenza, stabilendo un nuovo standard per lo sviluppo e la ricerca di prodotti GenAI.
L'infrastruttura di Meta è altamente avanzata e adattabile e gestisce quotidianamente centinaia di trilioni di esecuzioni di modelli IA. La progettazione su misura dell'hardware e dei tessuti di rete garantisce prestazioni ottimizzate per i ricercatori di intelligenza artificiale mantenendo al contempo efficienti le operazioni del data center.
Sono state implementate soluzioni di rete innovative, tra cui un cluster con accesso remoto diretto alla memoria (RDMA) su Ethernet convergente (RoCE) e un altro con struttura NVIDIA Quantum2 InfiniBand, entrambi capaci di interconnessioni a 400 Gbps. Queste tecnologie consentono scalabilità e informazioni sulle prestazioni cruciali per la progettazione di futuri cluster IA su larga scala.

Grand Teton introdotto durante l'OCP 2022
Grand Teton di Meta, una piattaforma hardware GPU aperta progettata internamente, contribuisce all'Open Compute Project (OCP) e incarna anni di sviluppo di sistemi IA. Unisce alimentazione, controllo, elaborazione e interfacce fabric in un'unità coesa, facilitando una rapida implementazione e scalabilità negli ambienti dei data center.
Affrontando il ruolo spesso sottodiscusso ma fondamentale dello storage nella formazione sull'intelligenza artificiale, Meta ha implementato un'API Linux Filesystem in Userspace (FUSE) personalizzata supportata da una versione ottimizzata della soluzione di storage distribuito "Tectonic". Questa configurazione, abbinata al file system di rete parallelo (NFS) Hammerspace co-sviluppato, fornisce una soluzione di archiviazione scalabile e ad alto rendimento essenziale per gestire le vaste richieste di dati dei lavori di formazione AI multimodali.
La piattaforma server YV3 Sierra Point di Meta, supportata dalle soluzioni Tectonic e Hammerspace, sottolinea l'impegno dell'azienda verso prestazioni, efficienza e scalabilità. Questa lungimiranza garantisce che l’infrastruttura di storage possa soddisfare le richieste attuali e scalare per soddisfare le crescenti esigenze delle future iniziative di intelligenza artificiale.
Man mano che i sistemi di intelligenza artificiale crescono in complessità, Meta continua la sua innovazione open source in hardware e software, contribuendo in modo significativo a OCP e PyTorch, promuovendo così il progresso collaborativo all’interno della comunità di ricerca sull’intelligenza artificiale.
I progetti di questi cluster di formazione AI sono parte integrante della roadmap di Meta, che mira a espandere la propria infrastruttura con l'ambizione di integrare 350,000 GPU NVIDIA H100 entro la fine del 2024. Questa traiettoria evidenzia l'approccio proattivo di Meta allo sviluppo dell'infrastruttura, pronto a soddisfare le richieste dinamiche di future ricerche e applicazioni sull’intelligenza artificiale.
Interagisci con StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS feed