
L'ultima Risultati MLPerf sono stati pubblicati, con NVIDIA che offre le massime prestazioni ed efficienza dal cloud all'edge per l'inferenza AI. MLPerf rimane una misura utile per le prestazioni dell'intelligenza artificiale come benchmark indipendente di terze parti. La piattaforma AI di NVIDIA è stata in cima alla lista per formazione e inferenza sin dalla nascita di MLPerf, inclusi gli ultimi benchmark MLPerf Inference 3.0.
L'ultima Risultati MLPerf sono stati pubblicati, con NVIDIA che offre le massime prestazioni ed efficienza dal cloud all'edge per l'inferenza AI. MLPerf rimane una misura utile per le prestazioni dell'intelligenza artificiale come benchmark indipendente di terze parti. La piattaforma AI di NVIDIA è stata in cima alla lista per formazione e inferenza sin dalla nascita di MLPerf, inclusi gli ultimi benchmark MLPerf Inference 3.0.
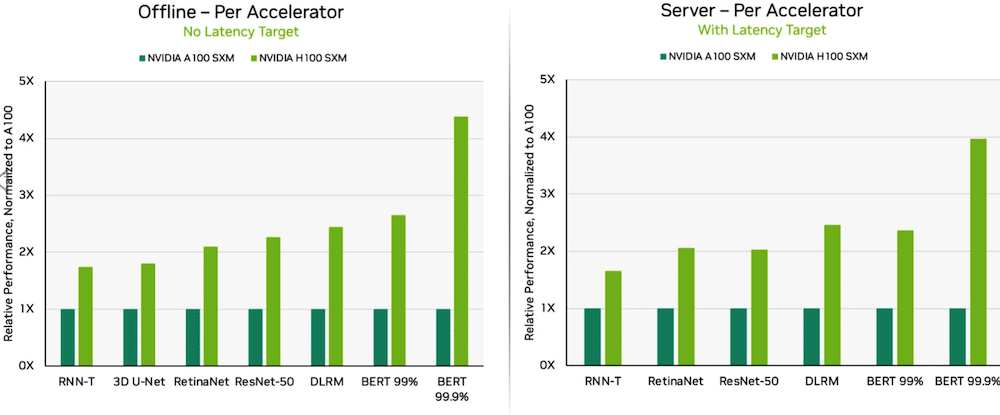
Grazie alle ottimizzazioni del software, le GPU NVIDIA H100 Tensor Core in esecuzione sui sistemi DGX H100 hanno fornito le prestazioni più elevate in ogni test di inferenza AI, con un aumento del 54% rispetto al debutto di settembre. Nel settore sanitario, le GPU H100 hanno offerto un aumento delle prestazioni del 31% su 3D-UNet, il punto di riferimento MLPerf per l'imaging medico.

Dell PowerEdge XE9680 con 8 GPU H100
Alimentata dal suo Transformer Engine, la GPU H100, basata sull'architettura Hopper, eccelleva su BERT. BERT è un modello per l'elaborazione del linguaggio naturale sviluppato da Google che apprende le rappresentazioni bidirezionali del testo per migliorare significativamente la comprensione contestuale del testo senza etichetta in molte attività diverse. È la base per un'intera famiglia di modelli simili a BERT come RoBERTa, ALBERT e DistilBERT.
Con l'intelligenza artificiale generativa, gli utenti possono creare rapidamente testo, immagini, modelli 3D e molto altro. Le aziende, dalle startup ai fornitori di servizi cloud, stanno adottando l’intelligenza artificiale generativa per abilitare nuovi modelli di business e accelerare quelli esistenti. Uno strumento di intelligenza artificiale generativa che ha fatto notizia ultimamente è ChatGPT, utilizzato da milioni di persone che si aspettano risposte immediate a seguito di domande e input.
Con il deep learning diffuso ovunque, le prestazioni in termini di inferenza sono fondamentali, dagli stabilimenti ai sistemi di raccomandazione online.
Le GPU L4 offrono prestazioni straordinarie
Nel suo viaggio inaugurale, Nvidia L4 Le GPU Tensor Core hanno prestazioni oltre 3 volte superiori rispetto alle GPU T4 della generazione precedente. Gli acceleratori GPU L4, confezionati in un fattore di forma a basso profilo, sono progettati per fornire un throughput elevato e una bassa latenza in quasi tutte le piattaforme server. Le GPU L4 Tensor hanno eseguito tutti i carichi di lavoro MLPerf e, grazie al supporto per il formato FP8, i risultati sono stati eccellenti sul modello BERT affamato di prestazioni.
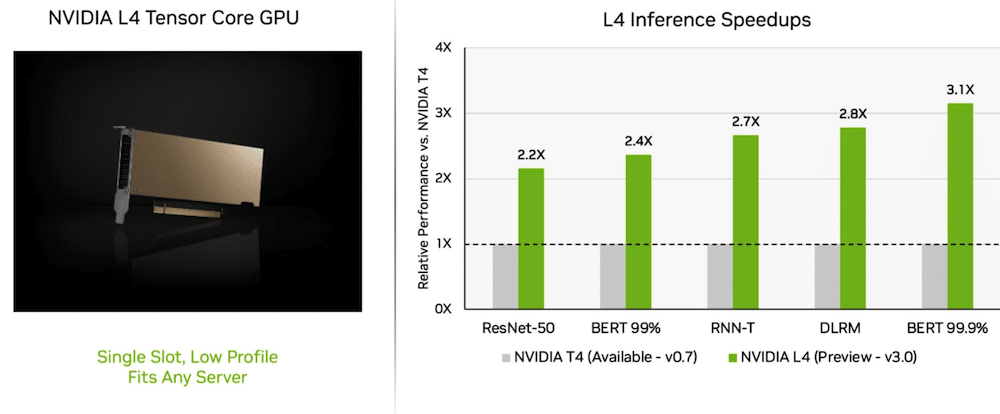
Oltre alle prestazioni AI estreme, le GPU L4 offrono una decodifica delle immagini fino a 10 volte più veloce, un'elaborazione video fino a 3.2 volte più veloce e prestazioni grafiche e di rendering in tempo reale oltre 4 volte più veloci. Gli acceleratori, annunciati al GTC un paio di settimane fa, sono disponibili presso produttori di sistemi e fornitori di servizi cloud.
Quale divisione di rete?
La piattaforma AI full-stack di NVIDIA ha dimostrato il suo valore in un nuovo test MLPerf: Network-division benchmark!
Il benchmark della divisione di rete trasmette i dati a un server di inferenza remoto. Riflette lo scenario prevalente di utenti aziendali che eseguono lavori di intelligenza artificiale nel cloud con i dati archiviati dietro firewall aziendali.
Su BERT, i sistemi remoti NVIDIA DGX A100 hanno fornito fino al 96% delle prestazioni massime locali, in parte rallentati durante l'attesa che le CPU completassero alcune attività. Nel test ResNet-50 per la visione artificiale, gestito esclusivamente da GPU, hanno raggiunto il 100%.
La rete NVIDIA Quantum Infiniband, gli SmartNIC NVIDIA ConnectX e software come NVIDIA GPUDirect hanno svolto un ruolo significativo nei risultati dei test.
Orin migliora a Edge
Separatamente, il sistema su modulo NVIDIA Jetson AGX Orin ha ottenuto miglioramenti fino al 63% in termini di efficienza energetica e fino all'81% in termini di prestazioni rispetto ai risultati dello scorso anno. Jetson AGX Orin fornisce inferenza quando è necessaria l'intelligenza artificiale in spazi ristretti a bassi livelli di potenza, compresi i sistemi alimentati a batteria.
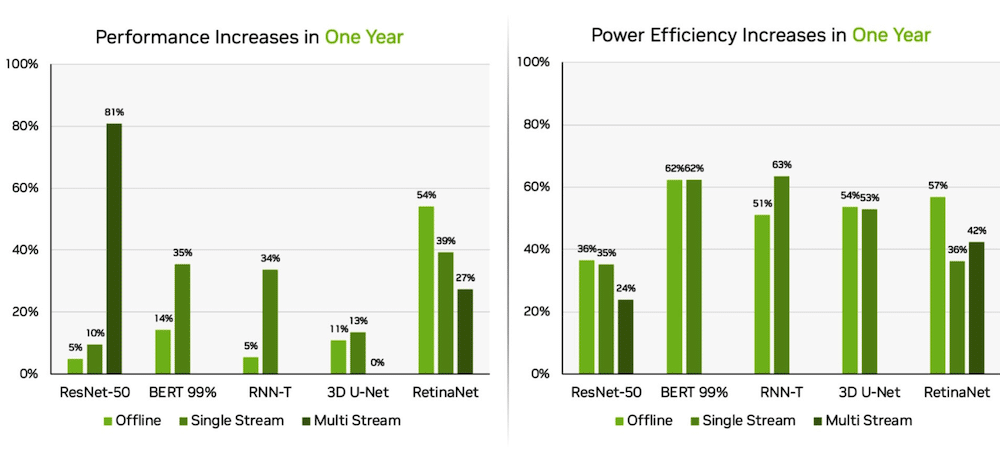
Il Jetson Orin NX 16G, un modulo più piccolo che richiede meno energia, ha ottenuto buoni risultati nei benchmark. Ha offerto prestazioni fino a 3.2 volte superiori rispetto al processore Jetson Xavier NX.
Ecosistema IA NVIDIA
I risultati di MLPerf mostrano che l'intelligenza artificiale di NVIDIA è supportata da un ampio ecosistema nel campo dell'apprendimento automatico. Dieci aziende hanno presentato risultati sulla piattaforma NVIDIA in questo round, tra cui produttori di servizi e sistemi cloud Microsoft Azure, ASUS, Dell Technologies, GIGABYTE, H3C, Lenovo, Nettrix, Supermicro e xFusion. Il loro lavoro dimostra che gli utenti possono ottenere ottime prestazioni con l'intelligenza artificiale NVIDIA sia nel cloud che nei server in esecuzione nei propri data center.
Interagisci con StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS feed