
![]() 本日の AWS グローバル サミットで、Alluxio はデータ オーケストレーション テクノロジーの最新バージョンである Alluxio 2.0 を発表しました。最新バージョンにはデータ エンジニア向けの新しいイノベーションが搭載されており、マルチクラウド分析と AI を目的としています。
本日の AWS グローバル サミットで、Alluxio はデータ オーケストレーション テクノロジーの最新バージョンである Alluxio 2.0 を発表しました。最新バージョンにはデータ エンジニア向けの新しいイノベーションが搭載されており、マルチクラウド分析と AI を目的としています。
本日の AWS グローバル サミットで、Alluxio はデータ オーケストレーション テクノロジーの最新バージョンである Alluxio 2.0 を発表しました。最新バージョンにはデータ エンジニア向けの新しいイノベーションが搭載されており、マルチクラウド分析と AI を目的としています。
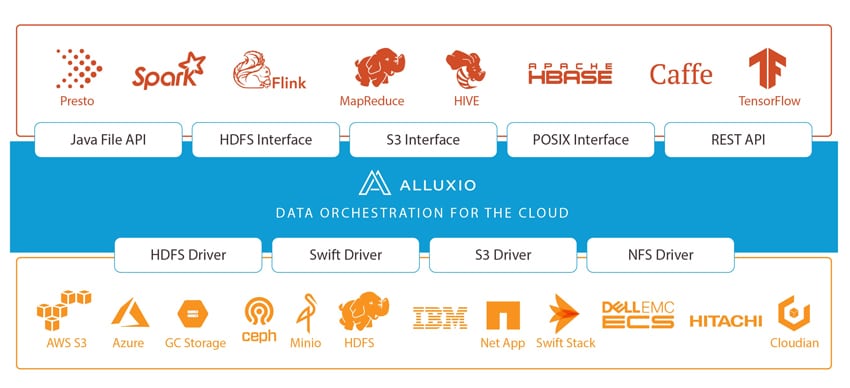
最初に述べたように、Alluxio はメモリ速度でデータを統合する世界初のシステムであると述べています。 「メモリ速度」により、企業は異種ストレージ システム間でデータに迅速にアクセスできるようになり、その結果、データをより効率的に管理し、貴重な洞察をより迅速に発見できるようになり、ハイブリッド クラウドの導入が容易になることを意味します。現在、Alluxio は、Alibaba、Baidu、Barclay's Bank、CERN、ESRI、Huawei、Intel、Juniper などの企業の重要なワークロードを実行しています。
世界はクラウドベースのコンピューティング集約型ワークロードに移行しつつあります。この新たな焦点は、コンピューティングがストレージから独立して柔軟な方法で拡張する必要があることを意味します。これにはパフォーマンスの観点からはいくつかの利点がありますが、データ エンジニアにとっては頭痛の種となる可能性があります。 Alluxio は、データ サイロ、ゾーン、リージョン、さらにはクラウド全体でのコンピューティングにデータの局所性、データ アクセシビリティ、データの弾力性をもたらす抽象化レイヤーを追加することで、この問題を解決することを目指しています。
特徴と機能は次のとおりです。
- マルチクラウド向けのデータ オーケストレーションのイノベーション:
- ポリシー主導のデータ管理
- Alluxio 2.0 には、データ エンジニアが事前定義されたポリシーに基づいてストレージ システム間のデータ移動を自動化および継続的に自動化できる新機能が含まれています。これは、データが作成され、ホット データ、ウォーム データ、コールド データが管理されるときに、Alluxio はオンプレミスおよびすべてのクラウドにわたる任意の数のストレージ システムにわたるデータの階層化を自動化できることを意味します。
- データ プラットフォーム チームは、最も重要なデータのみを高価なストレージ システムで自動的に管理し、他のデータをより安価な代替ストレージに移動することで、ストレージ コストを削減できるようになりました。
- データ アクセス ポリシーの管理の改善: ファイル レベルでのきめ細かいポリシーに加えて、ユーザーは任意のディレクトリおよびフォルダー レベルでポリシーを構成して、データへのアクセスとワークロードのパフォーマンスを合理化できるようになりました。これには、Alluxio でのデータの書き込みやストレージ システムとのデータの同期など、さまざまなコア機能における個々のデータセットの動作の定義が含まれます。
- データ サービスを介したクラウド ストレージ間での効率的なデータ移動: 新しいデータ サービスにより、AWS S3 や Google GCS などのクラウド ストア間を含む非常に効率的なデータ移動が可能になり、オブジェクト ストレージでの高価な操作がコンピューティング フレームワークにシームレスに適用されます。
- ポリシー主導のデータ管理
- クラウド分析向けに最適化されたデータ アクセスをコンピューティング:
- コンピューティング中心のクラスター パーティショニング: ユーザーは、各フレームワークまたはワークロードのデータセットが他のフレームワークやワークロードによって汚染されないように、任意のディメンションに基づいて単一の Alluxio をパーティショニングできるようになりました。最も一般的な使用法には、Spark、Presto などのフレームワークによるクラスターのパーティション分割が含まれます。さらに、これにより、データ転送コストが削減され、データが特定のゾーンまたはリージョン内に留まるように制限されます。
- REST を介した外部データ ソースとの統合: ユーザーは、Web ベースのデータ ソースからもデータを取り込んで、Alluxio に集約して分析を実行できるようになりました。ファイルのある Web の場所は、単純に Alluxio を指すようにして、クエリまたはモデルの実行に基づいて必要に応じて取り込むことができます。
- その他の機能には以下が含まれます:
- 高度に分散されたデータ サービス – 2.0 では、分散クラスター サービスである Alluxio データ サービスが導入され、レプリケーションや永続化などのデータ操作により、高いパフォーマンスと大規模なスケールが可能になります。
- データの局所性を高めるためのアダプティブ レプリケーション – Alluxio に保存されている、自動的に管理されるデータのコピー数の範囲を設定する新機能。
- 埋め込みジャーナルによる高可用性 – RAFT コンセンサス アルゴリズムを使用し、他の外部ストレージ システムから独立した埋め込みジャーナルと呼ばれる、ファイルとオブジェクトのメタデータに対する新しいフォールト トレランスおよび高可用性モード。これは、オブジェクト ストレージを抽象化する場合に特に役立ちます。
- Alluxio POSIX API – Alluxio の FUSE 機能により、POSIX 互換 API が有効になり、Tensorflow、Caffe、その他の Python ベースのモデルなどのフレームワークが、従来のファイル システム アクセスを使用して Alluxio 経由で任意のストレージ システムのデータに直接アクセスできるようになります。
- アマゾン AWS サポート:
- AWS Elastic Map Reduce (EMR) サービス統合: ユーザーが分析ワークロードや AI ワークロードをデプロイするためにクラウド サービスに移行するにつれて、AWS EMR などのサービスの使用が増えています。 Alluxio を AWS EMR クラスターにシームレスにブートストラップできるようになり、Spark、Presto、Hive フレームワークの EMR 内のデータレイヤーとして利用できるようになりました。ユーザーは、EMR で維持されるデータ コピーを削減しながら、S3 またはリモート データからデータをキャッシュするための高パフォーマンスの代替手段を利用できるようになりました。
利用状況
Alluxio 2.0 Community Edition と Enterprise Edition の両方が現在利用可能です。
この話を話し合う
StorageReview ニュースレターにサインアップする