
 Permabit Albireo SANblox は、ファイバー チャネル SAN からより多くの容量を解放するように設計された専用のデータ削減アプライアンスです。 Permabit では、ユーザーは SAN 上に存在するデータ フットプリントが少なくとも 6:1 削減され、ストレージへの投資により標準的な価値提案が大幅に変更されると推定しています。 SANblox は、シン プロビジョニングによる重複排除と圧縮を提供し、機能セットをさらに強化します。データ削減はすべてインラインで行われ、SANblox アプライアンスは単に SAN の前に差し込まれて仮想化されます。SAN とアプリケーションは SANblox ソリューションの存在を意識しません。 SANblox は、ディスク構成に関係なく、あらゆる FC ストレージで動作します。ハード ドライブ、ハイブリッド、およびオールフラッシュ ソリューションはすべて、同じようにデータ フットプリントを削減します。
Permabit Albireo SANblox は、ファイバー チャネル SAN からより多くの容量を解放するように設計された専用のデータ削減アプライアンスです。 Permabit では、ユーザーは SAN 上に存在するデータ フットプリントが少なくとも 6:1 削減され、ストレージへの投資により標準的な価値提案が大幅に変更されると推定しています。 SANblox は、シン プロビジョニングによる重複排除と圧縮を提供し、機能セットをさらに強化します。データ削減はすべてインラインで行われ、SANblox アプライアンスは単に SAN の前に差し込まれて仮想化されます。SAN とアプリケーションは SANblox ソリューションの存在を意識しません。 SANblox は、ディスク構成に関係なく、あらゆる FC ストレージで動作します。ハード ドライブ、ハイブリッド、およびオールフラッシュ ソリューションはすべて、同じようにデータ フットプリントを削減します。
Permabit Albireo SANblox は、ファイバー チャネル SAN からより多くの容量を解放するように設計された専用のデータ削減アプライアンスです。 Permabit では、ユーザーは SAN 上に存在するデータ フットプリントが少なくとも 6:1 削減され、ストレージへの投資により標準的な価値提案が大幅に変更されると推定しています。 SANblox は、シン プロビジョニングによる重複排除と圧縮を提供し、機能セットをさらに強化します。データ削減はすべてインラインで行われ、SANblox アプライアンスは単に SAN の前に差し込まれて仮想化されます。SAN とアプリケーションは SANblox ソリューションの存在を意識しません。 SANblox は、ディスク構成に関係なく、あらゆる FC ストレージで動作します。ハード ドライブ、ハイブリッド、およびオールフラッシュ ソリューションはすべて、同じようにデータ フットプリントを削減します。

6 倍のデータ削減は、標準的なエンタープライズ混合アプリケーション ワークロードの良い指標として広く受け入れられています。ただし、ストレージの使用状況によっては、この数値がさらに大きくなる可能性があります。 VDI のユースケースでは、SANblox のメリットを桁違いに高めることができ、たとえば、開発にデータベースの複数のコピーを使用する IT ショップでは、データ フットプリントが大幅に削減されます。実際、開発目的でデータのコピーをスピンオフできるだけで、以前は完全なデータ セットを展開するコストが高すぎた可能性がある新しいビジネス プロセスが可能になる可能性があります。
一方、Permabit は、重複排除ビジネスに長年取り組んできました。データ削減は最近までバックアップ アプライアンス以外ではあまり普及していませんでしたが、フラッシュ ベースのアプライアンスにより、この概念がより主流のワークロードに浸透しました。これらのオールフラッシュ アプライアンスの多くを支える重複排除テクノロジーは、おそらくパーマビット ソリューションです。ただし、重複排除がどこでも行われているわけではありません。ハード ドライブ アレイやほとんどのハイブリッドでさえ、その概念を念頭に置いて構築されておらず、多くのフラッシュ アレイでさえ、限られたデータ削減サービスを提供しています。 Permabit は、SANblox アプライアンスを介してこれらのサービスを開き、新規または既存のストレージに新しい一連のトリックを提供します。

Permabit Albireo SANblox は現在、ユニットがペアになっているストレージ ベンダーおよびプロモーション価格によって異なる MSRP で出荷されています。明らかに、価格設定に関する議論は、容量がスケールメリットを得るのに十分な大きさである場合に最もうまく機能します。 Permabit には、従来のフラッシュ ストレージが SANblox を使用した環境とどのように比較されるかを示す価格の例が含まれています。
- 未処理の 60 TB のコスト: 720,000 ドル
- データ保護オーバーヘッド後のコスト: 12 ドル/GB
- SANblox 6:1 容量削減のコスト: 70,000 ドル
- データ保護オーバーヘッドを除いた 10 TB のコスト: 120,000 ドル
- 割引前の総費用: $190,000
- 割引前の GB あたりの実効費用(ストレージ + sanblox): 3.16 ドル
- 純節約率: 74%
パーマビット Albireo SANblox 仕様
- CPU: インテル Xeon E5-1650v2
- RAM:128 GB
- FC ポート: 4 x 16 Gb (Emulex)
- 最大。使用可能な容量: 256 TiB
- 最大。サポートされるLUN: 256
- ランダム IO (4K IOPS):
- 読む:230,000
- 書き込み:111,000
- 混合 RW70: 180,000
- シーケンシャルスループット:
- 読み取り: 1045MB/秒
- 書き込み: 800MB/秒
- 最小レイテンシ:
- 読み取り: 300us
- 書き込み: 400us
- 信頼性: すべてのデータ/メタデータは、書き込みが確認される前にバックエンド ストレージに書き込まれます。 SANblox にはデータはキャッシュされません。
- 可用性: シームレスな高可用性により、30 秒以内に透過的なフェイルオーバーが実現します。
- 保守性: SMTP アラートと、ソフトウェアおよびハードウェア コンポーネントの透過的なアップグレード。
- 物理特性:
- フォームファクタ: 1U ラックマウント
- 幅:17.2」(437さmm)
- 重量:38ポンド(16.5kg)
- 力:
- 電圧: 100-240V、50-60Hz
- ワット:330
- アンペア: 最大4.5
- 動作温度: 10°C ~ 35°C (50°F ~ 95°F)
- 動作相対湿度: 8% ~ 90% (結露なきこと)
- 認定証
- 電磁放射: FCC クラス A、ICES-003、CISPR 22 クラス A、AS/NZS CISPR 22 クラス A、EN 61000-3-2/-3-3、VCCI:V-3、KN22 クラス A
- 電磁耐性: CISPR 24、KN 24、(EN 61000-4-2、EN 61000-4-3、EN 61000-4-4、EN 61000-4-5、EN 61000-4-6、EN 61000-4-) 8、EN 61000-4-11)
- 電源効率: 80 Plus Gold 認定
重複排除
重複排除は、単に重複データがプライマリ ストレージの貴重なスペースを占有することを防ぐプロセスです。購入者によっては、バックアップ専用のデータ削減アプライアンスを購入する場合と、プライマリ ストレージ用に設計されたデータ削減アプライアンスを購入する場合の違いが混乱する場合があります。データ削減を備えたプライマリ ストレージは、固定サイズのデータ ブロックへのランダム アクセスのパフォーマンスの提供を最適化するように設計されています。より高速なパフォーマンスを実現するために、プライマリ ストレージのデータ削減はデータの固定チャンク、通常はより多くのより小さなブロックに焦点を当てます (ただし、特定のベンダーによって異なります)。一方、重複排除バックアップ アプライアンスは、バックアップおよび復元プロセスを高速化するために、シーケンシャル スループットに重点を置いています。バックアップ重複排除アプライアンスは、シーケンシャル フォーカスにより、大量のデータ ストリームを処理し、可変チャンク サイズでメディアに書き込むことができます。これは、一方では、アプライアンスがより大きなチャンクを使用できるため、追跡するチャンクが少なくなることを意味します。一方、読み戻す必要があるデータが少量の場合は、チャンク全体を読み取る必要があります。
重複排除に関しては、インラインまたはポストプロセスという 2 つの主な実行方法があります。インライン重複排除とは、データがターゲットに向かって移動するときに重複が検出され、その後書き込まれないことを単に意味します。インラインであるため、ハイブリッド アレイ内のキャッシュと高速ストレージの層はすべて、有効容量の増加による恩恵を受けます。これは、ディスク領域を節約するだけでなく、フラッシュ メディアへの書き込みを節約するという点でも理想的です (フラッシュは、劣化が始まる前に非常に多くの書き込みしか実行できないため)。これらの利点に加えて、インラインではデータ保護のための即時レプリケーションも可能になります。インライン重複排除の欠点は、ほぼ避けられない、書き込みチューン時のパフォーマンスへの影響です。
ポストプロセス重複排除とは、データがストレージ ターゲットに到達したとき、またはストレージ キャッシュに到達したときに重複排除プロセスが開始されることを意味します。これにより、書き込み時の初期パフォーマンスの低下を回避できますが、他の問題が発生します。 1 つは、重複排除プロセスが開始されるのを待機している間、または重複排除プロセスが常に実行されている場合はそれに追いつくまでの間、重複がストレージ領域を占有していることです。データが最初にキャッシュに送信されると、キャッシュが急速にいっぱいになる可能性があります。その結果、ハイブリッド アレイでは最下位層でのみ容量が節約される可能性があります。重複排除の前に最初にすべてをストレージ メディアに書き込むと、フラッシュに大きな負担がかかる可能性もあります。また、最初のパフォーマンス ヒットはスキップされる可能性がありますが、ポストプロセスが開始されると、重複排除プロセスは引き続きリソースを使用する必要があります。
ベンダーの観点からすると、通常、パフォーマンスが最大の懸念事項となります。なぜなら、ベンダーは(たとえ全体的に使用するディスク容量が少なくなるとしても)競合他社よりもアプライアンスの動作が遅くなるのを望まないからです。パフォーマンスのヒットと全体的なパフォーマンスの上限は、利用可能なリソースと特定のアプライアンス内で使用されている特定のソフトウェアの組み合わせによって決まります。顧客にとってパフォーマンスも大きな懸念事項となる可能性がありますが、重複排除プロセスによってデータの保存方法とデータの最初の書き込み方法が変化するため、データ損失も心配しています。
それでは、この重複排除の違いの中で Permabit はどこに当てはまるのでしょうか?パーマビットは SAN の前に配置され、データがターゲットに向かって移動するときにデータの重複を排除します。 Permabit は、インライン、マルチコア、スケーラブル、メモリ オーバーヘッドの低い重複排除方法を使用します。私たちがテストしているデバイスである Permabit Albireo SANblox を特に見てみると、プライマリ ストレージ環境で 4K 粒度で重複排除が必要なデータにインデックスを付けることができます。そのため、Permabit Albireo SANblox は、256 TB のプロビジョニング済み LUN を受け入れ、2.5 PB の論理ストレージとして提供できますが、それを実現できるのはわずか 128 GB の RAM です。これにより、デバイスは、より少ないデータ チャンクを読み戻すことと、より少ないリソースを使用することの両方によってパフォーマンスの側面に取り組むことができます。パーマビットのパフォーマンスに対処するもう 600,000 つの方法は、そのソフトウェアをアプライアンスに組み込むことです。 Permabit によれば、この方法を使用した顧客は XNUMX IOPS を超えるパフォーマンスを達成したとのことです。
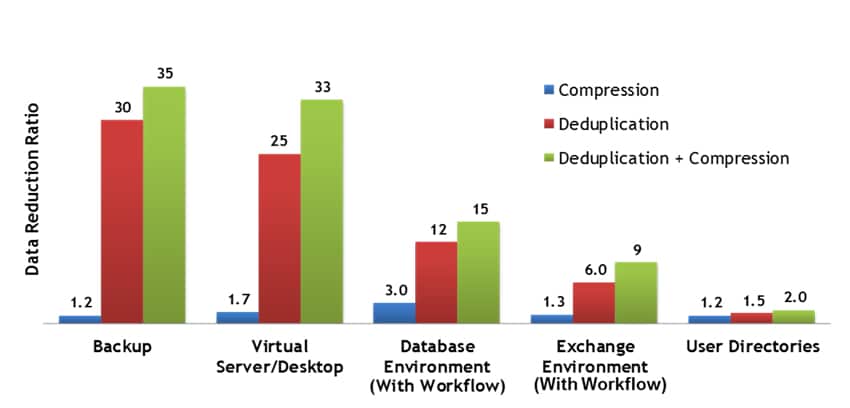
どの企業にとっても、そのデバイス (この場合は重複排除) の機能が素晴らしいと言うのは簡単です。ただし、顧客や Permabit と SAN アプライアンスの組み合わせを検討しているベンダーが理解できる文脈で何らかの証拠を提供できれば、常に良いことになります。数年前、パーマビットは Enterprise Strategy Group (ESG) と調査を実施しました。この調査では、さまざまな環境でのデータ削減率を調査し、圧縮のみ、重複排除のみ、圧縮と重複排除の組み合わせを比較しました。
セットアップと構成
SANblox アプライアンスは、基本的にルーティングされる LUN のデータ パスに自身を挿入する 1U サーバーです。もちろん、すべての LUN が SANblox を通過する必要があるわけではありません。 SANblox ユニットは通常、HA ペアで導入され、基盤となるストレージのニーズや機能に応じて、複数の HA ペアを使用してストレージやパフォーマンスの要件に対処できます。
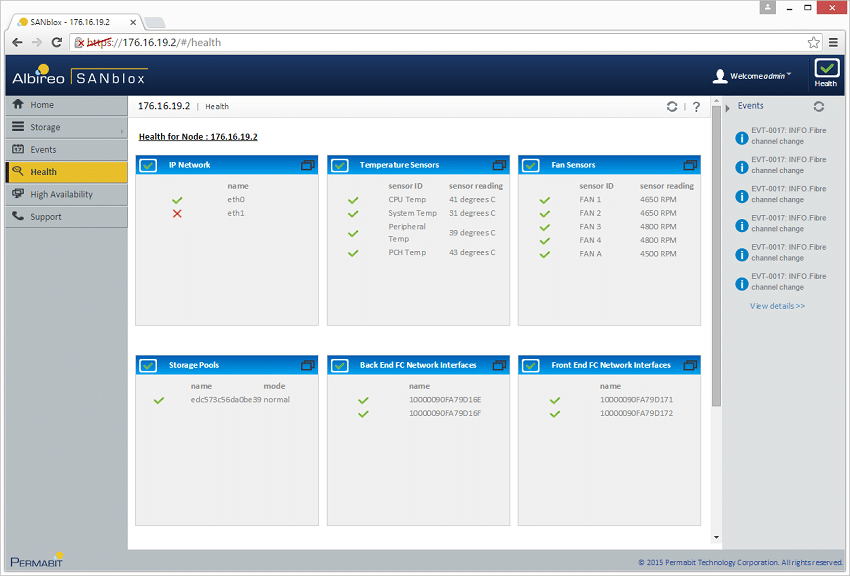
SANblox をオンラインにするには、非常に迅速かつ簡単です。システムに 2 つの IP アドレスを割り当てます。1 つは IPMI 用、もう 1 つはウェブ管理と SSH インターフェース用です。オンラインになったら、2 つのバックエンド FC ポート (ストレージ システムに接続するポート) の WWN を取得し、それらを使用して別の FC ゾーンを作成します。
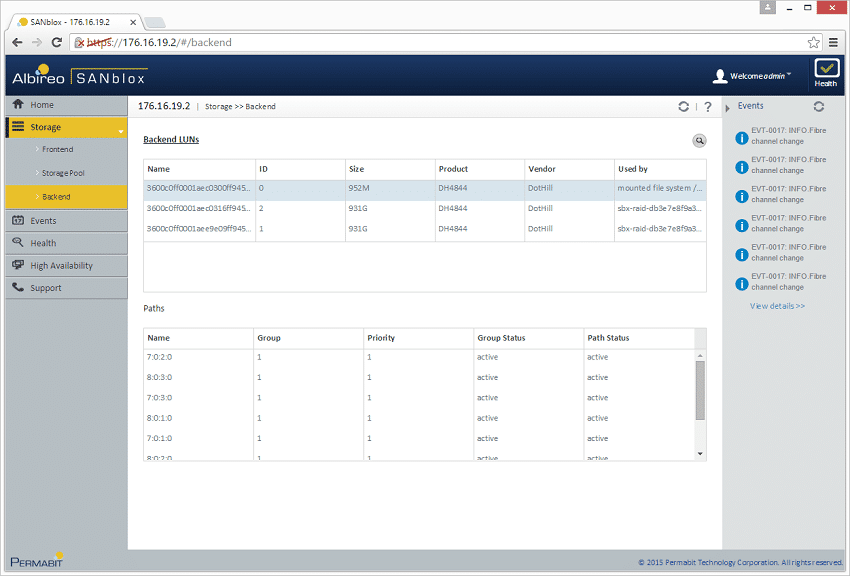
アレイ レベルでは、デバイス設定用に 1 GB の LUN を 48 つ、プライマリ データ ストレージ用に複数の LUN を使用できるようにストレージをプロビジョニングします。すべてのメタデータもこれらのボリュームに保存され、SANblox はアプライアンス内にデータを保持しません。これは、同期インライン機能によって可能になります。スクリーンショットの例では、DotHill Ultra1 アレイを使用し、SANblox 設定用に 1 つの 2GB LUN を構成し、SANblox ストレージ プール用に 1 つの XNUMXTB LUN を構成しました。
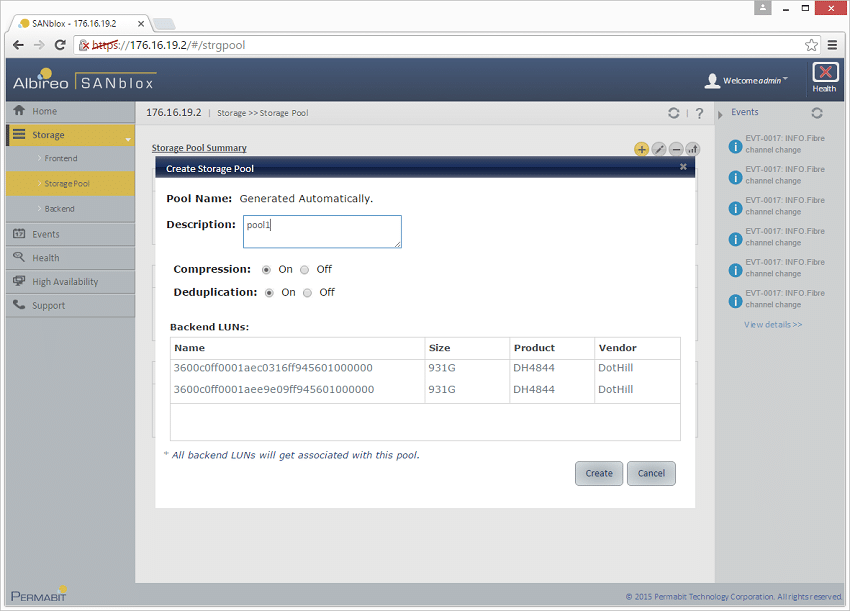
ストレージが構成されていると、SANblox はデバイス設定用に 1GB LUN を使用して自動的に検出および構成し、ストレージ プール作成用に他の LUN を表示します。この場合、プールの作成時にそれらすべてがグループ化され、重複排除のオンまたはオフ、および圧縮のオンまたはオフを選択できるようになります。
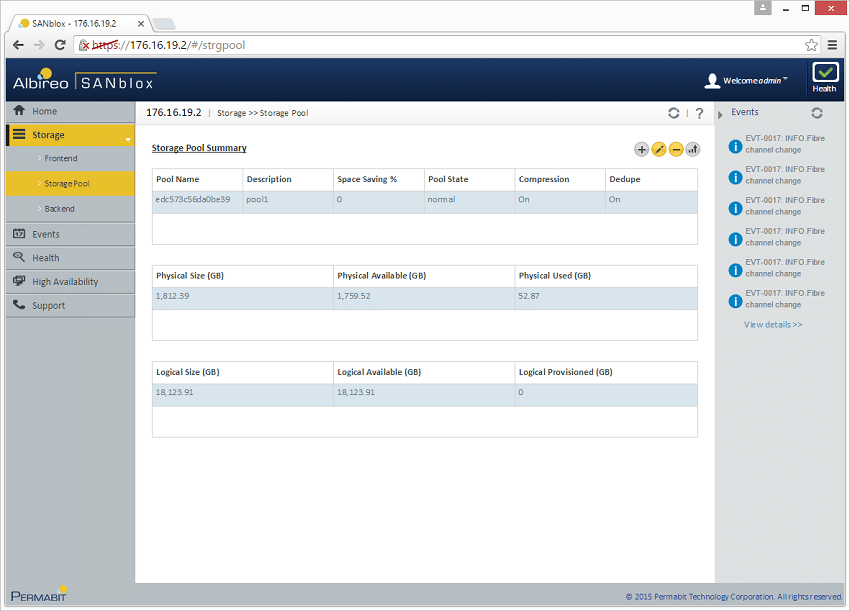
プールが作成されると、Permabit SANblox はデフォルトで、ユーザーが 10:1 の論理アドレス可能サイズで物理ストレージをアドレス指定できるようになります。したがって、ボリュームを作成すると、1TB raw は 10TB の使用可能なスペースになります。私たちの場合、1.8 TB の未加工ストレージが、割り当て可能な 18 TB の使用可能なストレージとしてマッピングされました。
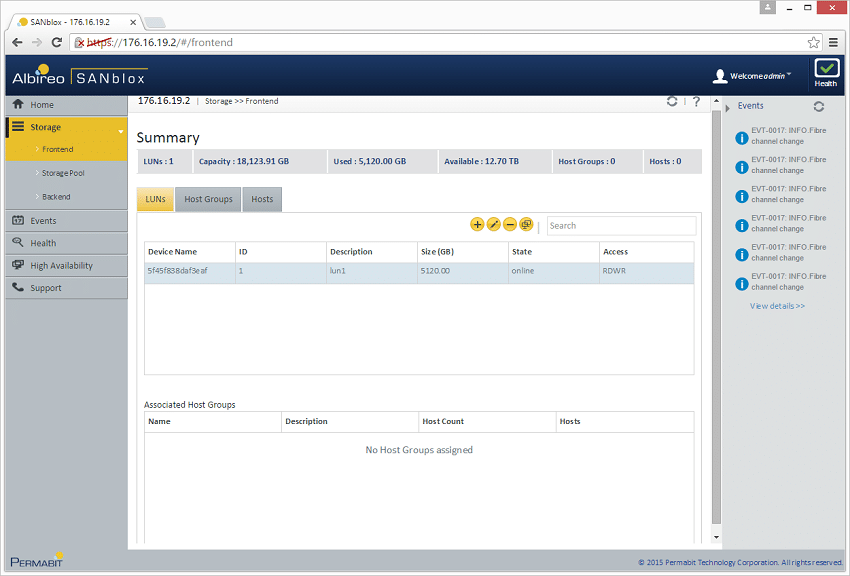
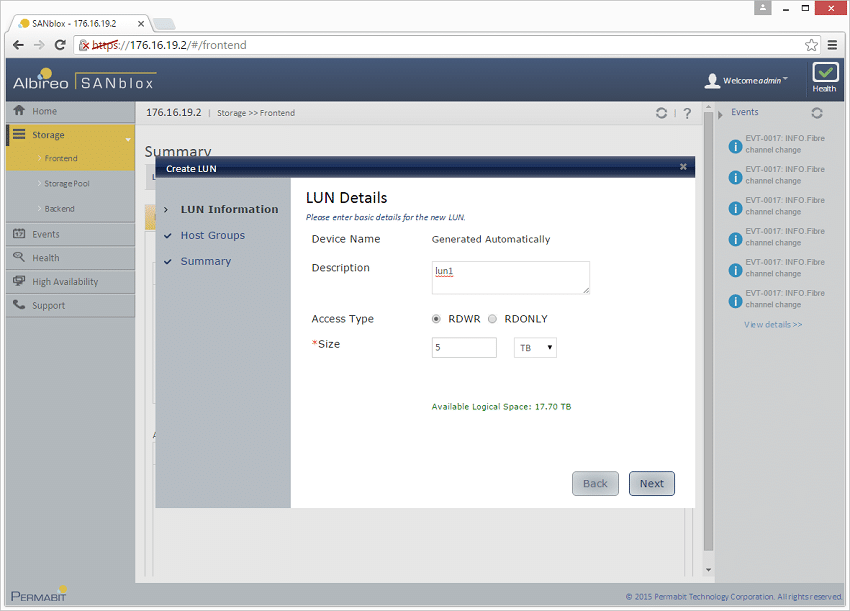
基盤となるストレージが整理されると、残りのインターフェイスは基本的なストレージ アレイと同様に機能します。 LUN を作成してホストまたはホスト グループに割り当てたり、読み取り専用アクセスや読み取り/書き込みアクセスなどのルールを定義したりできます。
パフォーマンス
すべての高性能ストレージが重複排除を提供するわけではありません。 X-IO ISE G3 ファミリのフラッシュ アレイは良い例であり、最近レビューされました。 X-IO ISE860 主にパフォーマンス演劇として設計されています。 X-IO は、あまり多くの機能を重ねないようにするという意識的な決定を下しました。これらの機能はすべて、より多くの RAM と CPU を必要とする一方で、最先端のパフォーマンスを提供するアレイの能力を低下させます。そうは言っても、アプリケーションが容量とパフォーマンスをトレードオフする必要があるユースケースがあり、TB あたりのフラッシュのコストが依然として比較的高いため、重複排除により、コストの問題に対処し、高いパフォーマンス特性を維持するのに十分なほどパフォーマンス ストレージの経済性が劇的に変化します。これを背景として、私たちは ISE 860 の前に SANblox を導入して、その機能を評価しました。重複排除がアプリケーションのパフォーマンスにどのような影響を与えるかに主な焦点を当て、Microsoft SQL Server、MySQL Sysbench、および VMware VMmark のテスト環境を活用して、単一の SANblox アプライアンスに負荷を与えました。これらの各テストは、特定のストレージ アレイに同時にアクセスする複数の同時ワークロードで動作し、Permabit SANblox などのデータ削減システムに、展開されたワークロードのデータ フットプリントを削減する素晴らしい機会を与えます。
重複排除とパフォーマンスに関して理解する必要がある重要な要素の 1 つは、データ フットプリントを削減すると、バックエンド ストレージの I/O 負荷も増加するということです。送信するデータが以前よりはるかに少なくなるため、多くの場合スループットは低下しますが、小さなブロックのランダム I/O リクエストは大幅に増加します。これが、DR とフラッシュがうまく連携できる理由の 1 つですが、特定のシナリオでは、特定の時点でバックエンド ストレージが飽和する可能性があり、今後も飽和する可能性があることも意味します。幸いなことに、SANblox の特許取得済みテクノロジーにより、データ削減のオーバーヘッドが最小限に抑えられ、他のアプリケーションでアレイを拡張したりネイティブに使用したりする余地が残されています。多くの I/O の可能性がある大規模な環境またはプラットフォームの場合、ユーザーは SANblox アプライアンスの数を拡張してパフォーマンスと容量を向上させることができます。レビュー対象のアプライアンスは 1 つだけでしたが、1 つだけではなく 2 つのペアを連携させた方がより高いパフォーマンスが測定された可能性が高くなります。
StorageReview の Microsoft SQL Server OLTP テスト プロトコル は、複雑なアプリケーション環境で見られるアクティビティをシミュレートするオンライン トランザクション処理ベンチマークである、トランザクション処理パフォーマンス評議会のベンチマーク C (TPC-C) の最新草案を採用しています。 TPC-C ベンチマークは、データベース環境におけるストレージ インフラストラクチャのパフォーマンスの強みとボトルネックを測定するのに、合成パフォーマンス ベンチマークよりも近くなります。
このテストでは、Windows Server 2014 R2012 ゲスト VM 上で実行される SQL Server 2 を使用し、Dell の Benchmark Factory for Databases によって負荷がかかります。このベンチマークの従来の使用法は、ローカル ストレージまたは共有ストレージ上の大規模な 3,000 スケールのデータベースをテストすることでしたが、このイテレーションでは、内部の総パフォーマンスをより適切に示すために、1,500 つの 860 スケールのデータベースを X-IO ISE 4 全体に均等に分散することに焦点を当てています。 XNUMX ノードの VMware クラスター。
第 2 世代 SQL Server OLTP ベンチマーク ファクトリ LoadGen 機器
- Dell PowerEdge R730 VMware ESXi vSphere 仮想クライアント ホスト (2)
- クラスター内の 5 GHz 用の 2690 つの Intel E3-124 v2.6 CPU (ノードごとに 12 つ、30 GHz、XNUMX コア、XNUMX MB キャッシュ)
- 512GB RAM (ノードあたり 256GB、16GB x 16 DDR4、CPU あたり 128GB)
- SDカードブート(Lexar 16GB)
- 2 x Mellanox ConnectX-3 InfiniBand アダプター (vMotion および VM ネットワーク用の vSwitch)
- 2 x Emulex 16GB デュアルポート FC HBA
- 2 x Emulex 10GbE デュアルポート NIC
- VMware ESXi vSphere 6.0/Enterprise Plus 4-CPU
- Dell PowerEdge R730 仮想化 SQL 4 ノード クラスター
- クラスター内の 5 GHz 用の 2690 つの Intel E3-249 v2.6 CPU (ノードごとに 12 つ、30 GHz、XNUMX コア、XNUMX MB キャッシュ)
- 1TB RAM (ノードあたり 256GB、16GB x 16 DDR4、CPU あたり 128GB)
- SDカードブート(Lexar 16GB)
- 4 x Mellanox ConnectX-3 InfiniBand アダプター (vMotion および VM ネットワーク用の vSwitch)
- 4 x Emulex 16GB デュアルポート FC HBA
- 4 x Emulex 10GbE デュアルポート NIC
- VMware ESXi vSphere 6.0/Enterprise Plus 8-CPU
各 SQL Server VM は 100 つの vDisk で構成されており、500 つはブート用に 16 GB、もう 64 つはデータベースとログ ファイル用に XNUMX GB です。システム リソースの観点から、各 VM に XNUMX 個の vCPU、XNUMX GB の DRAM を構成し、LSI Logic SAS SCSI コントローラーを活用しました。
SQL TPC-C ワークロードを X-IO ISE 860 で実行した場合と Permabit SANblox 経由で実行した場合の TPS パフォーマンスの変化を見ると、低下は 12,564 から 12,431TPS とかなり小さかったです。
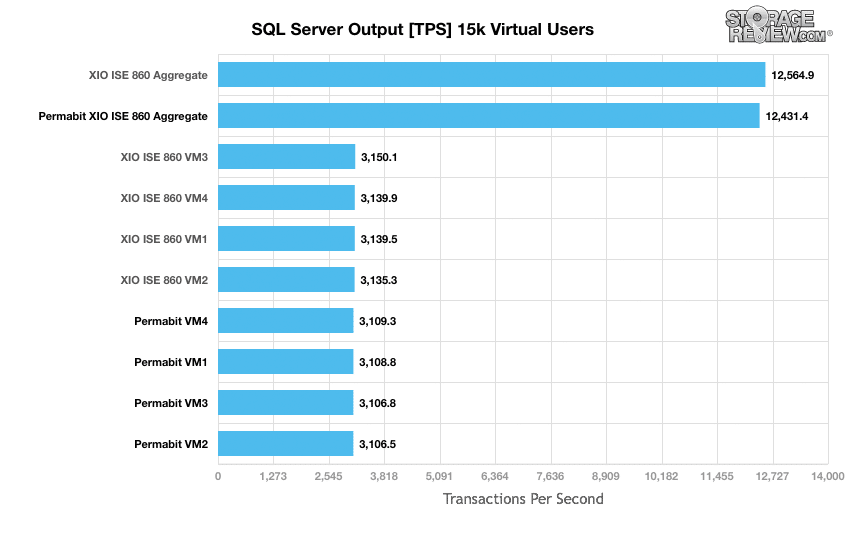
ワークロードにおけるデータ削減の影響が見られますが、焦点はトランザクション パフォーマンスからレイテンシーに変わります。 SANblox を介してワークロードが動作すると、レイテンシーは平均 13 ミリ秒から平均 84 ミリ秒に増加しました。 5.5倍弱のジャンプです。 Permabit 氏は、単一の SANblox ペアの最大負荷に近づいている可能性があり、ワークロードをわずかに減らすか、XNUMX 番目の SANblox を追加することで平均レイテンシーを大幅に短縮できる可能性があると説明しました。
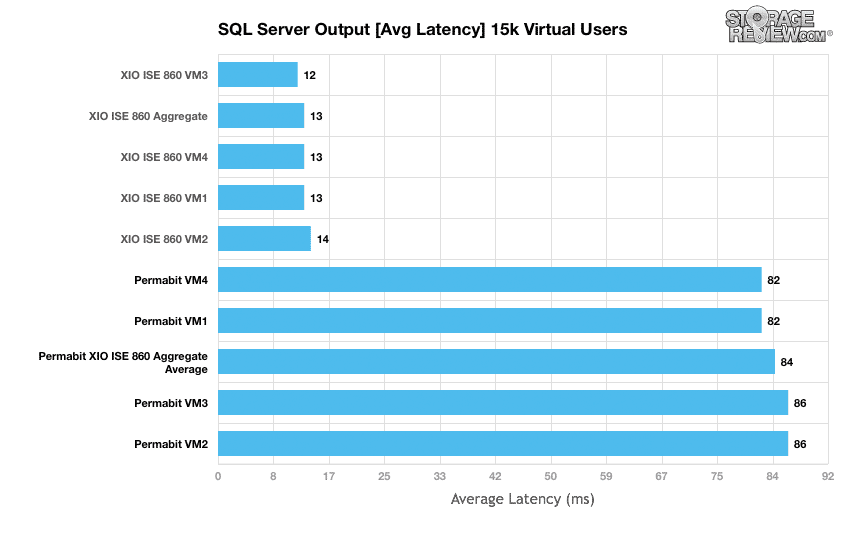
この システムベンチOLTP ベンチマークは、CentOS インストール内で動作する InnoDB ストレージ エンジンを利用して、Percona MySQL 上で実行されます。従来の SAN のテストを新しいハイパーコンバージド ギアと連携させるために、ベンチマークの多くを大規模な分散モデルに移行しました。主な違いは、ベアメタル サーバー上で 4 つのベンチマークを実行するのではなく、そのベンチマークの複数のインスタンスを仮想化環境で実行するようになったことです。そのために、X-IO ISE 8 上に 860 台と 1 台の Sysbench VM をノードごとに 2 ~ 4 台ずつ展開し、すべてを同時に動作させた状態でクラスター上で見られる合計パフォーマンスを測定しました。 8 および XNUMXVM が生のフラッシュ アレイとパーマビット SANblox の両方でどのように動作するかをプロットしました。
Dell PowerEdge R730 仮想化 Sysbench 4 ノード クラスター
- クラスター内の 5 GHz 用の 2690 つの Intel E3-249 v2.6 CPU (ノードごとに 12 つ、30 GHz、XNUMX コア、XNUMX MB キャッシュ)
- 1TB RAM (ノードあたり 256GB、16GB x 16 DDR4、CPU あたり 128GB)
- SDカードブート(Lexar 16GB)
- 4 x Mellanox ConnectX-3 InfiniBand アダプター (vMotion および VM ネットワーク用の vSwitch)
- 4 x Emulex 16GB デュアルポート FC HBA
- 4 x Emulex 10GbE デュアルポート NIC
- VMware ESXi vSphere 6.0/Enterprise Plus 8-CPU
各 Sysbench VM は 92 つの vDisk で構成されており、447 つはブート用 (~400 GB)、16 つは事前構築済みデータベース (~64 GB)、XNUMX 番目はテストするデータベース用 (XNUMX GB) です。システム リソースの観点から、各 VM に XNUMX 個の vCPU、XNUMX GB の DRAM を構成し、LSI Logic SAS SCSI コントローラーを活用しました。
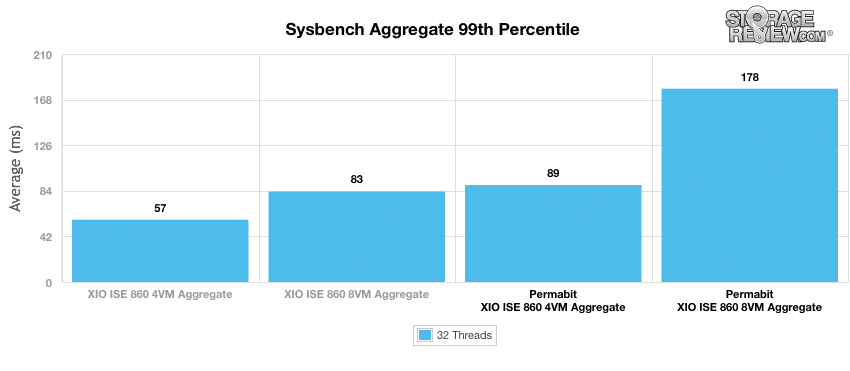
当社の Sysbench テストでは、平均 TPS (99 秒あたりのトランザクション数)、平均レイテンシー、および 32 スレッドのピーク負荷における平均 XNUMX パーセンタイル レイテンシーを測定します。
860VM ワークロードを備えた X-IO ISE 8 上でネイティブに実行されている Sysbench では、クラスター全体で合計 6,568TPS を測定しました。 SANblox をミックスに追加すると、2,971TPS に低下しました。 4VM の負荷では、低下は少なくなり、4,424TPS から 2,752TPS まで下がりました。どちらの場合も、データ削減アプライアンスを介した操作のオーバーヘッドはそれぞれ 55% と 38% を占めました。ただし、このオーバーヘッドの数値は、ストレージ アレイから提供される LUN には直接影響しませんが、重要な側面が XNUMX つあります。外部システムとしてユーザーは、データ削減によるコスト上の利点がなくても、優先度の高いトラフィックをアレイ自体にルーティングすることを選択できます。
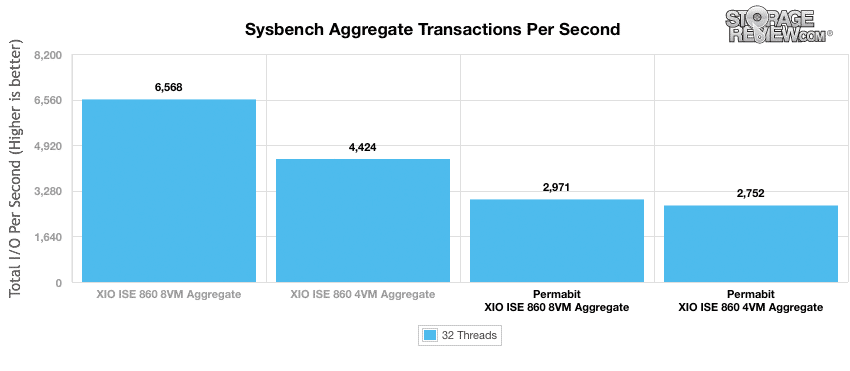
構成間の平均レイテンシを比較すると、4VM の平均レイテンシは 29 ミリ秒から 47 ミリ秒に増加し、8VM の平均レイテンシは 39 ミリ秒から 86 ミリ秒に増加しました。
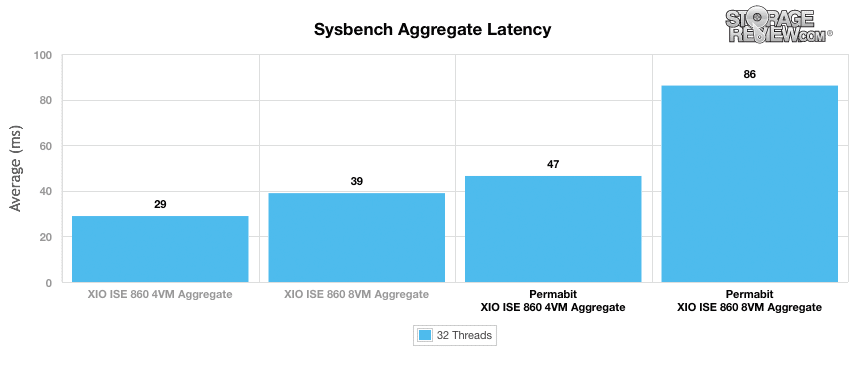
SANblox を環境に追加した場合の 99 パーセンタイル レイテンシを確認すると、57 VM では 89 ミリ秒から 4 ミリ秒へ、83 VM では 178 ミリ秒から 8 ミリ秒への増加が測定されました。
VMmark パフォーマンス分析
すべてのアプリケーション パフォーマンス分析と同様に、当社は、実際の運用環境で製品がどのようにパフォーマンスを発揮するかを、企業のパフォーマンスに関する主張と比較して示すことを試みます。当社は、大規模システムのコンポーネントとしてストレージを評価することの重要性、最も重要なのは、主要なエンタープライズ アプリケーションと対話する際のストレージの応答性を評価することの重要性を理解しています。このテストでは、 VMware による VMmark 仮想化ベンチマーク マルチサーバー環境の場合。
VMmark はその設計上、リソースを大量に消費するベンチマークであり、ストレージ、ネットワーク、コンピューティング アクティビティに重点を置く VM ベースのアプリケーション ワークロードが幅広く混在しています。仮想化パフォーマンスのテストに関しては、これより優れたベンチマークはほとんどありません。VMmark はストレージ I/O、CPU、さらには VMware 環境のネットワーク パフォーマンスに至るまで、非常に多くの側面を調査しているからです。
Dell PowerEdge R730 VMware VMmark 4 ノード クラスタの仕様
- Dell PowerEdge R730 サーバー (x4)
- CPU: 5 基の Intel Xeon E2690-3 v2.6 12GHz (24C/XNUMXT)
- メモリ: 64 x 16GB DDR4 RDIMM
- Emulex LightPulse LPe16002B 16Gb FC デュアルポート HBA
- Emulex OneConnect OCe14102-NX 10Gb イーサネット デュアルポート NIC
- VMwareのESXiの6.0
ISE 860 G3(DataPac あたり 20×1.6TB SSD)
- RAID前: 51.2TB
- RAID 10 容量: 22.9TB
- RAID 5 容量: 36.6TB
- 定価:575,000ドル
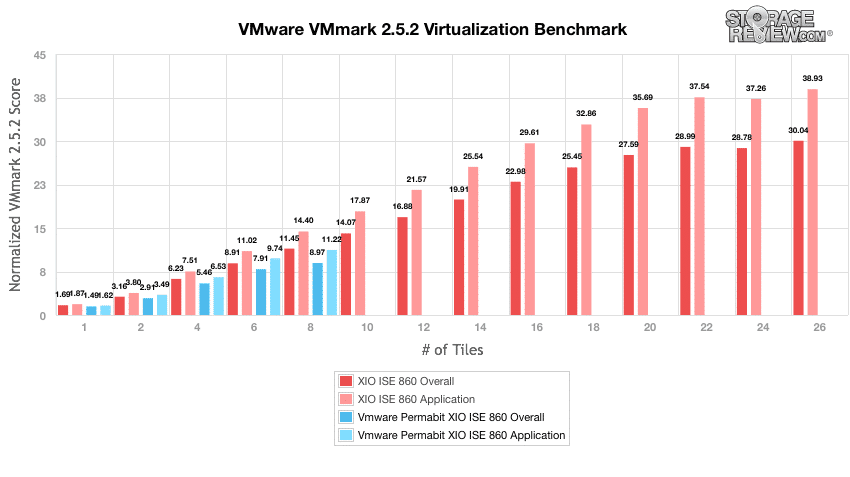
VMware の VMmark を使用したテスト用に Permabit SANblox を構成する際、データの分散方法を最適化しました。従来、特定のアレイでは、VM は「全か無か」構成でデプロイされます。これは、データ全体がテスト対象のストレージ アレイに完全に移動されることを意味します。 SANblox をストレージ デバイスの前に配置する独自の方法により、一部の書き込み集中型のワークロードにはストレージを直接利用できるだけでなく、大部分の OS ディスクや VMmark ワークロードには SANblox を介して重複排除を節約することができました。私たちの特定の構成では、X-IO ISE 40 上に直接配置した個々の 860GB メールサーバー メールボックス vDisk を除き、すべての VM を SANblox に移行しました。
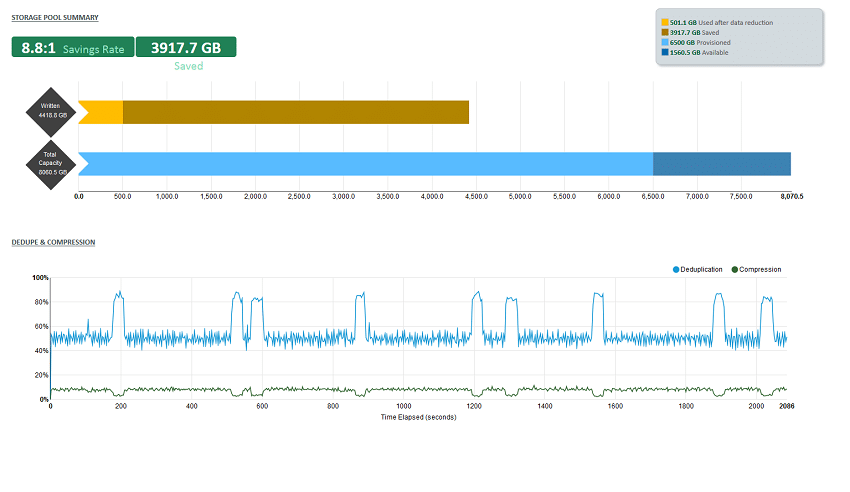
最適化された構成により、X-IO ISE 8 の前に Permabit SANblox を使用して VMmark で合計 860 タイルに到達することができました。これと比較すると、以前にアレイ上で直接ホストされていた場合のピークは 26 タイルでした。パフォーマンスの観点から見ると、SANblox 経由でワークロードを実行すると、70% のオーバーヘッドが発生しました。ただし、データ削減の観点から見ると、消費されるスペースは 1 タイルのままでした。追加のタイルをアレイに移行しても、消費されるスペースには目立った影響はありませんでした。これは、SANblox アプライアンスの 2 番目の HA ペアがあると全体的なパフォーマンスが向上する XNUMX つのシナリオです。
まとめ:
Permabit Albireo SANblox は、組織のデータ フットプリントを大幅に削減することで多大なメリットをもたらす、導入が簡単なアプライアンスです。 Permabit は、Albireo SANblox を任意のファイバー チャネル SAN の前に設置することができ、顧客はデータ フットプリントを最大 6:1 削減できると述べています。データ削減はすべて、SANblox の存在を意識せずに SAN とインラインで行われます。 SANblox は、一般的な 6:1 のデータ削減に加えて、シン プロビジョニングと圧縮も提供します。 Permabit は、重複排除の分野で長年にわたり広く評価されている名前であり、ワークロードに応じて、顧客が潜在的に大幅なフットプリント削減を実現できるように支援します。
一見、重複排除は素晴らしいように思えます。組織は、購入したストレージを重複でいっぱいにするのではなく最大限に活用でき、古いディスクベースのストレージでも新たな命を吹き込むことができます。 Permabit Albireo SANblox がその後の構成に関係なく機能するという事実も、それを考慮すべきもう 1 つの輝かしい理由です。重複排除の最大の欠点は、必ずパフォーマンスに影響が出るということです。場合によっては、パフォーマンスへの影響がかなり重大になる可能性があります。潜在的な顧客は、これを取引の決定要因として捉えるのではなく、生のオールフラッシュと比較するとパフォーマンスは低下しますが、それでも同様の価格帯で販売されている従来の HDD ストレージ アレイよりも高速であることを理解する必要があります。
ストレージ投資をすべて活用するよりも、超高性能と超低遅延が必要な場合は、重複排除をスキップする必要があります。ただし、企業がパフォーマンスの低下に耐え、定義されたパラメータ内で機能できる場合は、ぜひ Permabit Albireo SANblox などのデバイスを検討する必要があります。妥協点もあります。3 番目のオプションは、本番データを重複排除なしで通過させながら、パフォーマンスにそれほど重要ではないデータ (開発など) を SANblox 経由で実行することです。当社のパフォーマンス結果をどのように見るかについても、同様の考え方が必要です。この比較は、「SANblox なしで X-IO のパフォーマンスがどれだけ向上するかを確認する」というよりは、SAN に重複排除を適用したときに期待できるパフォーマンスの種類を示す方法です。
前述したように、ストレージ スタックへのアプライアンスの追加は、多くの変数によって異なります。最終的に Permabit が提供するのは、特にワークロードにパフォーマンスのニーズがない場合に、ストレージ容量と寿命の延長です。開発のためにデータベースをスピンアップするなどのタスクが標準的な慣行になりつつある今日の IT 環境では、SANblox を使用すると、データ フットプリントのペナルティなしでこれが可能になります。企業への統合も簡単で、チューニングやカスタマイズが必要な場合でも、アプライアンスでそれが可能です。
メリット
- ストレージアーキテクチャへのシンプルな統合
- 最新の開発慣行と一致
- LUNごとにオン/オフ可能
デメリット
- 重複排除にはオーバーヘッドがあり、レイテンシに敏感なアプリケーションはアプライアンスをバイパスする必要がある場合があります
ボトムライン
Permabit Albireo SANblox は既存のシステムに簡単に統合でき、インライン データ削減を実行できるため、組織はストレージ投資の可能性を最大限に活用できます。データ削減をオンまたはオフにしたり、パフォーマンスと容量の両方を最大化するために特定のワークロードのみに適用したりできます。
Permabit Albireo SANblox 製品ページ
このレビューについて話し合う
StorageReview ニュースレターにサインアップする