
MarkLogic 6 is an Enterprise NoSQL (“Not Only SQL”) database that has the flexibility and scalability to handle today’s data challenges that SQL-based databases were not designed to handle. It also has enterprise-grade capabilities like search, ACID transactions, failover, replication, and security to run mission-critical applications. MarkLogic combines database functionality, search, and application services in a single system. It provides the functionality enterprises need to deliver value. MarkLogic leverages existing tools, knowledge, and experience while providing a reliable, scalable, and secure platform for mission-critical data.
![]()
Companies and organizations across industries including the public sector, media, and financial services have benefited from MarkLogic’s unique architecture. Any environment that faces a combination of data volume, velocity, variety, and complexity—a data challenge known as Big Data—can be enhanced with MarkLogic. Example solutions built on MarkLogic include intelligence analysis, real-time decision support, risk management, digital asset management, digital supply chain, and content delivery.
MarkLogic Benchmark
The benchmark we are utilizing is internally developed by MarkLogic and is used to evaluate both hardware configurations and upcoming MarkLogic software releases. The workload is divided into two distinct parts:
- Ingestion phase where a large data set is inserted with indexes into the MarkLogic database.
- Query phase where searches, views updates, and deletes are applied to the inserted data set. These queries also use MarkLogic features such as facets, pagination and bookmarks.
The corpus used is the publicly available Wikipedia xml collection. Files are held on disk in zipped format. For ingestion we use MarkLogic Content Pump (mlcp).
The ingestion phase in particular is I/O intensive. I/O is broken down into three categories:
- Initially documents are ingested into in-memory stands and the only disk writes are Journal saves.
- In-memory stands quickly overflow and are continually written as on-disk stands. This is saving activity.
- As the number of on-disk stands increase, MarkLogic must merge them to reduce query overhead. Merging involves reading multiple on-disk stands, writing back a merged single version and deleting the originals.
To ensure the highest level of accuracy and to force each device into steady-state, we repeat the ingestion and query phases 24 times for flash-based devices. For PCIe Application Accelerators, each interval takes between 60-120 minutes to complete, thus putting the total test time into a range of 24-48 hours. For devices with lower I/O throughput, the total test time can span days. Our focus in this test is to look at overall latency from each storage solution across four areas of interest: journal writes (J-lat), save writes (S-lat), as well as merge read (MR-lat) and merge write latency (MW-lat).
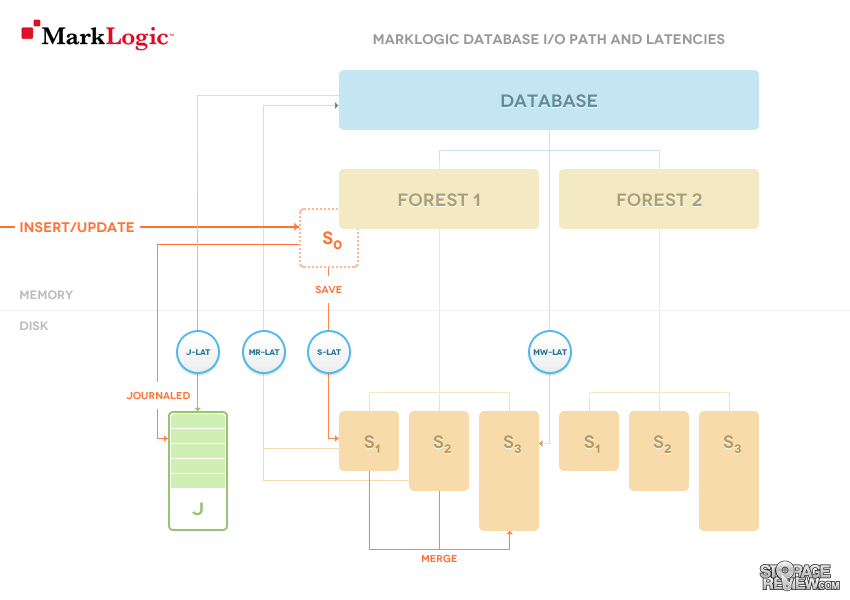
In the diagram above we see the I/O paths and latencies in MarkLogic:
- Journal writes record the deltas to the database. When an update request runs, all the changes it made to the state of the database are recorded in the journal. Those changes can be applied again from the journal, without running the request again. Updates can be additions, replacements or deletions of documents. The journal protects from outages, it is guaranteed to survive a system crash thereafter. The latency of Journal writes is captures in the J-lat metric
- After enough documents are loaded, the in-memory stand will fill up and be flushed to disk, written out as an on-disk stand. This flush to disk is called a Save. The latency of Save writes is captured in S-lat
- As the total number of on-disk stands grows, an efficiency issue threatens to emerge. To read a single term list, MarkLogic must read the term list data from each individual stand and unify the results. To keep the number of stands to a manageable level, MarkLogic runs merges in the background. A merge reads (Merge Read) some of the stands on disk and creates a new singular stand out of them Merge Write), coalescing and optimizing the indexes and data, as well as removing any previously deleted fragments. The latency of Merge reads is captured in MR-lat and the latency of Merge writes in MW-lat.
During ingestion, MarkLogic also indexes all of the documents, creates term lists, etc. This activity requires CPU cycles which make the benchmark a good balance between high I/O and high CPU utilization.
The Wikipedia data was also chosen because it contains non-English and non-ASCII text of which we use: Arabic, Dutch, French, German, Italian, Japanese, Korean, Persian, Portuguese, Russian, Spanish, Simplified Chinese and Traditional Chinese. These options stress the multilingual features of MarkLogic. Finally, the static data ingested makes the benchmark repeatable which is essential for performance comparisons across multiple software versions’ varying hardware configurations.
MarkLogic Testing Environment
Storage solutions are tested with the MarkLogic NoSQL benchmark in the StorageReview Enterprise Test Lab utilizing multiple servers connected over a high-speed network. We utilize servers from EchoStreams and Lenovo for different segments of the MarkLogic NoSQL Testing Environment, and for the fabric that connects the equipment, we use Mellanox InfiniBand Switching and NICs.
The storage solution is broken up into three sections: the storage host, the MarkLogic NoSQL Database Cluster, and the MarkLogic Database Client. For the storage host, we use a 2U Lenovo ThinkServer RD630 to present PCIe Application Accelerators, groups of four SATA/SAS SSDs, and a host for NAS/SAN equipment to present them on the InfiniBand fabric. For the MarkLogic Database Cluster, we use an EchoStreams GridStreams quad-node server equipped with eight Intel Xeon E5-2640 CPUs to provide the compute resources needed to effectively stress the fastest storage devices. On the client side, we use 1U Lenovo ThinkServer RD530 servers that provide the working data that are loaded into system memory and pushed to the NoSQL Database cluster over our high-speed network. Linking all of these servers together is a Mellanox 56Gb/s InfiniBand fabric including both switch and NICs that give us the highest transfer speeds and lowest latency to not limit the performance of high-performance storage devices.
Mellanox InfiniBand interconnects were used to provide the highest performance and greatest network efficiency to ensure that the devices connected are not network-limited. Looking at just PCIe storage solutions, a single PCIe Application Accelerator can easily drive more 1-3GB/s onto the network. Ramp up to an all-flash storage appliance with peak transfer speeds in excess of 10-20GB/s and you can quickly see how network link capacity can be easily saturated, limiting the overall performance of the entire platform. InfiniBand’s high-bandwidth links allow for the greatest amount of data to be moved over the least number of links, allowing for the full system capabilities to be realized.
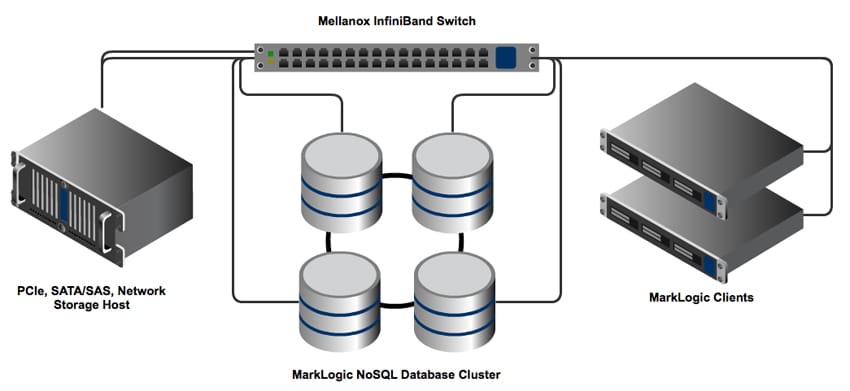
In addition to higher network throughput, InfiniBand also enables higher overall cluster efficiency. InfiniBand uses iSER (iSCSI-RDMA) and SRP (SCSI RDMA Protocol) to replace the inefficient iSCSI TCP stack with Remote Direct Memory Access (RDMA) functionality, allowing near-native access times for external storage. iSER and SRP enable greater efficiency throughout the clustered environment by allowing network traffic to bypass the systems’ CPUs and allowing data to be copied from the sending systems’ memory directly to the receiving systems’ memory. In comparison, traditional iSCSI operation routes network traffic through a complex multiple-copy and transfer process, eating up valuable CPU cycles and memory space, and drastically increasing data transfer latencies. In our MarkLogic NoSQL environment, we utilize the SCSI RDMA Protocol to connect each node to a SCSI target subsystem for Linux (SCST) running on our storage host.
MarkLogic Benchmark Equipment
- EchoStreams GridStreams Quad-Node Database Cluster
- Eight Intel E5-2640 CPUs (Two per node, 2.5GHz, 6-cores, 15MB Cache)
- 256GB RAM (64GB per node, 8GB x 8 Micron DDR3, 32GB per CPU)
- 4 x 100GB Micron RealSSD P400e (One per node, on-board SATA)
- 4 x Mellanox ConnectX-3 InfiniBand Adapter
- CentOS 6.3
- Lenovo ThinkServer RD530 Database Client
- Dual Intel E5-2640 CPUs (2.5GHz, 6-cores, 15MB Cache)
- 64GB RAM (8GB x 8 Micron DDR3, 32GB per CPU)
- 200GB x 3 Toshiba 10k SAS RAID5 (via LSI 9260-8i)
- 1 x Mellanox ConnectX-3 InfiniBand Adapter
- CentOS 6.3
- Lenovo ThinkServer RD630 Storage Host
- Dual Intel E5-2680 CPUs (2.7GHz, 8-cores, 20MB Cache)
- 32GB RAM (8GB x 4 DDR3, 16GB per CPU)
- 100GB Micron RealSSD P400e SSD (via LSI 9207-8i)
- 1 x Mellanox ConnectX-3 InfiniBand Adapter
- CentOS 6.3
- External JBOD: iXsystems Titan iX-316J
- Mellanox SX6036 InfiniBand Switch
- 36 FDR (56Gb/s) ports
- 4Tb/s aggregate switching capacity
The main goal with this platform is highlighting how enterprise storage performs in an actual enterprise environment and workload, instead of relying on synthetic or pseudo-synthetic workloads. Synthetic workload generators are great at showing how well storage devices perform with a continuous synthetic I/O pattern, but they don't take into consideration any of the other outside variables that show how devices actually work in production environments. Synthetic workload generators have the benefit of showing a clean I/O pattern time and time again, but will never replicate a true production environment. Introducing application performance on top of storage products begins to show how well the storage interacts with its drivers, the local operating system, the application being tested, the network stack, the networking switching, and external servers. These are variables that a synthetic workload generator simply can't take into account, and are also an order of magnitude more resource and infrastructure intensive in terms of the equipment required to execute this particular benchmark.
MarkLogic Performance Results
We test a wide range of storage solutions with the MarkLogic NoSQL benchmark that meet the minimum requirements of the testing environment. To qualify for testing, the storage device must have a usable capacity exceeding 650GB and be geared towards operating under stressful enterprise conditions. This includes new PCIe Application Accelerators, groups of four SAS or SATA enterprise SSDs, as well as large HDD arrays that are locally or network attached. Listed below are the overall latency figures captured from all devices tested to date in this test. In product reviews we dive into greater detail and put competing products head to head while our main list shows the stratification of different storage solutions.
| Device | Overall Average Latency | S-lat | J-lat | MR-lat | MW-lat |
|---|---|---|---|---|---|
| Dell R720 ExpressFlash 350GB JBOD x 4 (SLC) |
1.24 | 1.56 | 1.56 | 0.46 | 1.37 |
| Huawei Tecal ES3000 2.4TB 4 Partitions (MLC) |
1.31 | 1.41 | 1.53 | 0.98 | 1.32 |
| Huawei Tecal ES3000 1.2TB 4 Partitions (MLC) |
1.43 | 1.42 | 1.76 | 1.20 | 1.33 |
| EchoStreams FlacheSAN2 w/ Intel SSD 520 S/W RAID0, 4 groups of 8 180GB SSDs (MLC) |
1.48 | 1.65 | 2.01 | 0.81 | 1.46 |
| Micron P320h 700GB 4 Partitions (SLC) |
1.49 | 1.62 | 2.13 | 0.79 | 1.41 |
| Fusion ioDrive2 Duo MLC 2.4TB S/W RAID0, High-Performance Mode, 4 Partitions (MLC) |
1.70 | 1.73 | 2.57 | 0.97 | 1.51 |
| Fusion ioDrive2 Duo SLC 1.2TB S/W RAID0, High-Performance Mode, 4 Partitions (SLC) |
1.72 | 1.78 | 2.69 | 0.90 | 1.52 |
| OCZ Z-Drive R4 1.6TB 4 Partitions (MLC) |
1.73 | 1.67 | 2.38 | 1.43 | 1.42 |
| Hitachi Ultrastar SSD400S.B 400GB JBOD x 4 (SLC) |
1.77 | 1.75 | 2.72 | 1.11 | 1.51 |
| Smart Optimus 400GB JBOD x 4 (MLC) |
1.82 | 1.69 | 2.74 | 1.36 | 1.49 |
| EchoStreams FlacheSAN2 w/ Intel SSD 520 S/W RAID10, 4 groups of 8 180GB SSDs (MLC) |
2.02 | 2.12 | 3.02 | 1.17 | 1.79 |
| Virident FlashMAX II 2.2TB High-Performance Mode, 4 Partitions (MLC) |
2.26 | 2.30 | 3.39 | 1.57 | 1.81 |
| Hitachi Ultrastar SSD400M 400GB JBOD x 4 (MLC) |
2.58 | 2.09 | 4.49 | 2.07 | 1.68 |
| OCZ Talos 2 400GB JBOD x 4 (MLC) |
2.62 | 2.10 | 4.33 | 2.28 | 1.78 |
| Intel DC S3700 200GB JBOD x 4 (MLC) |
3.27 | 2.71 | 5.80 | 2.59 | 1.95 |
| OCZ Talos 2 200GB JBOD x 4 (MLC) |
3.53 | 2.62 | 6.16 | 3.40 | 1.96 |
| Intel SSD 910 800GB Non-RAID, JBOD x 4 (MLC) |
4.29 | 3.21 | 8.27 | 3.43 | 2.23 |
| Fusion ioDrive2 MLC 1.2TB S/W RAID0, High-Performance Mode, 4 Partitions (MLC) |
4.69 | 3.58 | 9.15 | 3.74 | 2.28 |
| OCZ Deneva 2 200GB JBOD x 4 (MLC) |
6.65 | 5.38 | 13.48 | 4.54 | 3.18 |
| Kingston E100 200GB JBOD x 4 (MLC) |
8.00 | 6.82 | 16.22 | 5.46 | 3.49 |
| Smart CloudSpeed 500 240GB JBOD x 4 (MLC) |
11.06 | 9.07 | 22.74 | 7.19 | 5.23 |
| Micron P400m 400GB JBOD x 4 (MLC) |
12.60 | 9.70 | 27.51 | 8.70 | 4.51 |
| Fusion ioDrive Duo MLC 1.28TB S/W RAID0, High-Performance Mode, 4 Partitions (MLC) |
12.89 | 10.52 | 26.77 | 9.70 | 4.58 |
| Micron P400m 200GB JBOD x 4 (MLC) |
14.98 | 11.99 | 31.93 | 10.54 | 5.46 |
| Toshiba 15K MK01GRRB 147GB H/W LSI 9286-8e x 16, RAID10 x 4 |
16.58 | 7.85 | 40.61 | 12.25 | 5.61 |
| LSI Nytro WarpDrive 800GB 4 Partitions (MLC) |
17.39 | 17.08 | 31.42 | 13.63 | 7.43 |
| Toshiba 10K MBF2600RC 600GB H/W LSI 9286-8e x 16, RAID10 x 4 |
24.20 | 10.89 | 57.94 | 20.61 | 7.35 |
| Toshiba 15K MK01GRRB 147GB S/W RAID x 16, RAID10 x 4 |
61.40 | 54.33 | 126.77 | 45.21 | 19.28 |