
NVIDIA took advantage of SC22 to make announcements highlighting a new wave of HPC innovation that enables breakthrough scientific discoveries. NVIDIA highlighted Quantum-2, Omniverse, HPC at the edge, and Digital Twin Simulation. Here’s the NVIDIA compilation.
NVIDIA took advantage of SC22 to make announcements highlighting a new wave of HPC innovation that enables breakthrough scientific discoveries. NVIDIA highlighted Quantum-2, Omniverse, HPC at the edge, and Digital Twin Simulation. Here’s the NVIDIA compilation.
First up is the announcement that there has been broad adoption of its next-generation H100 Tensor Core GPUs and Quantum-2 InfiniBand, including new offerings on Microsoft Azure cloud and more than 50 new partner systems for accelerating scientific discovery.

NVIDIA released significant updates to its cuQuantum, CUDA, and BlueField DOCA acceleration libraries and announced support for its Omniverse simulation platform on NVIDIA A100- and H100-powered systems. H100, Quantum-2, and the library updates are all part of NVIDIA’s HPC platform. The HPC platform includes a full technology stack with CPUs, GPUs, DPUs, systems, networking, and a broad range of AI and HPC software providing researchers the ability to efficiently accelerate their work on powerful systems, on-premises, or in the cloud.
Azure Offers NVIDIA Quantum-2 for HPC Workloads
Microsoft Azure’s adoption of the Quantum-2 InfiniBand networking platform followed NVIDIA Quantum-2’s general availability announced at GTC in March.
New Servers Turbocharged With H100, NVIDIA AI
ASUS, Atos, Dell, HPE, Lenovo, and Supermicro are just a few of the NVIDIA partners to announce H100-powered servers. A five-year license for NVIDIA AI Enterprise is included with every H100 PCIe GPU. This ensures organizations have access to the AI frameworks and tools needed to build H100-accelerated AI solutions, from medical imaging to weather models to safety alert systems and more.

Among the wave of new systems is the Dell PowerEdge XE9680, also announced during SC22, which tackles the most demanding AI and high-performance workloads. This is Dell’s first eight-way system based on the NVIDIA HGX platform purpose-built for convergence of simulation, data analytics, and AI.
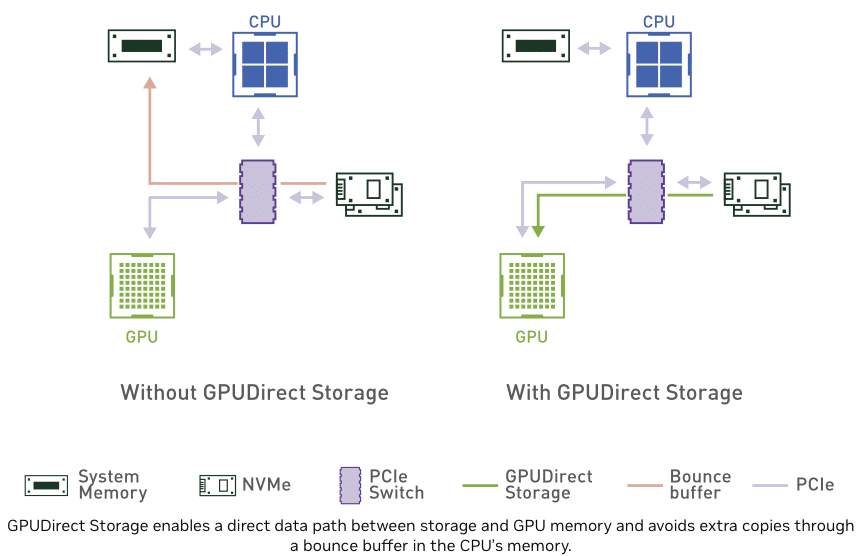
The PowerEdge XE8640, Dell’s new HGX H100 system with four Hopper GPUs, enables businesses to develop, train, and deploy AI and machine learning models. A 4U rack system, the XE8640 delivers faster AI training performance and increased core capabilities with up to four PCIe Gen5 slots, NVIDIA Multi-Instance GPU (MIG) technology and NVIDIA GPUDirect Storage support.
Major Updates to Acceleration Libraries
To help boost scientific discovery, NVIDIA has released significant updates to its CUDA, cuQuantum, and DOCA acceleration libraries, including:
- NVIDIA CUDA libraries now include a multi-node, multi-GPU Eigensolver enabling unprecedented scale and performance for leading HPC applications like VASP, a package for first-principles quantum mechanical calculations.
- The NVIDIA cuQuantum software development kit for accelerating quantum computing workflows now supports approximate tensor network methods. This allows researchers to simulate tens of thousands of qubits and automatically enables multi-node, multi-GPU support for quantum simulation with unparalleled performance using the cuQuantum Appliance.
- NVIDIA DOCA, the open cloud SDK and acceleration framework for NVIDIA BlueField DPUs, includes advanced programmability, security, and functionality to support new storage use cases.
These libraries enable researchers to scale across multiple servers and equip them with performance boosts to drive scientific discovery. The NVIDIA HPC acceleration libraries are available on leading cloud platforms AWS, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure.
Omniverse Open Portals for Scientists
Next, NVIDIA announced NVIDIA Omniverse now connects to leading scientific computing visualization software and supports new batch-rendering workloads on systems powered by NVIDIA A100 and H100 Tensor Core GPUs.
NVIDIA also introduced real-time scientific and industrial digital twins for the high-performance computing community, enabled by NVIDIA OVX, a computing system designed to power large-scale Omniverse digital twins, and Omniverse Cloud, a software- and infrastructure-as-a-service offering.

Omniverse now supports batch workloads that AI and HPC researchers, scientists, and engineers can run on their existing A100 or H100 systems.
NVIDIA also unveiled connections to popular scientific computing tools such as Kitware’s ParaView, an application for visualization; NVIDIA IndeX for volumetric rendering; NVIDIA Modulus for developing physics-ML models; and NeuraVDB for large-scale sparse volumetric data representation.
Using Omniverse and hybrid-cloud workloads, scientific computing customers can connect legacy simulation and visualization pipelines to achieve distributed, fully interactive, true real-time interaction with their models and datasets. NVIDIA customers such as Argonne National Laboratory, Lockheed Martin, and Princeton Plasma Physics Laboratory are already seeing the benefits of Omniverse for HPC workloads.
Omniverse gets support from Global Scientific Leaders.
Argonne National Laboratory is using NVIDIA Omniverse on its A100-powered Polaris supercomputer to connect its legacy visualization tools as a first step to developing the foundations for future digital twins.
Princeton Plasma Physics Laboratory (PPPL), the U.S. Department of Energy national laboratory for plasma physics and fusion science, is using Omniverse to connect and accelerate state-of-the-art, synthetic, real-time HPC simulators to model fusion devices and control systems and ultimately improve the operation of the experiment toward a new commercially viable clean-energy source.
Aligning with NVIDIA’s Earth-2 initiative to accelerate climate research, aerospace leader Lockheed Martin recently began using NVIDIA Omniverse to provide the U.S. National Oceanic and Atmospheric Administration (NOAA) with better global environmental, and situational awareness and to develop an interactive climate research pipeline.
Availability
These new features are now supported in NVIDIA Omniverse and available for developers and enterprises.
NVIDIA platform solves HPC problems at the edge
Universities and enterprises sharing work over long distances require a common language and secure pipeline to get every device, from microscopes and sensors to servers and campus networks, to see and understand the transmitted data. The increasing amount of data that needs to be stored, transmitted, and analyzed only compounds the challenge.
NVIDIA is addressing the problem by introducing a high-performance computing platform that combines edge computing and AI to capture and consolidate streaming data from scientific edge instruments allowing the devices to talk to each other over long distances.
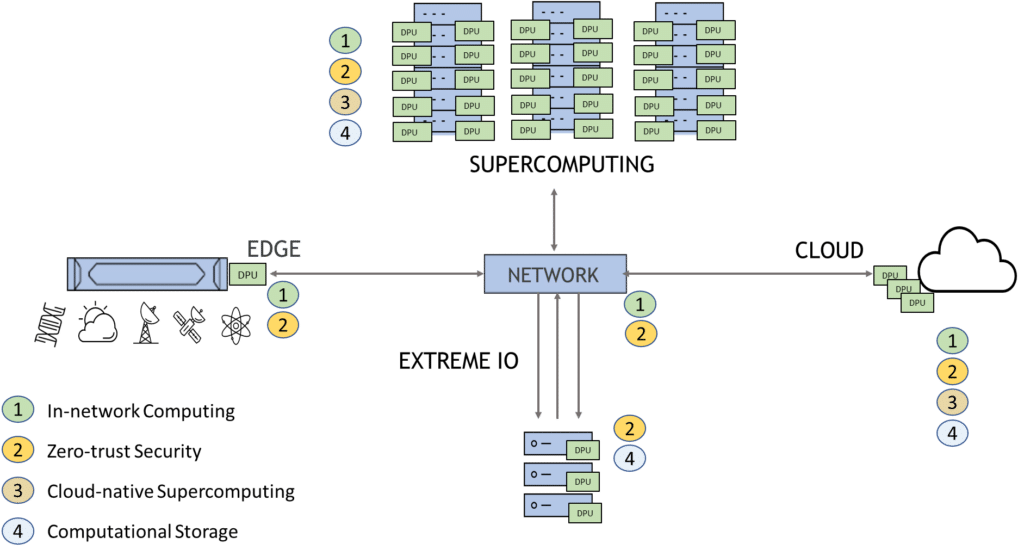
The platform consists of three major components, NVIDIA Holoscan, MetroX-3, and NVIDIA BlueField-3 DPUs. NVIDIA Holoscan is a software development kit that data scientists and domain experts can use to build GPU-accelerated pipelines for sensors that stream data. MetroX-3 is a new long-haul system that extends the connectivity of the NVIDIA Quantum-2 InfiniBand platform. And NVIDIA BlueField-3 DPUs provide secure and intelligent data migration.

Researchers can use the new NVIDIA platform for HPC edge computing to securely communicate and collaborate on solving problems and bring their disparate devices and algorithms together to operate as one large supercomputer.
Holoscan for HPC at the Edge
Accelerated by GPU computing platforms that include NVIDIA IGX, HGX, and DGX systems, NVIDIA Holoscan delivers the extreme performance required to process massive streams of data generated by the world’s scientific instruments.
NVIDIA Holoscan for HPC includes new APIs for C++ and Python that HPC researchers can use to build sensor data processing workflows that are flexible enough for non-image formats and scalable enough to translate raw data into real-time insights.
Holoscan also manages memory allocation to ensure zero-copy data exchanges, so developers can focus on the workflow logic and not worry about managing file and memory I/O.
The new features in Holoscan will be available to all the HPC developers next month.
MetroX-3 Goes the Distance
The NVIDIA MetroX-3 long-haul system, available next month, extends the latest cloud-native capabilities of the NVIDIA Quantum-2 InfiniBand platform from the edge to the HPC data center core. It enables GPUs between sites to securely share data over the InfiniBand network up to 25 miles (40km) away.

Taking advantage of native remote direct memory access, users can easily migrate data and compute jobs from one InfiniBand-connected mini-cluster to the main data center or combine geographically dispersed compute clusters for higher overall performance and scalability.
Data center operators can provision, monitor, and operate across all the InfiniBand-connected data center networks by using the NVIDIA Unified Fabric Manager to manage their MetroX-3 systems.
BlueField for Secure, Efficient HPC
NVIDIA BlueField DPUs offload, accelerate, and isolate advanced networking, storage, and security services to boost performance and efficiency for modern HPC.
NVIDIA Brings Digital Twin Simulation to HPC Data Center Operators
Simulation and digital twins can help data center designers, builders, and operators create highly efficient and performant facilities. The NVIDIA Omniverse simulation platform helps by streamlining the process of collaborative virtual design.
Omniverse now lets data center operators aggregate real-time input from their core third-party computer-aided design, simulation, and monitoring applications so they can see and work with their complete datasets in real time.
The SC22 Omniverse demo shows how Omniverse allows users to tap into the power of accelerated computing, simulation, and operational digital twins connected to real-time monitoring and AI. This enables teams to streamline facility design, accelerate construction and deployment, and optimize ongoing operations.
The demo also highlighted NVIDIA Air, a data center simulation platform designed to work with Omniverse to simulate the network. With NVIDIA Air, teams can model the entire network stack, allowing them to automate and validate network hardware and software prior to bring-up.
Creating Digital Twins to Elevate Design and Simulation
In planning and constructing one of NVIDIA’s latest AI supercomputers, multiple engineering CAD datasets were collected from third-party industry tools such as Autodesk Revit, PTC Creo, and Trimble SketchUp. This allowed designers and engineers to view the Universal Scene Description-based model in full fidelity, and they could collaboratively iterate on the design in real time.
PATCH MANAGER is an enterprise software application for planning cabling, assets, and physical layer point-to-point connectivity in network domains. With PATCH MANAGER connected to Omniverse, the complex topology of port-to-port connections, rack and node layouts, and cabling can be integrated directly into the live model. This enables data center engineers to see the full view of the model and its dependencies.
To predict airflow and heat transfers, engineers used Cadence 6SigmaDCX, a software for computational fluid dynamics. Engineers can also use AI surrogates trained with NVIDIA Modulus for “what-if” analysis in near-real time. This lets teams simulate changes in complex thermals and cooling, and they can see the results instantly.
And with NVIDIA Air, the exact network topology — including protocols, monitoring, and automation — can be simulated and prevalidated.
Once a data center is constructed, its sensors, control system, and telemetry can be connected to the digital twin inside Omniverse, enabling real-time monitoring of operations.
Engineers can simulate common dangers such as power peaking or cooling system failures with a perfectly synchronized digital twin. Operators can benefit from AI-recommended changes that optimize for key priorities like boosting energy efficiency and reducing carbon footprint. The digital twin also allows them to test and validate software and component upgrades before deploying to the physical data center.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed