
![]() The containerization of development, testing and production operation’s workflows is revolutionizing IT management at all levels, whether for customer-facing or internal applications and services. Organizations gain development and time-to-deployment efficiencies by using microservice-based architectures built on containers and utilizing container orchestration frameworks such as Kubernetes.
The containerization of development, testing and production operation’s workflows is revolutionizing IT management at all levels, whether for customer-facing or internal applications and services. Organizations gain development and time-to-deployment efficiencies by using microservice-based architectures built on containers and utilizing container orchestration frameworks such as Kubernetes.
The containerization of development, testing and production operation’s workflows is revolutionizing IT management at all levels, whether for customer-facing or internal applications and services. Organizations gain development and time-to-deployment efficiencies by using microservice-based architectures built on containers and utilizing container orchestration frameworks such as Kubernetes.

The transition from classic IT to container-based approaches often originates from grass root efforts by DevOps teams or departments creating a prototype environment that other teams then replicate. While these teams do this to gain efficiency and flexibility, the result often is silos of DevOps clusters and thus either poor performance (not enough resources) or poor utilization (resources underutilized outside of peak demand hours). Usually it is both; while one team is “under water” with their resource demand and supply, other teams may have lots of idle cycles available. Worse, teams often overprovision and then the costs are huge. Industry standards for cluster utilization often are in the 20% range.
Consolidating clusters (or cloud accounts, for that matter) from many into fewer, ideally into just one, and sharing the resources across teams and use cases is the recipe to drive up performance and output while reducing costs. Consolidation and sharing really allows you to do more with less – if you can share effectively, automatically and fairly.
Current container orchestration frameworks such as Kubernetes, Docker Swarm or Mesos do not allow you to accomplish that out of the box, however. Kubernetes and Swarm provide simplistic workload distribution schemes such as ‘spread’ (round-robin), ‘pack’ or ‘random’ and otherwise require you to segment cluster resources manually via concepts like namespaces or labels. In Mesos different types of workloads (e.g. Spark, Hadoop or services under Marathon) bring their own scheduler that might or might not offer some resource sharing policies (with its own logic and configuration) but the workloads will fight each other for resource access and there is no overarching policy system that understands what the most important workloads are for a business and how to meet its needs while not overcommitting resources to it.
For non-trivial resource sharing use cases, each of these systems will require a lot manual intervention and will still either require over provisioning or suffer from performance impacts caused by resource conflicts.
What is truly needed for being able to share a resource pool across organizations and arbitrary types of (containerized but also non-containerized) workloads is an advanced policy system that understands workload characteristics and business priorities so that it can automate decision making on resource allocation and re-allocate resources on demand when the boundary conditions or demands change.
Navops Command is a currently quite unique example for such a capability. It augments Kubernetes and adds sophisticated, dynamic and demand driven policies that automate decision-making on the prioritization of workloads and on resource consumption at any given point in time. Compared to other container orchestration frameworks, Kubernetes provides the richest set of production strength capabilities to manage workloads reliably (such as automated controllers for replicas, jobs, deployments, workload admission, etc). With Navops Command on top of Kubernetes you can run software builds, automated tests and production deployments of several applications and service environments on the same cluster or cloud pool. The DevOps tasks and production services can come from multiple teams and have different importance that may very over the course of the day. Navops Command ensures that none of the related workloads get in the way of each other while performing as required at the same time.
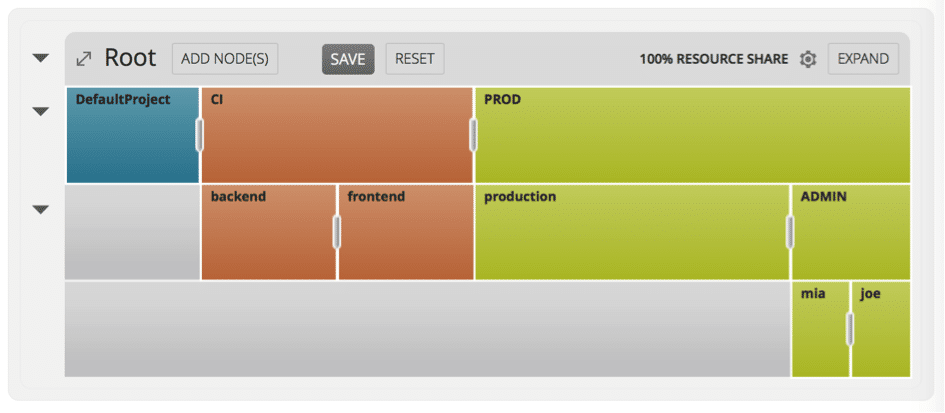
Picture 1: Navops Command policy ‘Proportional Shares’ automating resource sharing across groups, projects and individuals
With Navops Command it is possible to attain cluster utilization rates of 80% and even higher. It delivers its benefits even within a single team when you run various tasks like build, test and operations, and it renders even more benefits when you share across teams.
Navops Command demonstrates what is required to effectively run microservice-based applications as well as other containerized workloads on a shared environment (on-premise or cloud). It is currently available for any type of Kubernetes distribution and can be evaluated easily as described here.
About the author
Fritz Ferstl is the currently CTO and Business Development EMEA at Univa Corporation.
Fritz Ferstl brings 20 years of grid and cloud computing experience to Univa, and as the Chief Technology Officer he will help set technical vision while spearheading strategic alliances. Fritz, long regarded as the father of Grid Engine software and its forerunners Codine and GRD, ran the Grid Engine software business from within Sun Microsystems and Oracle for the past 10 years, taking it from an upstart technology to the most widely deployed workload management solution in some of the most challenging data center environments on the planet. Under Fritz’s leadership Grid Engine software was open sourced and has grown a vibrant community.
Sign up for the StorageReview newsletter