
IBM integrates two of Meta’s latest Llama 4 models, Scout and Maverick, into watsonx.ai platform.
IBM has integrated Meta’s latest open-source AI models—Llama 4 Scout and Llama 4 Maverick—into its watsonx.ai platform. This next-generation mixture of experts (MoE) models is engineered to deliver high-performance multimodal capabilities with significantly improved cost efficiency, scalability, and processing power. With the addition of Llama 4, IBM now supports 13 meta-models on watsonx.ai, reinforcing its commitment to an open, multi-model approach to generative AI.
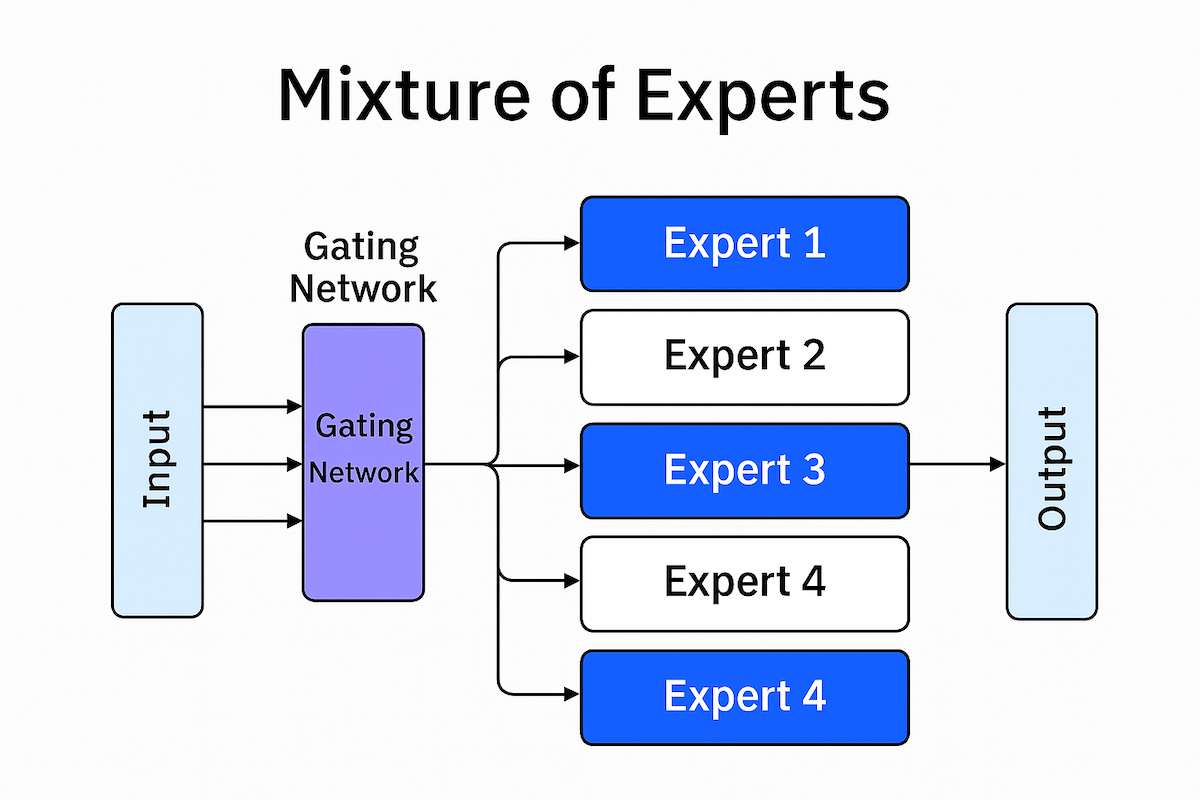
Mixture of Experts Architecture: Efficiency Without Compromise
Meta’s new Llama 4 models signify a significant advancement in AI architecture. Both models utilize MoE, which smartly activates only a subset of model “experts” for each token, instead of engaging the entire network. This targeted inference strategy increases throughput and reduces operational expenses without compromising quality.
Llama 4 Scout boasts 109 billion total parameters divided among 16 experts, yet only 17 billion parameters are active during inference. This efficient configuration enables greater concurrency and quicker response times while delivering exceptional performance on coding, long-context reasoning, and image understanding tasks. Despite its compact footprint, Scout is trained on 40 trillion tokens and surpasses models with significantly larger active parameter sets.
Llama 4 Maverick takes things further with 400 billion parameters and 128 experts, still operating with just 17 billion active parameters per inference. Meta reports that Maverick outperforms OpenAI’s GPT-4o and Google’s Gemini 2.0 Flash across the board on multimodal benchmarks, and it matches DeepSeek-V3’s performance on reasoning and coding workloads, despite being far more efficient.
| Model | Total Parameters | Active Parameters | Number of Experts | Context Window |
|---|---|---|---|---|
| Llama 4 Scout | 109B | 17B | 16 | 10M tokens |
| Llama 4 Maverick | 400B | 17B | 128 | 10M tokens |
Leading the Way in Long-Context AI
Llama 4 Scout introduces a groundbreaking context window of up to 10 million tokens—currently the longest in the industry. This advancement enables multi-document summarization, in-depth codebase analysis, and long-term user personalization. Meta credits this milestone to two architectural innovations: interleaved attention layers (without positional embeddings) and an inference-time attention scaling technique. Collectively referred to as “iRope,” these enhancements bring Meta closer to its vision of infinite context-length AI.
Native Multimodality for Real-World Use Cases
Traditional LLMs are trained solely on text and then retrofitted for other data types. In contrast, Llama 4 models are considered “natively multimodal,” which means they are trained from the ground up using a combination of text, image, and video data. This enables them to handle various input types naturally and provide more integrated, context-aware results.
 During training, the models fuse visual and language data at early processing stages, effectively teaching the system to interpret and reason across modalities simultaneously. The result is superior performance in image-based reasoning, including the ability to process multiple images per prompt and associate specific visual elements with textual responses.
During training, the models fuse visual and language data at early processing stages, effectively teaching the system to interpret and reason across modalities simultaneously. The result is superior performance in image-based reasoning, including the ability to process multiple images per prompt and associate specific visual elements with textual responses.
Enterprise Deployment on IBM watsonx
With watsonx.ai, developers and enterprises can access Llama 4 Scout or Maverick and fine-tune, distill, and deploy them across cloud, on-premise, or edge environments. IBM’s enterprise-grade platform supports the entire AI lifecycle, providing tools for developers of all skill levels—from code to low-code and no-code environments.
watsonx.ai includes pre-built integrations with vector databases, agent frameworks, and advanced infrastructure that make it easy to operationalize AI at scale. Robust governance tools ensure enterprise-grade compliance, security, and auditability, helping teams build responsibly and deploy faster.
A Strategic Alliance for AI Transformation
IBM’s partnership with Meta merges open innovation with practical enterprise readiness. As Meta extends the limits of model architecture, IBM delivers the infrastructure, governance, and deployment flexibility that contemporary businesses require to move quickly without sacrificing control or cost-effectiveness.
Llama 4’s arrival on watsonx.ai provides IBM clients with a new set of high-performance tools to unlock value across a wide array of use cases—without vendor lock-in and with the assurance of operating on a platform designed for the enterprise.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed