
Meta AI brought a 3rd Llama to the table.
Meta AI has developed and announced Llama 3, a large language model that is making waves in artificial intelligence with its previous releases. This latest addition to the Llama family boasts impressive capabilities, including generating coherent and fluent text, answering questions, and engaging in conversation.

Llama 3 – Just Another Revision?
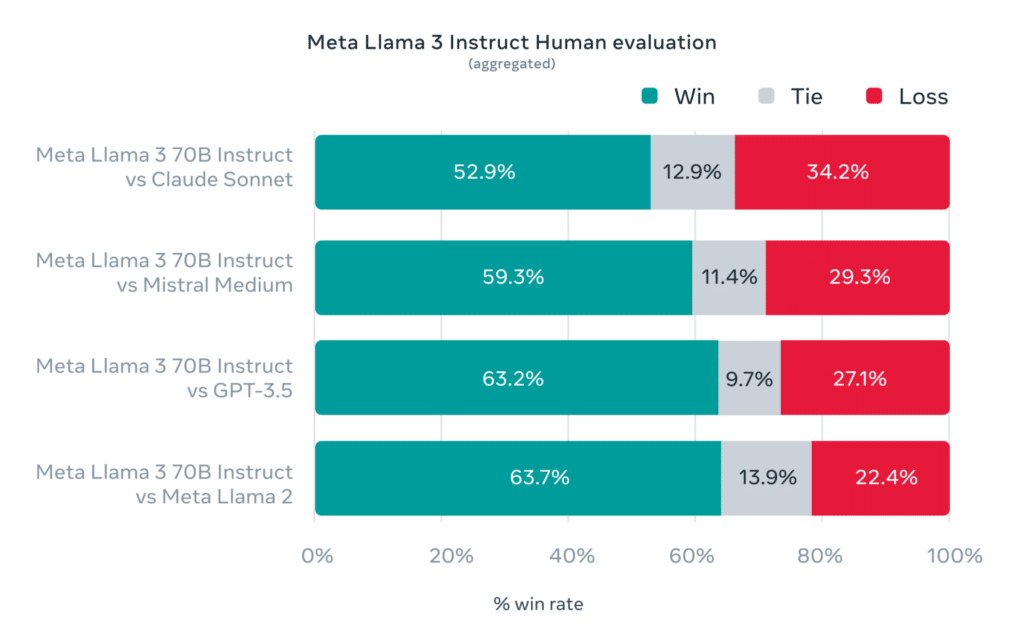
What sets Llama 3 apart from its predecessors? According to human evaluation results, the model achieves a win rate of 59.3% against Mistral Medium and 63.7% against GPT-3.5. These impressive figures indicate that Llama 3 can generate text comparable in quality to human-generated text.
The training dataset for Llama 3 consists of over 15T tokens collected from publicly available sources, making it seven times larger than the training dataset used for Llama 2. This extensive training data allows the model to generate diverse and accurate text.
This 15 trillion token dataset is significantly larger than its predecessor, containing seven times the data of Llama 2 and including an expansive range of code—quadrupling the amount previously used. Notably, over 5% of the data is high-quality non-English content spanning more than 30 languages, although it is acknowledged that performance in these languages may not reach the levels seen in English.
Ensuring the quality of the data, Meta developed sophisticated filtering pipelines. These include heuristic filters, NSFW content filters, semantic deduplication, and classifiers designed to assess text quality. Interestingly, Llama 2 was utilized to refine the training data for these quality classifiers, proving instrumental in powering the subsequent generation.
Regarding scaling up pre-training, Meta has innovated with detailed scaling laws to enhance model training effectively. These laws guide the mix of data and compute usage, optimizing performance across various benchmarks like code generation. Surprisingly, the 8B and 70B parameter models exhibited continued performance improvements beyond traditional training caps, showcasing potential in massive data training scenarios.
Llama 3 and You
The future of the Llama ecosystem looks promising as well, with plans to expand the model’s capabilities and make it even more accessible to developers. This means that we can expect to see even more innovative applications of Llama 3 in the months and years to come.
For a practical training application, Meta leveraged a trifecta of parallelization strategies—data, model, and pipeline parallelization—to train on an unprecedented scale using 16K GPUs. This scale was facilitated by custom-built GPU clusters and a new training stack that ensures over 95% effective training time by automating maintenance and optimizing GPU usage.

Meta reports that post-training refinement through instruction tuning has been vital. Techniques such as supervised fine-tuning, rejection sampling, and policy optimizations have refined the model’s performance on specific tasks and helped it learn to select the correct answers from generated possibilities. This nuanced training strategy has significantly improved Llama 3’s reasoning and coding capabilities, setting a new benchmark for AI model training and application.
Closing thoughts
Llama 3 arrives with many competitors, promising better performance and usefulness. With its impressive capabilities and extensive training data, it will revolutionize how we interact with machines. Whether you’re a developer looking to integrate Llama into your next project or simply someone interested in the future of AI, Llama 3 is worth keeping an eye on.
Meta AI can be used on Facebook, Instagram, WhatsApp, Messenger, and the web. Meta AI provides documentation for Meta AI here.
The Llama 3 website has the download information for the models and provides a Getting Started Guide.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed