
Meta unveils Llama 4, a powerful MoE-based AI model family offering improved efficiency, scalability, and multimodal performance.
Meta has introduced its latest AI innovation, Llama 4, a collection of models that enhance multimodal intelligence capabilities. Llama 4 is based on the Mixture-of-Experts (MoE) architecture, which offers exceptional efficiency and performance.
Understanding MoE Models and Sparsity
Mixture-of-Experts (MoE) models significantly differ from traditional dense models, where the entire model processes every input. In MoE models, only a subset of the total parameters, referred to as “experts,” is activated for each input. This selective activation depends on the characteristics of the input, enabling the model to allocate resources dynamically and enhance efficiency.
Sparsity is an essential concept in MoE models, indicating the ratio of inactive parameters for a specific input. MoE models can significantly reduce computational costs by utilizing sparsity while maintaining or enhancing performance.
Meet the Llama 4 Family: Scout, Maverick, and Behemoth
The Llama 4 suite comprises three models: Llama 4 Scout, Llama 4 Maverick, and Llama 4 Behemoth. Each model is designed to cater to different use cases and requirements.
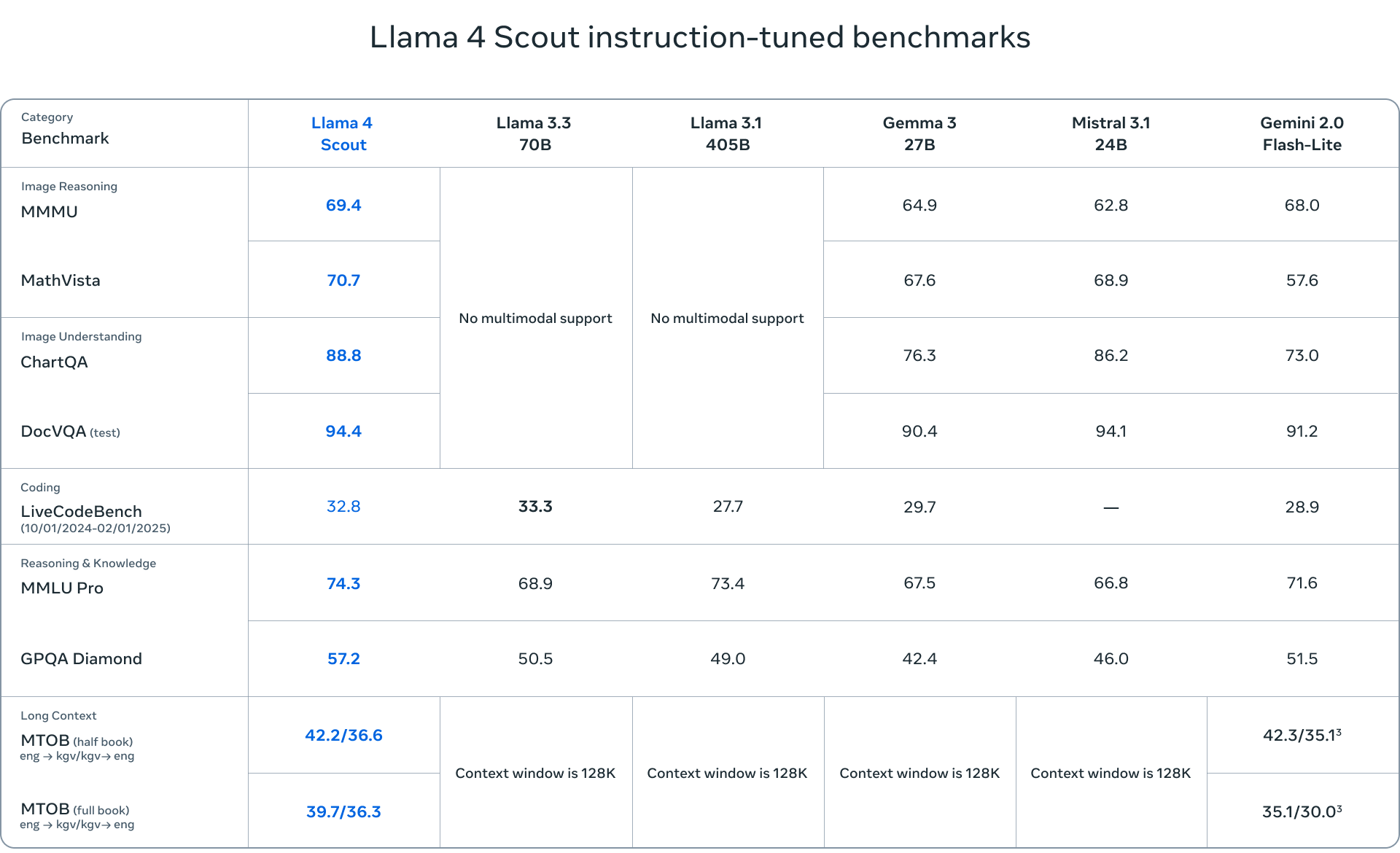
- Llama 4 Scout is a compact model with 17 billion active parameters and 109 billion total parameters across 16 experts. It is optimized for efficiency and can run on a single NVIDIA H100 GPU (FP4 Quantized). Scout boasts an impressive 10 million token context window, making it ideal for applications requiring long-context understanding.
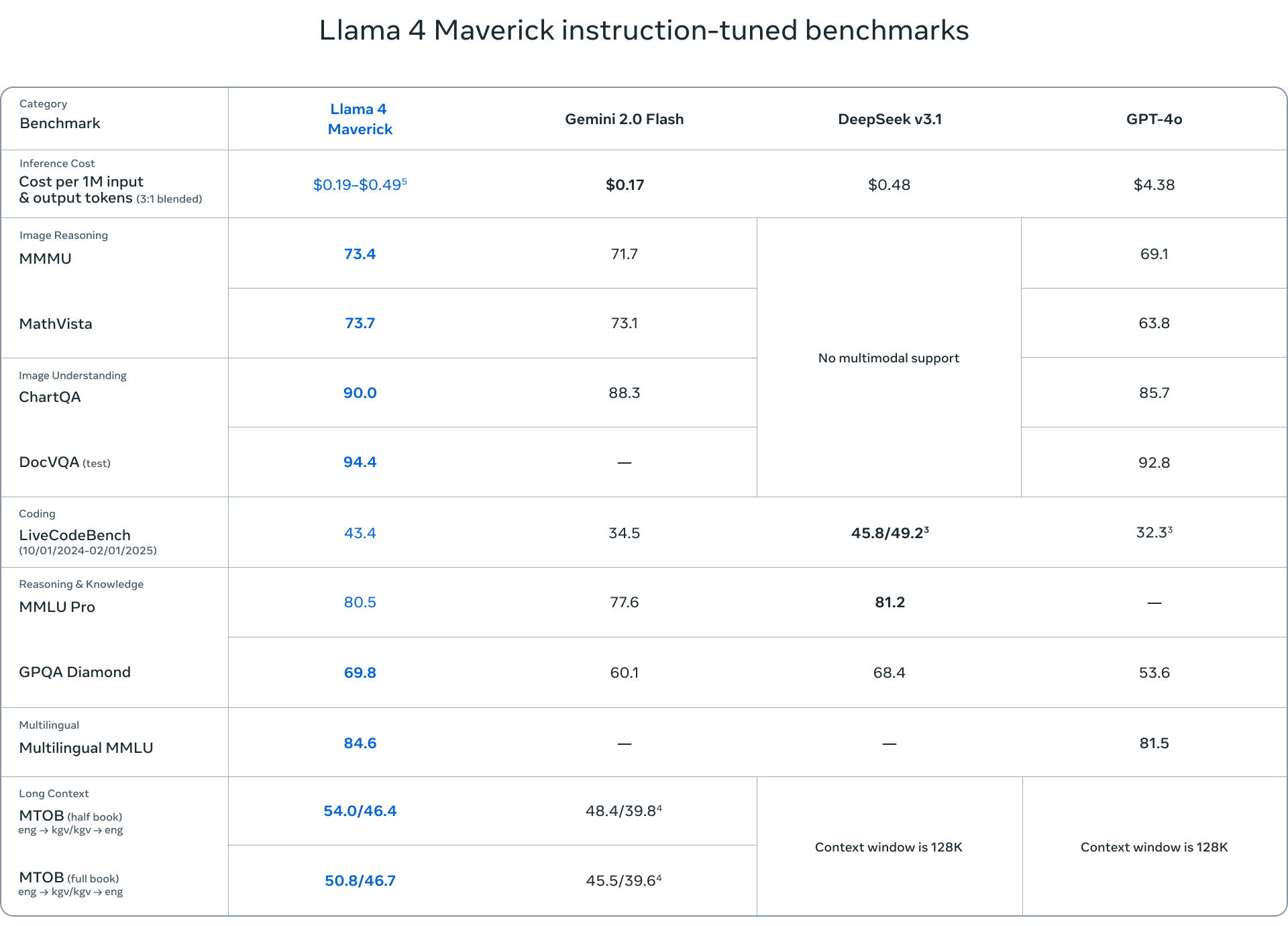
- Llama 4 Maverick is a more robust model with the same 17 billion active parameters but with 128 experts, totaling 400 billion parameters. Maverick excels in multimodal understanding, multilingual tasks, and coding, outperforming competitors like GPT-4o and Gemini 2.0 Flash.
- Llama 4 Behemoth is the largest model in the suite, with 288 billion active parameters and nearly 2 trillion total parameters across 16 experts. Although still in training, Behemoth has already demonstrated state-of-the-art performance on various benchmarks, surpassing models like GPT-4.5 and Claude Sonnet 3.7.
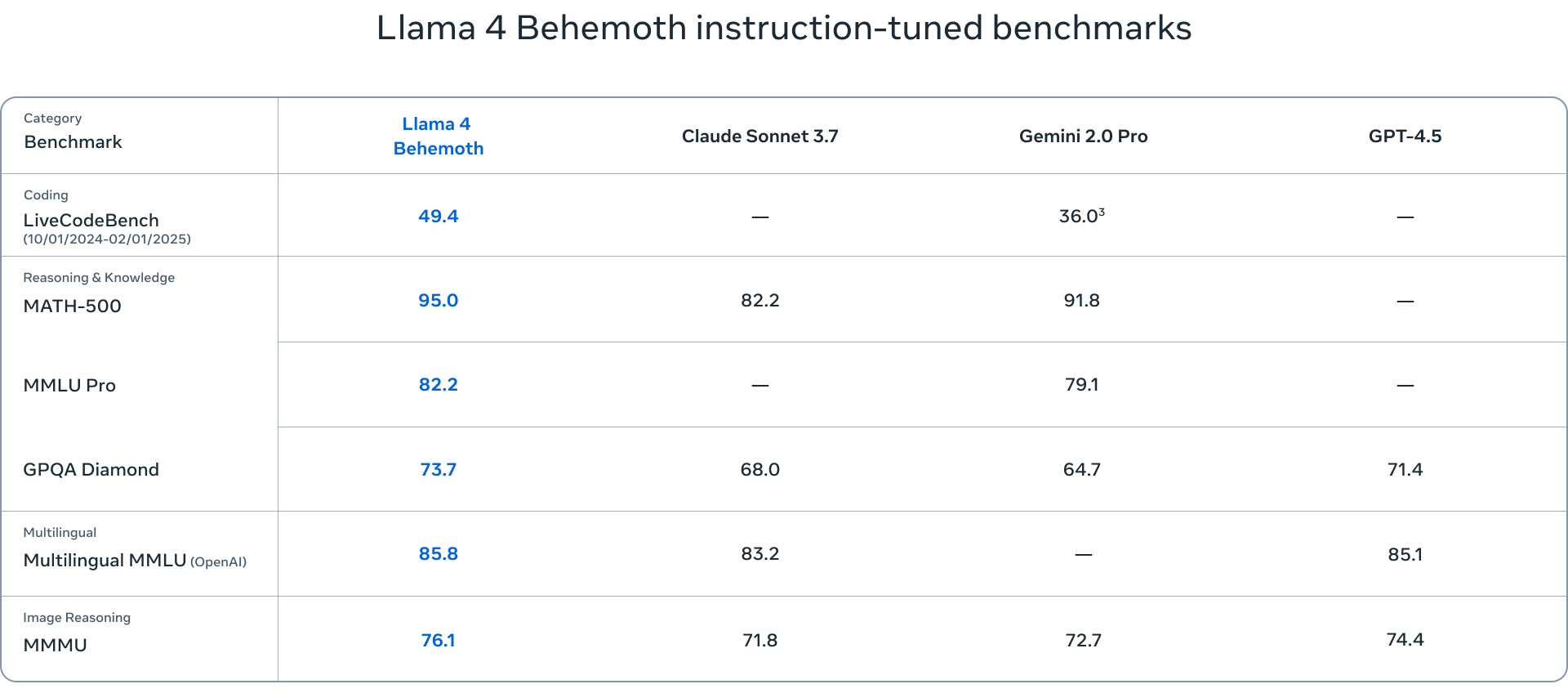
The benchmarks used to evaluate the Llama 4 models cover a range of tasks, including language understanding (MMLU – Massive Multitask Language Understanding, GPQA – Google-Proof Question Answering), mathematical problem-solving (MATH – Mathematical Problem-Solving, MathVista – a benchmark for mathematical problem-solving in visual contexts), and multimodal understanding (MMMU – Massive Multimodal Multitask Understanding). These standard benchmarks provide a comprehensive assessment of the models’ capabilities and help to identify areas where they excel or require further improvement.
The Role of Teacher Models in Llama 4
A teacher model is a large, pre-trained model that guides smaller models, transferring its knowledge and capabilities to them through distillation. In the case of Llama 4, Behemoth acts as the teacher model, distilling its knowledge to both Scout and Maverick. The distillation process involves training the smaller models to mimic the behavior of the teacher model, allowing them to learn from its strengths and weaknesses. This approach enables the smaller models to achieve impressive performance while being more efficient and scalable.
Implications and Future Directions
The release of Llama 4 marks a significant milestone in the AI landscape, with far-reaching implications for research, development, and applications. Historically, Llama models have been a catalyst for downstream research, inspiring various studies and innovations. The Llama 4 release is expected to continue this trend, enabling researchers to build upon and fine-tune the models to tackle complex tasks and challenges.
Many models have been fine-tuned and built on top of Llama models, demonstrating the versatility and potential of the Llama architecture. The Llama 4 release will likely accelerate this trend as researchers and developers leverage the models to create new and innovative applications. This is significant because Llama 4 is a strong model release and will enable a wide range of research and development activities.
It’s worth noting that the Llama 4 models, similar to their predecessors, are non-thinking. Therefore, future Llama 4 series releases could potentially be post-trained for reasoning, further enhancing their performance.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed