
Today at NetApp Insight, the company announced that it was partnering with the virtualizing AI infrastructure company, Run:AI, to enable faster AI experimentation with full GPU utilization. The two companies will speed AI by running many experiments in parallel, with fast access to data, utilizing limitless compute resources. The goal is the best of all worlds: faster experiments while leverage full resources.
Today at NetApp Insight, the company announced that it was partnering with the virtualizing AI infrastructure company, Run:AI, to enable faster AI experimentation with full GPU utilization. The two companies will speed AI by running many experiments in parallel, with fast access to data, utilizing limitless compute resources. The goal is the best of all worlds: faster experiments while leverage full resources.
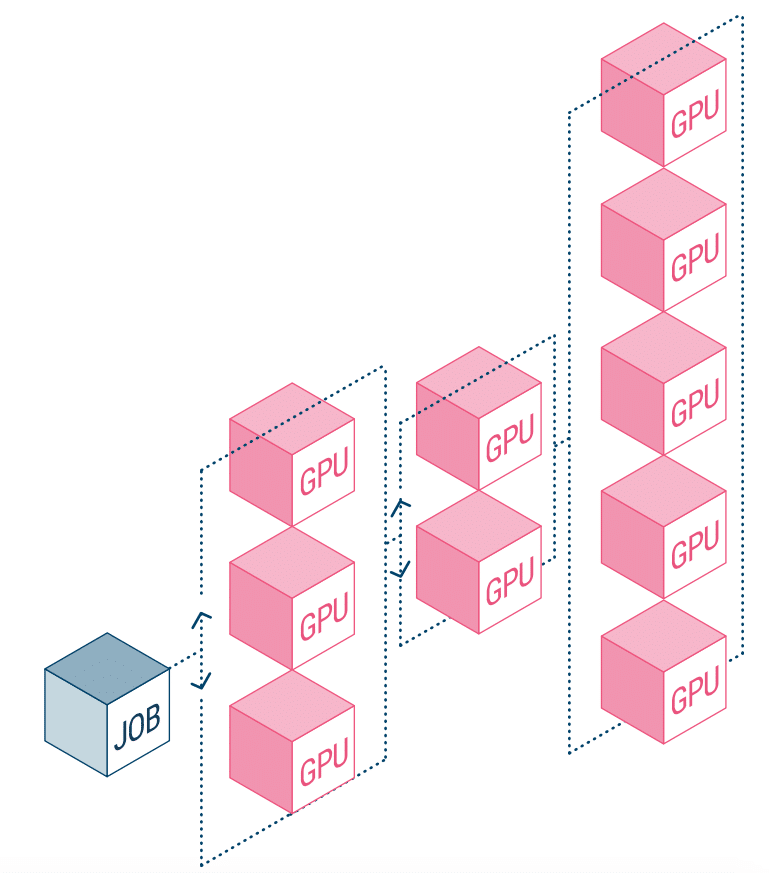
Speed has become a critical aspect of most modern workloads. However, AI experimentation is tied a bit more closely with speed as the faster the experimentation, the more closely the successful business outcomes are. While this is no secret, AI projects suffer from processes that make them less than efficient, mainly the combination of data processing time and outdated storage solutions. Other issues that can limit the number of experiments ran is workload orchestration issues and static allocation of GPU compute resources.
NetApp AI and Run:AI are partnering to address the above. This means a simplification of the orchestration of AI workloads, streamlining the process of both data pipelines and machine scheduling for deep learning (DL). With NetApp ONTAP AI’s proven architecture, the company states that customers can better realize AI and DL through simplifying, accelerating, and integrating their data pipeline. On the Run:AI side, its orchestration of AI workloads adds a proprietary Kubernetes-based scheduling and resource utilization platform to help researchers manage and optimize GPU utilization. The combined technology will allow several experiments to run in parallel on different compute nodes, with fast access to many datasets on centralized storage.
Run:AI built what it calls the world’s first orchestration and virtualization platform for AI infrastructure. They abstract the workload from the hardware and create shared pools of GPU resources that can be dynamically provisioned. Running this on NetApp’s storage systems allows researchers to focus on their work without worrying about bottlenecks.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | RSS Feed