

Large language models offer incredible new capabilities, expanding the frontier of what is possible with AI. However, their large size and unique execution characteristics can make them challenging to use cost-effectively. NVIDIA TensorRT-LLM has been open-sourced to accelerate the development of LLMs.
Large language models offer incredible new capabilities, expanding the frontier of what is possible with AI. However, their large size and unique execution characteristics can make them challenging to use cost-effectively. NVIDIA TensorRT-LLM has been open-sourced to accelerate the development of LLMs.
What is NVIDIA TensorRT-LLM?
NVIDIA has been working closely with leading companies, including Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML, now a part of Databricks, OctoML, Tabnine, and Together AI to accelerate and optimize LLM inference.

Those innovations have been integrated into the open-source NVIDIA TensorRT-LLM software, set for release in the coming weeks. TensorRT-LLM consists of the TensorRT deep learning compiler and includes optimized kernels, pre- and post-processing steps, and multi-GPU/multi-node communication primitives for groundbreaking performance on NVIDIA GPUs. It enables developers to experiment with new LLMs, offering peak performance and quick customization capabilities without requiring deep C++ or NVIDIA CUDA knowledge.
TensorRT-LLM improves ease of use and extensibility through an open-source modular Python API for defining, optimizing, and executing new architectures and enhancements as LLMs evolve and can be customized easily.
For example, MosaicML has added specific features that it needs on top of TensorRT-LLM seamlessly and integrated them into their existing serving stack. Naveen Rao, vice president of engineering at Databricks, notes that “it has been an absolute breeze.”
NVIDIA TensorRT-LLM Performance
Summarizing articles is just one of the many applications of LLMs. The following benchmarks show performance improvements brought by TensorRT-LLM on the latest NVIDIA Hopper architecture.
The following figures reflect article summarization using an NVIDIA A100 and NVIDIA H100 with CNN/Daily Mail, a well-known dataset for evaluating summarization performance.
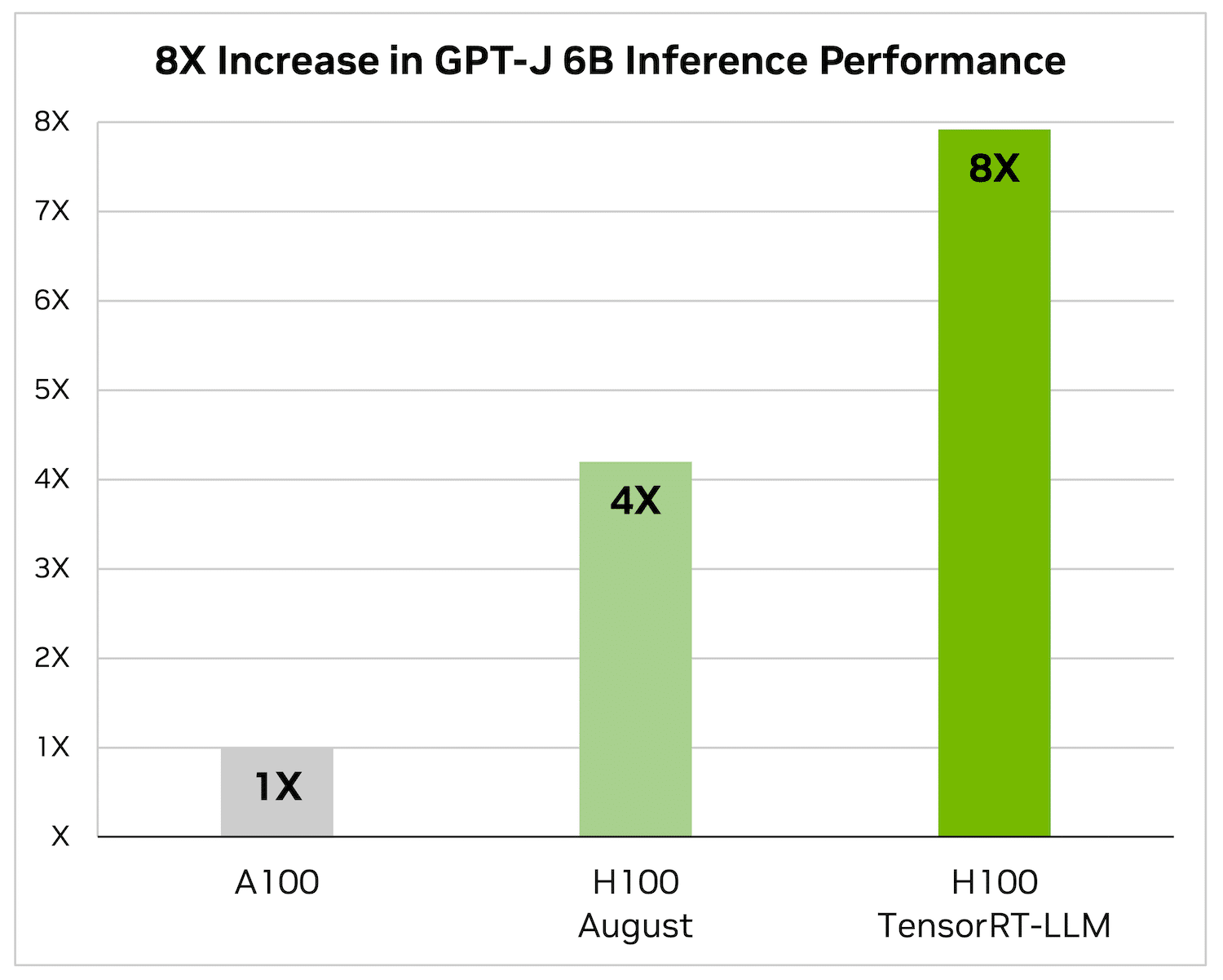
H100 alone is 4x faster than A100. Adding TensorRT-LLM and its benefits, including in-flight batching, results in an 8X increase to deliver the highest throughput.
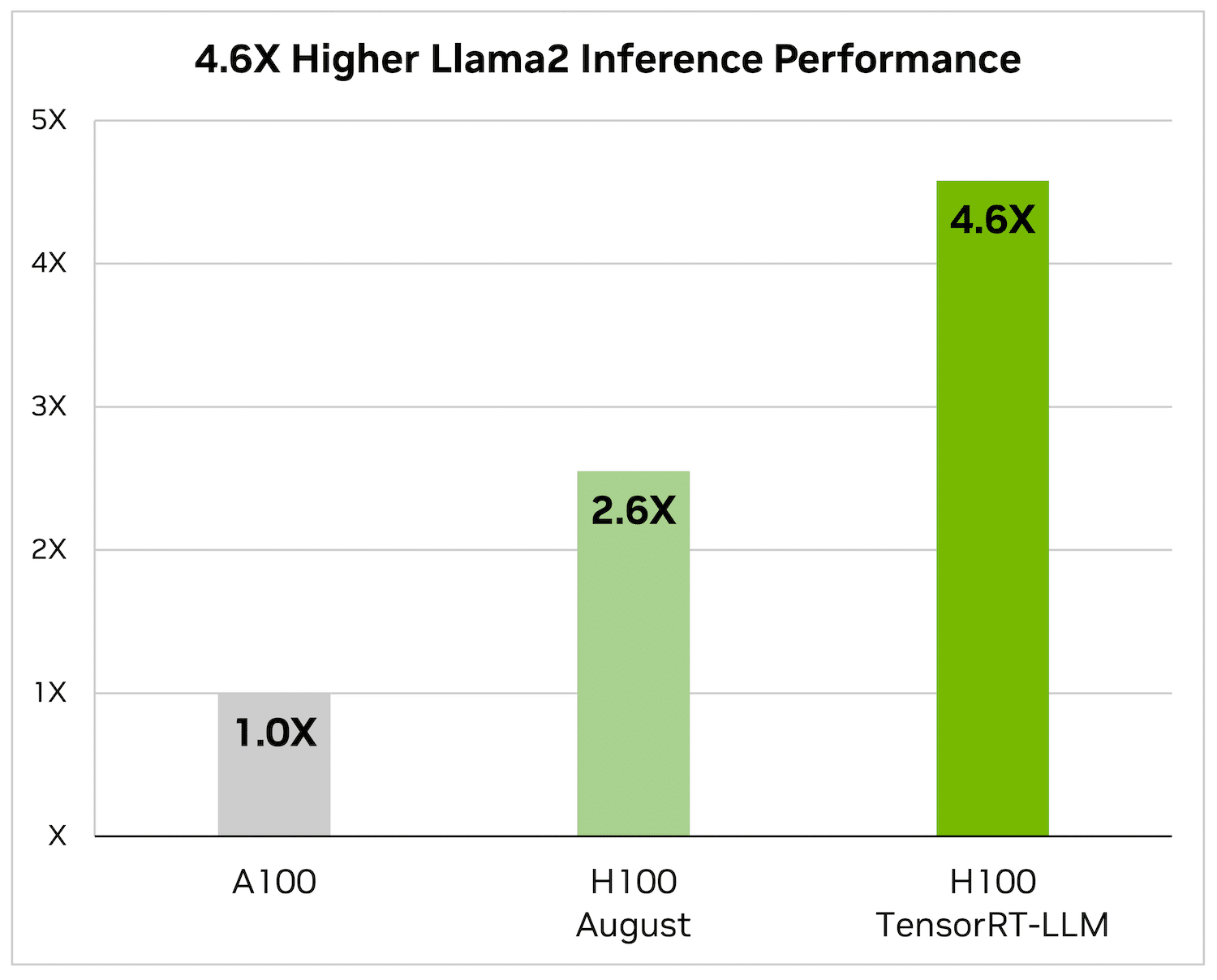
On Llama 2 – a popular language model released recently by Meta and used widely by organizations looking to incorporate generative AI — TensorRT-LLM can accelerate inference performance by 4.6x compared to A100 GPUs.
LLM Ecosystem Innovation Evolves Rapidly
The Large Language Model (LLM) ecosystem is evolving rapidly, giving rise to diverse model architectures with expanded capabilities. Some of the largest and most advanced LLMs, like Meta’s 70-billion-parameter Llama 2, require multiple GPUs to provide real-time responses. Previously, optimizing LLM inference for peak performance involved complex tasks such as manually splitting AI models and coordinating GPU execution.
TensorRT-LLM simplifies this process by employing tensor parallelism, a form of model parallelism that distributes weight matrices across devices. This approach allows efficient scale-out inference across multiple GPUs interconnected via NVLink and multiple servers without developer intervention or model modifications.
As new LLMs and model architectures emerge, developers can optimize their models using the latest NVIDIA AI kernels available in TensorRT-LLM, which includes cutting-edge implementations like FlashAttention and masked multi-head attention.
Furthermore, TensorRT-LLM includes pre-optimized versions of widely used LLMs, such as Meta Llama 2, OpenAI GPT-2, GPT-3, Falcon, Mosaic MPT, BLOOM, and others. These can be easily implemented using the user-friendly TensorRT-LLM Python API, empowering developers to create customized LLMs tailored to various industries.
To address the dynamic nature of LLM workloads, TensorRT-LLM introduces in-flight batching, optimizing the scheduling of requests. This technique enhances GPU utilization and nearly doubles throughput on real-world LLM requests, reducing Total Cost of Ownership (TCO).

Dell XE9680 GPU Block
Additionally, TensorRT-LLM uses quantization techniques to represent model weights and activations in lower precision (e.g., FP8). This reduces memory consumption, allowing larger models to run efficiently on the same hardware while minimizing memory-related overhead during execution.
The LLM ecosystem is rapidly advancing, offering greater capabilities and applications across industries. TensorRT-LLM streamlines LLM inference, enhancing performance and TCO. It empowers developers to optimize models easily and efficiently. To access TensorRT-LLM, developers and researchers can participate in the early access program through the NVIDIA NeMo framework or GitHub, provided they are registered in the NVIDIA Developer Program with an organization’s email address.
Closing Thoughts
We have long noted in The Lab that there is overhead available that is being underutilized by the software stack, and TensorRT-LLM makes it clear that renewing focus on optimizations and not just innovation can be extremely valuable. As we continue to experiment locally with various frameworks and cutting-edge technology, we plan to independently test and validate these gains from the improved library and SDK releases.
NVIDIA is clearly spending development time and resources to squeeze every last drop of performance out of its hardware, further solidifying its position as the industry leader, and continuing its contributions to the community and democratization of AI by keeping the open-source nature of the tools.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed