
NVIDIA GTC 2025 unveiled groundbreaking AI advancements, including Blackwell Ultra GPUs, AI-Q, Mission Control, and DGX Spark.
NVIDIA’s GTC conference highlighted numerous innovations set to transform AI development across multiple sectors and showcased breakthroughs in AI hardware, software, and partnerships. The gem of GTC 2025 was undoubtedly unveiling the datacenter GPUs and their roadmap. NVIDIA’s most powerful AI accelerator in production to date is the B300, built on the Blackwell Ultra architecture. It presents a 1.5x increase in performance over the already industry-leading performance of the Blackwell GPUs.

When compared to the released GPUs from NVIDIA, the performance gains are staggering:
| Specification | H100 | H200 | B100 | B200 | B300 |
|---|---|---|---|---|---|
| Max Memory | 80 GBs HBM3 | 141 GBs HBM3e | 192 GBs HBM3e | 192 GBs HBM3e | 288 GBs HBM3e |
| Memory Bandwidth | 3.35 TB/s | 4.8TB/s | 8TB/s | 8TB/s | 8TB/s |
| FP4 Tensor Core | – | – | 14 PFLOPS | 18 PFLOPS | 30 PFLOPS |
| FP6 Tensor Core | – | – | 7 PFLOPS | 9 PFLOPS | 15 PFLOPS* |
| FP8 Tensor Core | 3958 TFLOPS (~4 PFLOPS) | 3958 TFLOPS (~4 PFLOPS) | 7 PFLOPS | 9 PFLOPS | 15 PFLOPS* |
| INT 8 Tensor Core | 3958 TOPS | 3958 TOPS | 7 POPS | 9 POPS | 15 PFLOPS* |
| FP16/BF16 Tensor Core | 1979 TFLOPS (~2 PFLOPS) | 1979 TFLOPS (~2 PFLOPS) | 3.5 PFLOPS | 4.5 PFLOPS | 7.5 PFLOPS* |
| TF32 Tensor Core | 989 TFLOPS | 989 TFLOPS | 1.8 PFLOPS | 2.2 PFLOPS | 3.3 PFLOPS* |
| FP32 (Dense) | 67 TFLOPS | 67 TFLOPS | 30 TFLOPS | 40 TFLOPS | Information Unknown |
| FP64 Tensor Core (Dense) | 67 TFLOPS | 67 TFLOPS | 30 TFLOPS | 40 TFLOPS | Information Unknown |
| FP64 (Dense) | 34 TFLOPS | 34 TFLOPS | 30 TFLOPS | 40 TFLOPS | Information Unknown |
| Max Power Consumption | 700W | 700W | 700W | 1000W | Information Unknown |
Note: Values marked with “*” are rough calculations and not official numbers from NVIDIA

The Blackwell Ultra B300, like its Blackwell counterparts, introduces new precision formats with FP4 Tensor Cores delivering an impressive 30 PFLOPS and FP6/FP8 offering 15 PFLOPS* of performance, compared to the current H200s. This is an approximate 7.5x improvement when comparing FP8 compute to FP4 and a nearly 4x improvement when comparing FP8 performance.

Next on NVIDIA’s roadmap is the Vera Rubin GPU, which is scheduled for release next year. Vera Rubin is expected to deliver 3.3x the performance of Blackwell Ultra, achieving 50 PFLOPS of dense FP4 compute up from the B300’s 15 PFLOPS. It will be accompanied by ConnectX-9 and NVLink-6 technologies, doubling the bandwidth of previous generations. Vera Rubin GPUs will also feature HBM4 memory, providing a 1.6x increase in memory bandwidth. Transitioning from Grace to Vera CPUs will also significantly enhance the CPU-to-GPU interconnect, achieving speeds of up to 1.8 TB/s.

NVIDIA didn’t hold back, teasing its Rubin Ultra GPUs, which are expected to launch in the second half of 2027. Rubin Ultra GPUs aim to double Vera Rubin’s performance, delivering an astounding 100 PFLOPS of dense FP4 compute per GPU. Rubin Ultra will also be equipped with 1TB of advanced HBM4e memory.
NVIDIA DGX Spark

NVIDIA showcased its DGX Spark, a system introduced under the Project Digits moniker, at CES earlier this year. Geared toward AI developers, researchers, data scientists, and students, DGX Spark harnesses the new GB10 Blackwell chip and is configured with 128 GB of unified memory.
NVIDIA claims that the system delivers an extraordinary 1,000 AI TOPS, which would put the Spark’s performance at a practical level equivalent to the RTX 5070. The Spark platform also integrates a ConnectX 7 SmartNIC, which equips the Spark with 2x 200Gb links to streamline data movement. OEM partners, including ASUS, Dell, HPE, and Lenovo, will soon offer branded versions. Reservations are already open, with shipments scheduled to commence in July.
NVIDIA DGX Station
NVIDIA also introduced the updated DGX Station, which is positioned as the ultimate desktop AI supercomputer for enterprise applications and is built with the GB300 Grace Blackwell Ultra chip.
The DGX Station offers 784GB of unified system memory while delivering 20 petaflops of dense FP4 AI performance. This integrates NVIDIA’s ConnectX 8 SuperNIC directly into the system, allowing for 800 Gb/s network connectivity, ensuring that high-performance networking meets the demands of its substantial compute capabilities. OEM partners such as ASUS, Box, Dell, HPE, Lambda, and Supermicro are slated to build DGX Station systems, with availability expected later this year.

NVIDIA RTX Pro Blackwell
The GPU gravy train didn’t stop there. NVIDIA unveiled its RTX Pro Blackwell series, a comprehensive refresh of its professional GPU lineup designed to accelerate AI, graphics, and simulation workloads across all platforms. This new generation spans desktop workstations, mobile systems, and servers, with the flagship RTX Pro 6000 Blackwell featuring an industry-leading 96GB of GPU memory and delivering up to 4,000 TOPS of AI performance. These advancements enable real-time ray tracing, rapid AI inference, and advanced graphics workflows previously unattainable on desktop systems.
The technological innovations packed into these GPUs are substantial, including NVIDIA’s Streaming Multiprocessor with 1.5x faster throughput, fourth-generation RT Cores delivering twice the performance of previous generations, and fifth-generation Tensor Cores supporting new FP4 precision for AI workloads. Additional enhancements include PCIe Gen 5 support for doubled bandwidth, DisplayPort 2.1 compatibility for extreme resolution display configurations, and, in the Server Edition, NVIDIA Confidential Computing for secure AI workloads.
Industry professionals have reported remarkable performance improvements in real-world applications. Foster + Partners achieved 5x faster ray-tracing than the RTX A6000, while GE HealthCare found up to 2x improvement in GPU processing time for medical reconstruction algorithms. Automotive manufacturer Rivian leveraged the new GPUs for unprecedented VR visual quality in design reviews, and SoftServe reported a 3x productivity boost when working with large AI models like Llama 3.3-70B. Perhaps most impressively, Pixar noted that 99% of their production shots now fit within the 96GB memory of a single GPU.

The RTX Pro 6000 Blackwell Server Edition takes these capabilities to data center environments with a passively cooled design for 24/7 operation. This server-focused variant delivers 5x higher large language model inference throughput, 7x faster genomics sequencing, 3.3x speedups for text-to-video generation, and 2x improvements in recommender systems inference and rendering compared to previous generation hardware. For the first time, these GPUs enable both vGPU and Multi-Instance GPU (MIG) technology, which allows each card to be partitioned into up to four fully isolated instances, maximizing resource utilization for diverse workloads. Desktop versions of these GPUs are set to hit the market in April, with server counterparts following in May and OEM-based laptops in June.
NVIDIA Photonics

NVIDIA Photonics, an innovation set to transform optical networking within AI data centers, rounded out the hardware announcements. By replacing traditional pluggable transceivers with co‑packaged optical engines located on the same package as the switch ASIC, NVIDIA Photonics minimizes power consumption and streamlines data connectivity.
Utilizing TSMC’s photonic engine optimizations and complemented by micro‑ring modulators, high‑efficiency lasers, and detachable fiber connectors, the new Photonics platform is engineered to deliver up to 3.5x better efficiency, 10x higher resiliency, and achieve deployment speeds 1.3x faster than conventional solutions. In demonstrating its broader ecosystem approach, NVIDIA detailed how its partnerships with advanced packaging and optical component manufacturing leaders are central to achieving these performance gains.
 With these new developments, NVIDIA showcased three new switches featuring the 200G SerDes in Quantum-X and Spectrum-X switch families. The Quantum-X Infiniband lineup includes the Quantum 3450-LD, which features an impressive 144 ports of 800G or 576 ports of 200G, delivering 115Tb/s of bandwidth. On the Spectrum-X Ethernet switches, the portfolio ranges from the more compact Spectrum SN6810, offering 128 ports of 800G or 512 ports of 200G, to the high-density Spectrum SN6800, boasting 512 ports of 800G and 2048 ports of 200G. All these switches feature liquid cooling technology to maintain optimal performance and efficiency.
With these new developments, NVIDIA showcased three new switches featuring the 200G SerDes in Quantum-X and Spectrum-X switch families. The Quantum-X Infiniband lineup includes the Quantum 3450-LD, which features an impressive 144 ports of 800G or 576 ports of 200G, delivering 115Tb/s of bandwidth. On the Spectrum-X Ethernet switches, the portfolio ranges from the more compact Spectrum SN6810, offering 128 ports of 800G or 512 ports of 200G, to the high-density Spectrum SN6800, boasting 512 ports of 800G and 2048 ports of 200G. All these switches feature liquid cooling technology to maintain optimal performance and efficiency.
The NVIDIA Quantum-X Photonics InfiniBand switches are expected to be available later this year, and the NVIDIA Spectrum-X Photonics Ethernet switches will be available in 2026 from leading infrastructure and system vendors.
Bringing Hardware and Software Together with Nvidia Dynamo
NVIDIA’s announcements were equal parts software and hardware. To fully harness the computational power of the new Blackwell GPUs, NVIDIA introduced Dynamo, an AI inference software designed specifically for serving AI models at scale.

NVIDIA Dynamo is an open-source inference platform engineered to optimize the deployment of large-scale AI models across entire data centers. Dynamo’s unique distributed and disaggregated architecture allows it to scale a single query across many GPUs, dramatically accelerating inference workloads. By intelligently splitting processing tasks between input token computation and output tokens and leveraging the strengths of NVIDIA’s NVLink interconnect, it achieves up to 30x performance improvements for reasoning-intensive models like DeepSeek R1.
Remarkably, Dynamo even doubles the throughput of existing LLMs, such as LLAMA, on Hopper GPUs without additional hardware, effectively doubling token generation and revenue potential for AI factories. With Dynamo, NVIDIA is bringing hyperscale-level optimizations to everyone and making them available, allowing everyone to fully capitalize on AI’s transformative potential.
Dynamo is available today on GitHub and supports popular backends, including PyTorch, BLM, SGLang, and TensorRT.
Nvidia AI-Q: The Next Generation of Agentic AI Systems
NVIDIA also introduced AI-Q, pronounced “I-Q,” a blueprint to connect AI agents seamlessly to large-scale enterprise data and tools. This open-source framework enables agents to query and reason across multiple data types, including text, images, and video, and leverage external tools such as web search and other agents.
At the core of AI-Q is the new NVIDIA AgentIQ toolkit, an open-source software library released today on GitHub. AgentIQ facilitates connecting, profiling, and optimizing multi-agent systems, enabling enterprises to build sophisticated digital workforces. AgentIQ integrates seamlessly with existing multi-agent frameworks, including CrewAI, LangGraph, Llama Stack, Microsoft Azure AI Agent Service, and Letta, allowing developers to adopt it incrementally or as a complete solution.
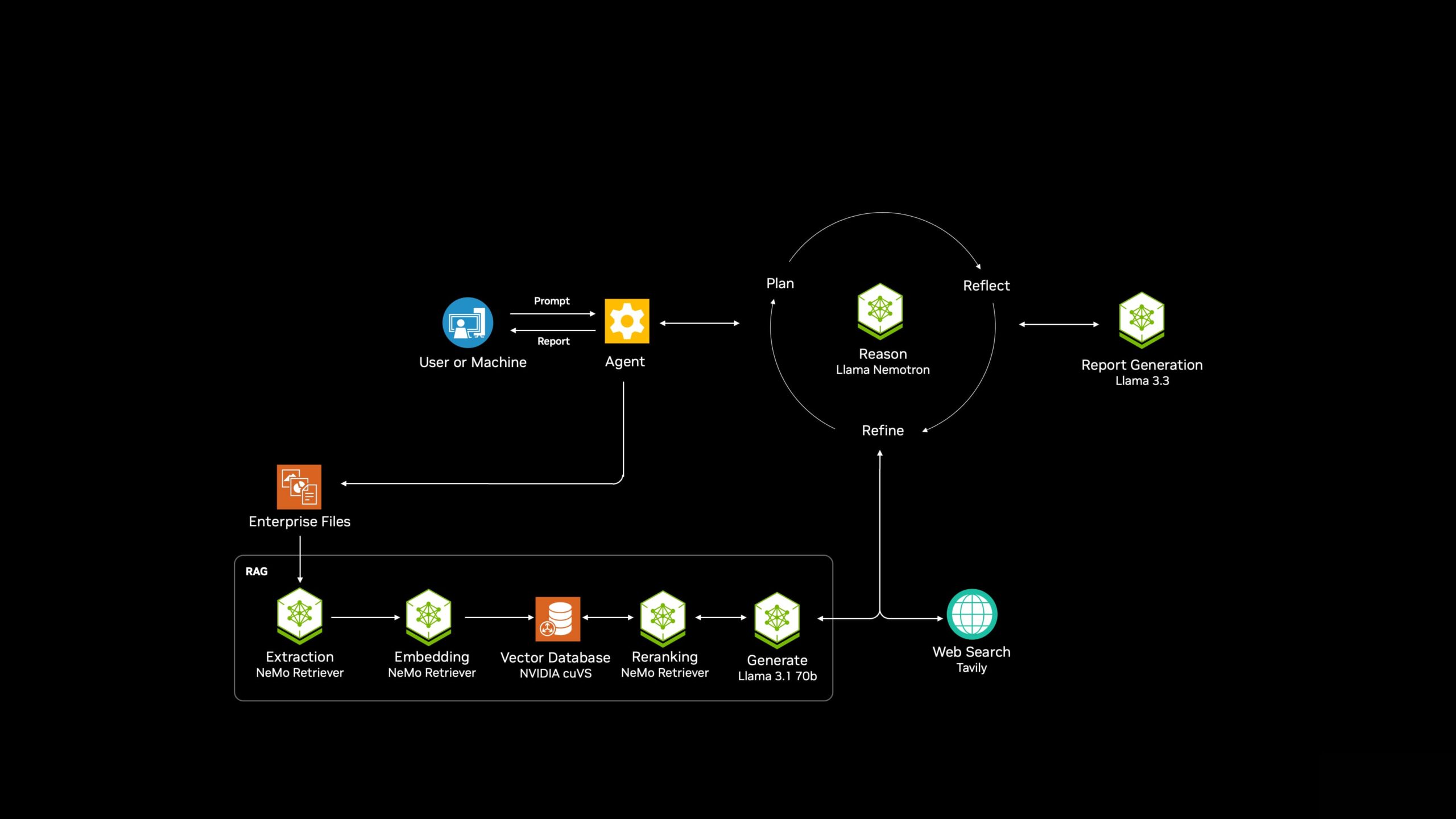
NVIDIA is also collaborating with leading data storage providers to create an AI data platform reference architecture that integrates NVIDIA NeMo Retriever, AI-Q Blueprint, Blackwell GPUs, Spectrum X networking, and Bluefield DPUs. To ensure near real-time data processing and rapid knowledge retrieval, empowering AI agents with essential business intelligence.
AI-Q will be available for developers to experience starting in April.
NVIDIA Mission Control: Orchestrating the AI Factory
Building on its comprehensive software strategy, NVIDIA unveiled Mission Control, the industry’s only unified operations and orchestration software platform designed to automate the complex management of AI data centers and workloads. While Dynamo optimizes inference and AI-Q enables agentic systems, Mission Control addresses the critical infrastructure layer that underpins the entire AI pipeline.
Mission Control transforms how enterprises deploy and manage AI infrastructure, automating end-to-end management, including provisioning, monitoring, and error diagnosis. The platform enables seamless transitions between training and inference workloads on Blackwell-based systems, allowing organizations to reallocate cluster resources as priorities shift dynamically. Incorporating NVIDIA’s acquired Run:ai tech, Mission Control boosts infrastructure utilization by up to 5x while delivering up to 10x faster job recovery than traditional methods requiring manual intervention.
The software provides several operational advantages critical for modern AI workloads, including simplified cluster setup, seamless workload orchestration for SUNK (Slurm and Kubernetes) workflows, energy-optimized power profiles with developer-selectable controls, and autonomous job recovery capabilities. Additional features include customizable performance dashboards, on-demand health checks, and building management system integration for enhanced cooling and power management.
Major system makers, including Dell, HPE, Lenovo, and Supermicro, have announced plans to offer NVIDIA GB200 NVL72 and GB300 NVL72 systems equipped with Mission Control. Dell will incorporate the software into its AI Factory with NVIDIA, while HPE will offer it with its Grace Blackwell rack-scale systems. Lenovo plans to update its Hybrid AI Advantage solutions to include Mission Control, and Supermicro will integrate it into their Supercluster systems.
NVIDIA Mission Control is already available for DGX GB200 and DGX B200 systems, with support for DGX GB300, DGX B300, and GB300 NVL72 systems expected later this year. For organizations looking to begin managing AI infrastructure, NVIDIA has also announced that Base Command Manager software will soon be free for up to eight accelerators per system, regardless of cluster size.
Conclusion
NVIDIA’s GTC 2025 has set the stage for a transformative leap in AI technology, unveiling groundbreaking advancements across hardware, software, and infrastructure. From the powerful B300 GPUs built on the Blackwell Ultra architecture to the revolutionary DGX Spark and DGX Station systems, NVIDIA continues to redefine what’s possible in AI computing. The introduction of NVIDIA Photonics, Dynamo inference software, AI-Q agentic frameworks, and Mission Control orchestration platform will help enterprises get to market faster and scale more efficiently and is undoubtedly going further to cement NVIDIA as a leader in this space.
Yet, this is just the tip of the iceberg. There is much more innovation and insight to explore at GTC. Stay tuned and watch for our other news articles this week as we continue to bring you the latest announcements and deep dives into NVIDIA’s exciting future.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed