
 Computing has changed dramatically, particularly in the last ten years. According to IDC, the rise of web and mobile applications, and the commoditization of content creation tools, has increased endpoint content consumption and content creation by at least 30 times. As such, companies today are looking to get more value out of the petabytes of data they now commonly store. Truly self-service clouds, operating at application and infrastructure layers, are now multi-billion dollar businesses. Sensor networks and other machine-to-machine interactions promise another exponential jump in data movement and storage. Yet in spite of all of these monumental changes in the usage of both data and content, outside of increases in capacity and processor power, common storage architectures have remained basically unchanged over the past twenty years. We are trying to compute at multi-petabyte scale with architectures designed for terabytes.
Computing has changed dramatically, particularly in the last ten years. According to IDC, the rise of web and mobile applications, and the commoditization of content creation tools, has increased endpoint content consumption and content creation by at least 30 times. As such, companies today are looking to get more value out of the petabytes of data they now commonly store. Truly self-service clouds, operating at application and infrastructure layers, are now multi-billion dollar businesses. Sensor networks and other machine-to-machine interactions promise another exponential jump in data movement and storage. Yet in spite of all of these monumental changes in the usage of both data and content, outside of increases in capacity and processor power, common storage architectures have remained basically unchanged over the past twenty years. We are trying to compute at multi-petabyte scale with architectures designed for terabytes.
By Leo Leung, VP of Corporate Marketing, Scality
Computing has changed dramatically, particularly in the last ten years. According to IDC, the rise of web and mobile applications, and the commoditization of content creation tools, has increased endpoint content consumption and content creation by at least 30 times. As such, companies today are looking to get more value out of the petabytes of data they now commonly store. Truly self-service clouds, operating at application and infrastructure layers, are now multi-billion dollar businesses. Sensor networks and other machine-to-machine interactions promise another exponential jump in data movement and storage. Yet in spite of all of these monumental changes in the usage of both data and content, outside of increases in capacity and processor power, common storage architectures have remained basically unchanged over the past twenty years. We are trying to compute at multi-petabyte scale with architectures designed for terabytes.
Software-Defined Storage (SDS) promises a more flexible storage model where storage truly becomes one of the services among other computing services. Hardware independence is part of this architecture as data and services must flow more freely when applications change and systems scale up and down. Instead of embedding data management functionality into proprietary closed appliances, SDS decouples this functionality from the hardware–enabling functionality that focuses on data–and naturally spans hardware. Like other infrastructure commoditization patterns over time (e.g. soft switches), this decoupling also exposes the inflated margins (60 percent) contained within storage appliances today.
Since SDS will often be deployed at multi-petabyte scale, availability must be extremely high and require no intervention on known failure scenarios. Application interfaces must be friendly to both existing applications and newer web and mobile-based apps. Performance should be strong, linearly scalable, and suitable for mixed workloads. Services like data protection and data recovery must be designed for the same level of dynamism and scaling.
This is in strong contrast with legacy storage architectures, which are completely tied to physical hardware, and embed availability, data access, performance, management, and durability capabilities within the limited scope of proprietary appliances. These legacy architectures are designed for smaller scale across each of the aforementioned dimensions.
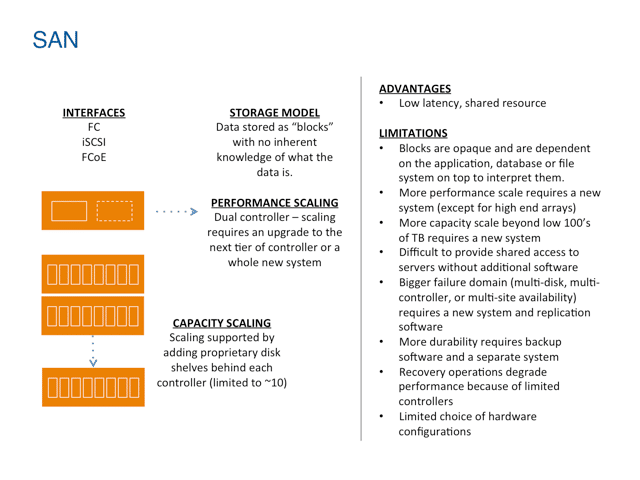
SAN is still a good approach for low latency access to data, but is poor at massive scale
SAN was designed as the most basic way to interface with storage over a dedicated local network. It controls blocks of data in small logical volumes, but has no context of what the data is and depends entirely on the application to organize, catalog and structure the data. By design, SANs are limited in scale, interfaces, and scope, and typically higher in cost due to the dedicated network infrastructure.
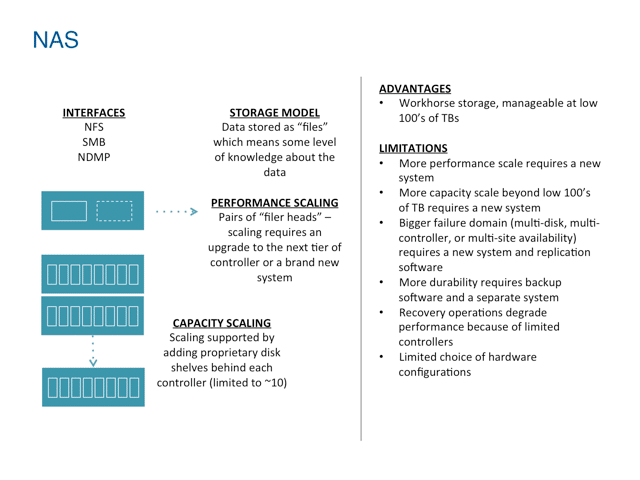
File is still dominant and NAS is a workhorse, but is challenged at scale
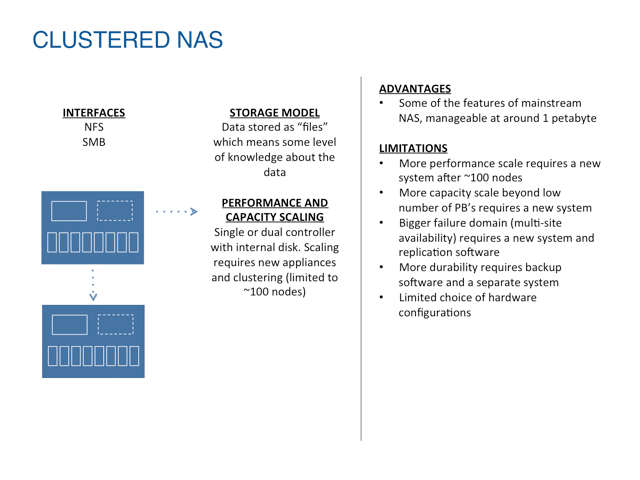
NAS was also designed as a way to interface with locally networked storage, but provides more structure in the form of file systems and files. File systems have natural limits based on the local internal structures used to manage the file hierarchy and file access. Because of the information within the managed file hierarchy, there is more basic awareness of the content in the system, but it is entirely localized to a physical storage controller. Also by design, NAS systems are limited in scale and scope. Clustered NAS systems extend the scalability of the technology, but also have natural limits tied to physical controllers (numbering in the 10’s) and the central database used to keep track of the file hierarchy and files.
Object Storage addressed scale, but is very limited in workload support
Object Storage is a technology that creates additional abstraction, often on top of and across local file systems. This means data in the system is managed as objects (instead of blocks or files) across a global namespace, with unique identifiers for each object. This namespace can span hundreds of servers, enabling easier scaling of capacity than either SAN or NAS models.
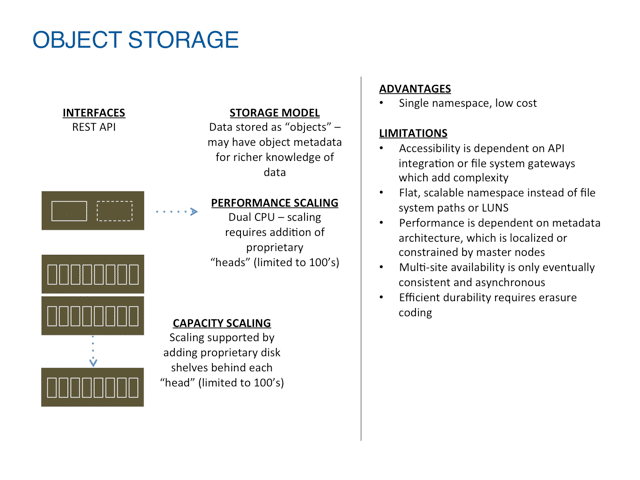
However, object stores are fundamentally limited in application support because they require applications to be rewritten to a specific flavors of HTTP API and performance is typically limited to write once, read many (WORM) or write once, read never scenarios. This lack of performance is due to architectures that force traffic through a limited set of metadata nodes, which sometimes adds overhead to these limited nodes with services like erasure coding.
Software-Defined Storage is designed holistically for massive scale
Software-Defined Storage is a new approach that completely decouples storage functionality from specific hardware, and enables more flexible deployment, scalability, accessibility, and operation as a result.

The decoupling of SDS allows the software to leverage the hardware independently, scaling capacity, performance, and accessibility independently based on the use case. This type of customization is impossible outside of the highest-end traditional storage, which has purpose-built hardware components for this purpose, ultimately still limiting flexibility and total scale.
Decoupling of storage functionality from the hardware also makes it easier to identify issues in the overall system, instead of having to troubleshoot appliances that combine hardware and software exception handling into a low signal-to-noise stack.
Beyond the base separation of software and hardware, the SDS storage services also take advantage of the decoupling by offering capacity, availability, durability and accessibility services that can span physical boundaries. A common attribute of SDS is the use of object storage to create a nearly unlimited namespace of unique objects. This transcends the units of management of logical unit numbers (LUNs) and file systems, which have fundamental scale limits by design. This allows an SDS system to scale simply by adding more physical capacity without adding new units of management.
Availability of SDS systems can also be vastly superior, leveraging the private network space among SDS nodes. Instead of the limited active/passive controller arrangement of most SAN and NAS systems, or the clustered arrangement of scale-out NAS, SDS systems can continue to scale to the thousands of addresses within a domain. Furthermore, SDS systems can also take advantage of advanced routing algorithms to guarantee response even in massive scale topologies and in the face of multiple failure scenarios. This goes well beyond the simple switched fabrics or daisy chains of traditional storage where an entire array can go down due to a simple cabling mistake.
The durability of traditional storage systems is designed to support the occasional failure of a disk or two, with nearly immediate replacement required. In a petabyte-scale system, the number of disks starts in the hundreds, and often grows to the thousands. Even with a high mean time between failures (MTBF), several disks will always be down. SDS systems are designed to expect many failures and many different failure domains. They take natural advantage of distributed capacity and processing for distributed protection schemes and extremely fast rebuilds. This is necessary at scale versus the dual controller scheme of scale up architectures, which have severe bottlenecks during disk rebuilds, or other storage services.
Accessibility was of minor concern in traditional storage systems. Application servers or mainframes were on local, storage-specific networks with a few mature protocols. Shared Ethernet networks and mixed public and private access are now the norm. SDS systems must support a much broader set of requirements. From web-based to Ethernet-based access, from storage resources being network-based to being deployed as a local resource on the application server – SDS has to support them all.
As indicated throughout this article, traditional storage is highly specialized, leading to many silos of functionality and data throughout a typical large business. This is not only highly inefficient from an operational perspective, but also yields no economies of scale and drastically limits opportunities for data sharing and reuse.
SDS is designed to meet the majority of application integration requirements, with protocols varying from persistent to stateless, from simple to highly interactive and semantically rich. This enables a general-purpose environment, where storage can be a general service for applications, regardless of whether they have small or large files, different protection requirements, and different protocol needs. This collapses the current boundaries between NAS, object, and tape storage, unlocking the leverage that the hyperscale players have enjoyed for years, and updating storage services for a world where connectivity has broadened to billions of endpoints.
In summary, applications and requirements have changed dramatically. With 90 percent of all data create in just the last two years ; we are squarely in the Petabyte era, with Exabytes just around the corner. The pain of petabyte-scale and the quest for improved data value has become the catalyst to consider new approaches as decades-old traditional approaches hit their designed limits and are overwhelmed.
About the author
You can follow Leo Leung on Twitter or view his website at techexpectations.org.