

In het razendsnelle, steeds evoluerende landschap van kunstmatige intelligentie (AI) komt de NVIDIA DGX GH200 naar voren als een baken van innovatie. Deze krachtpatser van een systeem, ontworpen met de meest veeleisende AI-workloads in het achterhoofd, is een complete oplossing die een revolutie teweegbrengt in de manier waarop ondernemingen Generative AI benaderen. NVIDIA heeft nieuwe details die laten zien hoe de GH200 samenkomt en biedt een piek in hoe AI-prestaties eruit zien met deze nieuwste generatie GPU-technologie.
In het razendsnelle, steeds evoluerende landschap van kunstmatige intelligentie (AI) komt de NVIDIA DGX GH200 naar voren als een baken van innovatie. Deze krachtpatser van een systeem, ontworpen met de meest veeleisende AI-workloads in het achterhoofd, is een complete oplossing die een revolutie teweegbrengt in de manier waarop ondernemingen Generative AI benaderen. NVIDIA heeft nieuwe details die laten zien hoe de GH200 samenkomt en biedt een piek in hoe AI-prestaties eruit zien met deze nieuwste generatie GPU-technologie.

NVIDIA DGX GH200: een complete oplossing
De DGX GH200 is niet alleen een fraai stukje rackhardware; het is een uitgebreide oplossing die high-performance computing (HPC) combineert met AI. Het is ontworpen om de meest complexe AI-workloads aan te kunnen en biedt een prestatieniveau dat werkelijk ongeëvenaard is.
De DGX GH200 brengt een complete hardwarestack samen, inclusief de NVIDIA GH200 Grace Hopper Superchip, NVIDIA NVLink-C2C, NVIDIA NVLink Switch System en NVIDIA Quantum-2 InfiniBand, in één systeem. NVIDIA ondersteunt dit alles met een geoptimaliseerde softwarestack die speciaal is ontworpen om de ontwikkeling van modellen te versnellen.
| Specificaties | Details |
|---|---|
| GPU | Trechter 96 GB HBM3, 4 TB/s |
| CPU | 72 Kernarm Neoverse V2 |
| CPU-geheugen | Tot 480 GB LPDDR5 met maximaal 500 GB/s, 4x energiezuiniger dan DDR5 |
| CPU-naar-GPU | NVLink-C2C 900 GB/s bidirectionele coherente link, 5x energiezuiniger dan PCIe Gen5 |
| GPU-naar-GPU | NVLink 900 GB/s bidirectioneel |
| Supersnelle I/O | 4x PCIe Gen5 x16 met maximaal 512 GB/s |
| TDP | Configureerbaar van 450W tot 1000W |
Uitgebreid GPU-geheugen
De NVIDIA Grace Hopper Superchip, uitgerust met zijn Extended GPU Memory (EGM)-functie, is ontworpen om applicaties te verwerken met enorme geheugenvoetafdrukken, groter dan de capaciteit van zijn eigen HBM3- en LPDDR5X-geheugensubsystemen. Met deze functie hebben GPU's toegang tot maximaal 144 TB geheugen van alle CPU's en GPU's in het systeem, waarbij gegevens kunnen worden geladen, opgeslagen en atomaire bewerkingen kunnen worden uitgevoerd met LPDDR5X-snelheden. De EGM kan worden gebruikt met standaard MAGNUM IO-bibliotheken en is toegankelijk voor de CPU en andere GPU's via NVIDIA NVLink- en NVLink-C2C-verbindingen.
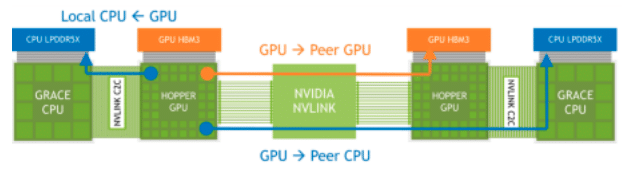
NVLink-geheugentoegang via verbonden Grace Hopper-superchips
NVIDIA zegt dat de Extended GPU Memory (EGM)-functie op de NVIDIA Grace Hopper Superchip de training van Large Language Models (LLM's) aanzienlijk verbetert door een enorme geheugencapaciteit te bieden. Dit komt omdat LLM's doorgaans enorme hoeveelheden geheugen nodig hebben om hun parameters en berekeningen op te slaan en trainingsdatasets te beheren.
Doordat ze toegang hebben tot maximaal 144 TB geheugen van alle CPU's en GPU's in het systeem, kunnen modellen efficiënter en effectiever worden getraind. Een grote geheugencapaciteit zou moeten leiden tot hogere prestaties, complexere modellen en de mogelijkheid om met grotere, meer gedetailleerde datasets te werken, waardoor mogelijk de nauwkeurigheid en bruikbaarheid van deze modellen wordt verbeterd.
NVLink-schakelsysteem
Aangezien de eisen van Large Language Models (LLM's) de grenzen van netwerkbeheer blijven verleggen, blijft NVIDIA's NVLink Switch System een robuuste oplossing. Dit systeem maakt gebruik van de kracht van NVLink-technologie van de vierde generatie en NVSwitch-architectuur van de derde generatie en levert connectiviteit met hoge bandbreedte en lage latentie voor een indrukwekkende 256 NVIDIA Grace Hopper Superchips binnen het DGX GH200-systeem. Het resultaat is maar liefst 25.6 Tbps aan full-duplex bandbreedte, wat een aanzienlijke sprong voorwaarts betekent in de snelheid van gegevensoverdracht.

DGX GH200 Supercomputer NVSwitch 4e generatie NVLink Logica Overzicht
In het DGX GH200-systeem is elke GPU in wezen een nieuwsgierige buurman, die in staat is om in het HBM3- en LPDDR5X-geheugen van zijn collega's op het NVLink-netwerk te prikken. In combinatie met de NVIDIA Magnum IO-versnellingsbibliotheken optimaliseert deze "nieuwsgierige buurt" GPU-communicatie, schaalt efficiënt op en verdubbelt de effectieve netwerkbandbreedte. Dus terwijl je LLM-training een boost krijgt en de communicatie-overheadkosten stijgen, krijgen AI-operaties een turboboost.
Het NVIDIA NVLink Switch-systeem in de DGX GH200 kan de training van modellen zoals LLM's aanzienlijk verbeteren door connectiviteit met hoge bandbreedte en lage latentie tussen een groot aantal GPU's mogelijk te maken. Dit leidt tot snellere en efficiëntere gegevensuitwisseling tussen GPU's, waardoor de trainingssnelheid en efficiëntie van het model worden verbeterd. Bovendien vergroot het vermogen van elke GPU om toegang te krijgen tot peer-geheugen van andere Superchips op het NVLink-netwerk het beschikbare geheugen, wat van cruciaal belang is voor LLM's met grote parameters.
Hoewel de indrukwekkende prestaties van de Grace Hopper Superchips onbetwistbaar een game-changer zijn op het gebied van AI-berekeningen, vindt de echte magie van dit systeem plaats in de NVLink, waar connectiviteit met hoge bandbreedte en lage latentie tussen talloze GPU's het delen van gegevens en efficiëntie mogelijk maakt naar een geheel nieuw niveau.
DGX GH200 systeemarchitectuur
De architectuur van de DGX GH200-supercomputer is complex, maar toch zorgvuldig ontworpen. Bestaande uit 256 GH200 Grace Hopper-computertrays en een NVLink-schakelsysteem dat een NVLink-vetboom met twee niveaus vormt. Elke rekentray bevat een GH200 Grace Hopper Superchip, netwerkcomponenten, een beheersysteem/BMC en SSD's voor gegevensopslag en uitvoering van het besturingssysteem.
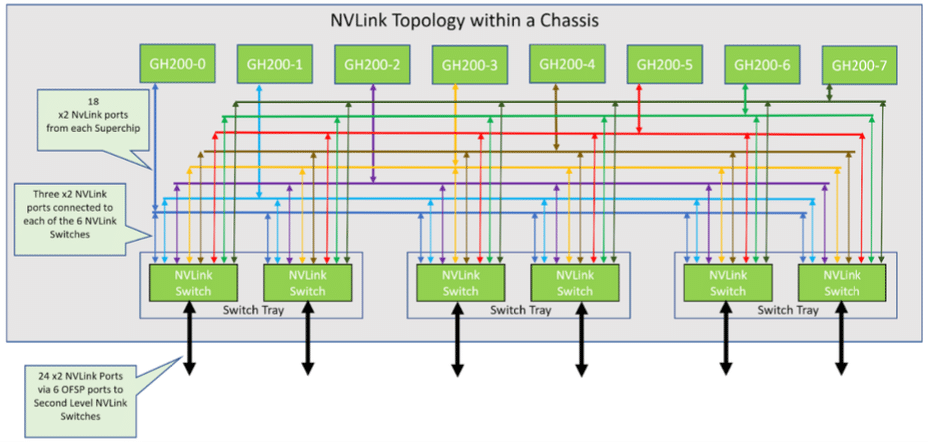
NVLink-topologie in 8-GraceHopper Superchip-chassis
| Categorie | Details |
|---|---|
| CPU / GPU | 1x NVIDIA Grace Hopper Superchip met NVLink-C2C |
| GPU/GPU | 18x NVLink-poorten van de vierde generatie |
| Netwerken | 1x NVIDIA ConnectX-7 met OSFP: > NDR400 InfiniBand Compute-netwerk 1x Dual-poort NVIDIA BlueField-3 met 2x QSFP112 of 1x Dual-poort NVIDIA ConnectX-7 met 2x QSFP112: > 200 GbE In-band Ethernet-netwerk > NDR200 IB-opslagnetwerk Out-of-band netwerk: > 1 GbE RJ45 |
| Opbergen | Gegevensschijf: 2x 4 TB (U.2 NVMe SSD's) SW RAID 0 OS Schijf: 2x 2 TB (M.2 NVMe SSD's) SW RAID 1 |
In deze opstelling zijn acht compute-trays gekoppeld aan drie NVLink NVSwitch-trays van het eerste niveau om een enkel 8-GPU-chassis tot stand te brengen. Elke NVLink Switch-tray heeft twee NVSwitch ASIC's die verbinding maken met de compute-trays via een aangepaste blinde kabelpatroon en met de NVLink-switches op het tweede niveau via LinkX-kabels.
Het resulterende systeem omvat 36 NVLink-switches van het tweede niveau die 32 chassis verbinden om de uitgebreide NVIDIA DGX GH200-supercomputer te vormen. Raadpleeg voor meer informatie Tabel 2 voor specificaties van de compute tray met Grace Hopper Superchip en Tabel 3 voor NVLink Switch-specificaties.
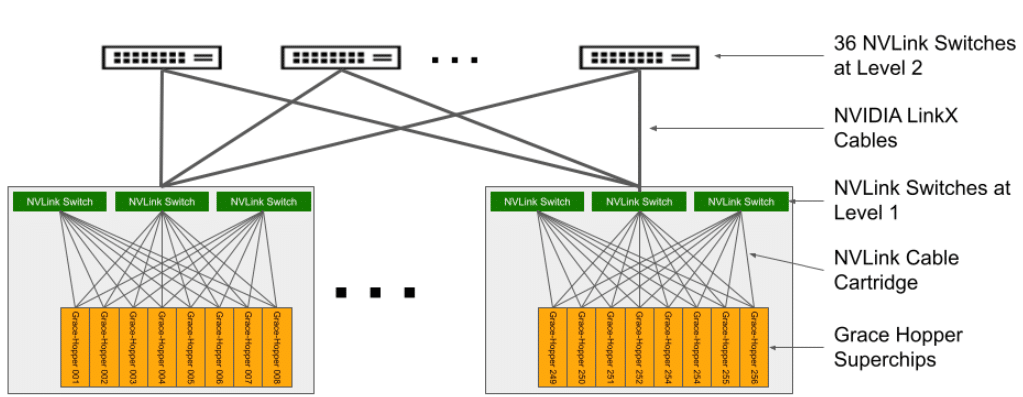
DGX GH200 NVLink-topologie
Netwerkarchitectuur van de DGX GH200
Het NVIDIA DGX GH200-systeem bevat vier geavanceerde netwerkarchitecturen om geavanceerde computer- en opslagoplossingen te bieden. Ten eerste vormt een Compute InfiniBand Fabric, opgebouwd uit NVIDIA ConnectX-7- en Quantum-2-switches, een voor rail geoptimaliseerde, full-fat tree NDR400 InfiniBand-fabric, waardoor naadloze connectiviteit tussen meerdere DGX GH200-eenheden mogelijk wordt.
Ten tweede levert de Storage Fabric, aangestuurd door de NVIDIA BlueField-3 Data Processing Unit (DPU), hoogwaardige opslag via een QSFP112-poort. Dit brengt een speciaal, aanpasbaar opslagnetwerk tot stand dat vakkundig verkeersopstoppingen voorkomt.
De in-band Management Fabric dient als de derde architectuur, verbindt alle systeembeheerservices en vergemakkelijkt de toegang tot opslagpools, in-systeemservices zoals Slurm en Kubernetes en externe services zoals de NVIDIA GPU Cloud.
Ten slotte houdt de out-of-band Management Fabric, werkend op 1GbE, toezicht op essentieel out-of-band beheer voor de Grace Hopper-superchips, BlueField-3 DPU en NVLink-switches via de Baseboard Management Controller (BMC), waardoor operaties worden geoptimaliseerd en voorkomen conflicten met andere diensten.
Ontketen de kracht van AI – NVIDIA DGX GH200 Software Stack
De DGX GH200 heeft alle brute kracht die ontwikkelaars maar kunnen wensen; het is veel meer dan alleen een mooie supercomputer. Het gaat erom die kracht te benutten om AI vooruit te helpen. De softwarestack die bij de DGX GH200 wordt geleverd, is ongetwijfeld een van de opvallende kenmerken.
Deze veelomvattende oplossing omvat verschillende geoptimaliseerde SDK's, bibliotheken en tools die zijn ontworpen om de mogelijkheden van de hardware volledig te benutten, waardoor efficiënte schaalvergroting van toepassingen en verbeterde prestaties worden gegarandeerd. De breedte en diepte van de softwarestack van de DGX GH200 verdient echter meer dan een terloopse vermelding. NVIDIA's whitepaper over het onderwerp voor een diepe duik in de softwarestack.
Opslagvereisten van de DGX GH200
Om de mogelijkheden van het DGX GH200-systeem volledig te benutten, is het cruciaal om het te combineren met een uitgebalanceerd, krachtig opslagsysteem. Elk GH200-systeem heeft de capaciteit om gegevens te lezen of te schrijven met snelheden tot 25 GB/s via de NDR200-interface. Voor een 256 Grace Hopper DGX GH200-configuratie stelt NVIDIA een totale opslagsnelheid van 450 GB/s voor om de leesdoorvoer te maximaliseren.
De noodzaak om AI-projecten en de onderliggende GPU's van brandstof te voorzien met de juiste opslag, is de meest populaire talkshow op de beurzen van de zomer. Vrijwel letterlijk elke show waar we zijn geweest, heeft een deel van hun keynote gewijd aan AI-workflows en opslag. Het valt echter nog te bezien hoeveel van dit gepraat slechts gaat over het herpositioneren van bestaande opslagproducten en hoeveel ervan leidt tot zinvolle verbeteringen voor AI-opslag. Op dit moment is het te vroeg om te zeggen, maar we horen veel gerommel van opslagleveranciers die het potentieel hebben om te leiden tot een zinvolle verandering voor AI-workloads.
Eén hindernis gesprongen, er volgen er meer
Hoewel de DGX GH200 het hardware-ontwerpaspect van AI-ontwikkeling stroomlijnt, is het belangrijk om te erkennen dat er op het gebied van generatieve AI nog andere aanzienlijke uitdagingen zijn; het genereren van trainingsgegevens.
De ontwikkeling van een Generative AI-model vereist een immens volume aan hoogwaardige data. Maar data, in ruwe vorm, is niet direct bruikbaar. Het vereist uitgebreide inspanningen op het gebied van verzamelen, opschonen en labelen om het geschikt te maken voor het trainen van AI-modellen.
Het verzamelen van gegevens is de eerste stap en omvat het zoeken en verzamelen van grote hoeveelheden relevante informatie, wat vaak tijdrovend en duur kan zijn. Vervolgens komt het proces voor het opschonen van gegevens, dat nauwgezette aandacht voor detail vereist om fouten te identificeren en te corrigeren, ontbrekende invoer te verwerken en irrelevante of overbodige gegevens te verwijderen. Ten slotte omvat de taak van het labelen van gegevens, een essentiële fase in begeleid leren, het classificeren van elk gegevenspunt zodat de AI het kan begrijpen en ervan kan leren.
De kwaliteit van de trainingsgegevens staat voorop. Vuile, slechte kwaliteit of bevooroordeelde gegevens kunnen leiden tot onnauwkeurige voorspellingen en gebrekkige besluitvorming door de AI. Er is nog steeds behoefte aan menselijke expertise en er zijn enorme inspanningen nodig om ervoor te zorgen dat de gegevens die in de training worden gebruikt zowel overvloedig als van de hoogste kwaliteit zijn.
Deze processen zijn niet triviaal en vereisen aanzienlijke middelen, zowel menselijk als kapitaal, inclusief gespecialiseerde kennis van de trainingsgegevens, wat de complexiteit van AI-ontwikkeling buiten de hardware onderstreept. Een deel hiervan wordt aangepakt met projecten zoals NeMo vangrails die is ontworpen om generatieve AI nauwkeurig en veilig te houden.
Sluiting Gedachten
De NVIDIA DGX GH200 is een complete oplossing die gepositioneerd is om het AI-landschap opnieuw te definiëren. Met zijn ongeëvenaarde prestaties en geavanceerde mogelijkheden is het een game-changer die klaar is om de toekomst van AI te stimuleren. Of u nu een AI-onderzoeker bent die de grenzen van wat mogelijk is wil verleggen of een bedrijf dat de kracht van AI wil benutten, de DGX GH200 is een hulpmiddel dat u kan helpen uw doelen te bereiken. Het zal intrigerend zijn om te zien hoe het genereren van trainingsgegevens wordt aangepakt naarmate onbewerkte rekenkracht wijdverspreider wordt. Dit aspect wordt vaak over het hoofd gezien in discussies over hardware releases.
Alles bij elkaar genomen is het belangrijk om de hoge kosten van het DGX GH200-systeem te erkennen. De DGX GH200 is niet goedkoop en zijn premium prijskaartje plaatst hem vierkant binnen het bereik van de grootste ondernemingen en de best gefinancierde AI-bedrijven (NVIDIA, hit me up, ik wil er een), maar voor die entiteiten die het zich kunnen veroorloven daarmee vertegenwoordigt de DGX GH200 een paradigmaverschuivende investering, een investering die het potentieel heeft om de grenzen van de ontwikkeling en toepassing van AI opnieuw te definiëren.
Naarmate meer grote ondernemingen deze technologie omarmen en geavanceerde AI-oplossingen beginnen te creëren en in te zetten, zou dit kunnen leiden tot een bredere democratisering van AI-technologie. Innovaties zullen hopelijk doorsijpelen in meer kosteneffectieve oplossingen, waardoor AI toegankelijker wordt voor kleinere bedrijven. Cloudgebaseerde toegang tot DGX GH200-achtige rekenkracht wordt steeds breder beschikbaar, waardoor kleinere bedrijven de mogelijkheden ervan kunnen benutten op basis van betalen per gebruik. Hoewel de initiële kosten hoog kunnen zijn, kan de invloed van de DGX GH200 op de lange termijn door de industrie heen sijpelen, waardoor het speelveld voor bedrijven van elke omvang gelijk wordt.
Neem contact op met StorageReview
Nieuwsbrief | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed