

De nieuwste MLPerf-resultaten zijn gepubliceerd, waarbij NVIDIA de hoogste prestaties en efficiëntie levert van de cloud tot de edge voor AI-inferentie. MLPerf blijft een nuttige maatstaf voor AI-prestaties als een onafhankelijke benchmark van derden. Het AI-platform van NVIDIA staat sinds de start van MLPerf bovenaan de lijst voor training en inferentie, inclusief de nieuwste MLPerf Inference 3.0-benchmarks.
De nieuwste MLPerf-resultaten zijn gepubliceerd, waarbij NVIDIA de hoogste prestaties en efficiëntie levert van de cloud tot de edge voor AI-inferentie. MLPerf blijft een nuttige maatstaf voor AI-prestaties als een onafhankelijke benchmark van derden. Het AI-platform van NVIDIA staat sinds de start van MLPerf bovenaan de lijst voor training en inferentie, inclusief de nieuwste MLPerf Inference 3.0-benchmarks.
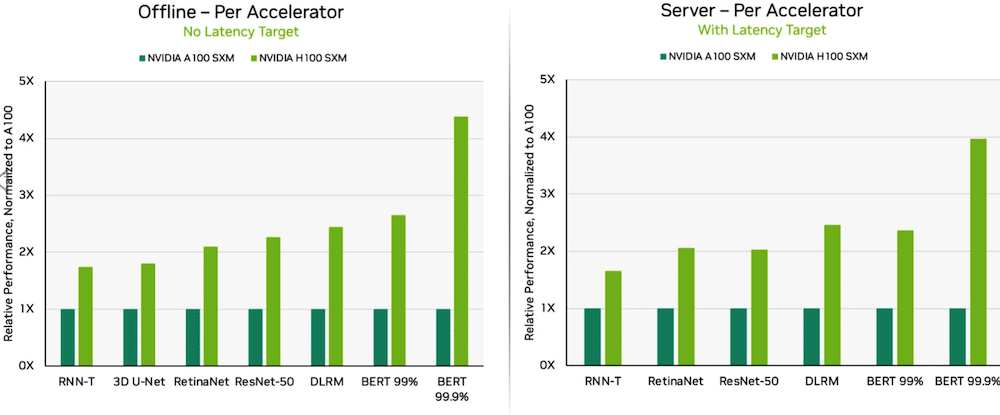
Dankzij software-optimalisaties leverden NVIDIA H100 Tensor Core GPU's in DGX H100-systemen de hoogste prestaties in elke test van AI-inferentie, een stijging van 54 procent ten opzichte van het debuut in september. In de gezondheidszorg leverden H100 GPU's een prestatiewinst van 31 procent ten opzichte van 3D-UNet, de MLPerf-benchmark voor medische beeldvorming.

Dell PowerEdge XE9680 met 8X H100 GPU's
Aangedreven door zijn Transformer Engine, blonk de H100 GPU, gebaseerd op de Hopper-architectuur, uit op BERT. BERT is een door Google ontwikkeld model voor natuurlijke taalverwerking dat bidirectionele representaties van tekst leert om het contextuele begrip van niet-gelabelde tekst voor veel verschillende taken aanzienlijk te verbeteren. Het is de basis voor een hele familie van BERT-achtige modellen zoals RoBERTa, ALBERT en DistilBERT.
Met Generative AI kunnen gebruikers snel tekst, afbeeldingen, 3D-modellen en nog veel meer maken. Bedrijven, van startups tot cloudserviceproviders, maken gebruik van generatieve AI om nieuwe bedrijfsmodellen mogelijk te maken en bestaande te versnellen. Een generatieve AI-tool die de laatste tijd in het nieuws is geweest, is ChatGPT, gebruikt door miljoenen mensen die onmiddellijke antwoorden verwachten na vragen en invoer.
Nu deep learning overal wordt ingezet, zijn prestaties op basis van inferentie van cruciaal belang, van fabrieksvloeren tot online aanbevelingssystemen.
L4 GPU's leveren verbluffende prestaties
Op zijn eerste reis, NVIDIA L4 Tensor Core GPU's presteerden meer dan 3x zo snel als T4 GPU's van de vorige generatie. De L4 GPU-versnellers, verpakt in een onopvallende vormfactor, zijn ontworpen om hoge doorvoer en lage latentie te leveren in vrijwel elk serverplatform. De L4 Tensor GPU's voerden alle MLPerf-workloads uit en dankzij hun ondersteuning voor het FP8-formaat waren de resultaten uitstekend op het prestatiehongerige BERT-model.
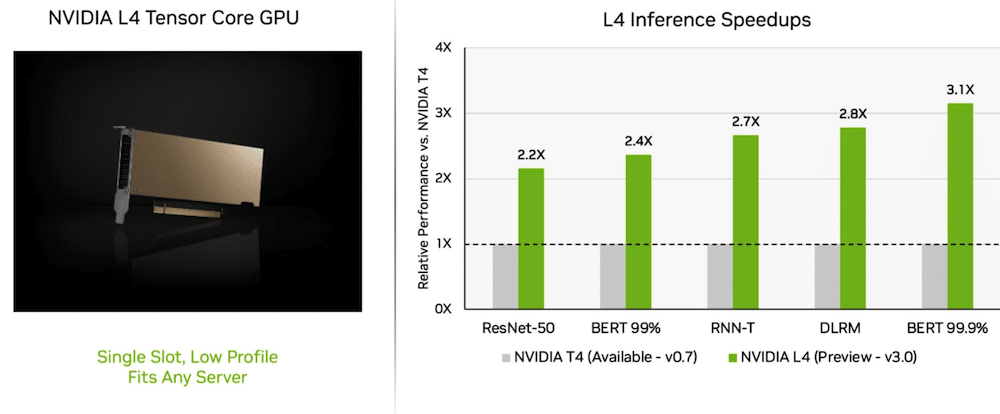
Naast de extreme AI-prestaties leveren L4 GPU's tot 10x snellere beelddecodering, tot 3.2x snellere videoverwerking en meer dan 4x snellere grafische en real-time weergaveprestaties. De accelerators, een paar weken geleden aangekondigd op GTC, zijn verkrijgbaar bij systeemmakers en cloudserviceproviders.
Welke netwerkafdeling?
NVIDIA's full-stack AI-platform heeft zijn waarde bewezen in een nieuwe MLPerf-test: Network-division benchmark!
De benchmark van de netwerkdivisie streamt gegevens naar een externe inferentieserver. Het weerspiegelt het heersende scenario van zakelijke gebruikers die AI-taken in de cloud uitvoeren met gegevens die zijn opgeslagen achter bedrijfsfirewalls.
Op BERT leverden externe NVIDIA DGX A100-systemen tot 96 procent van hun maximale lokale prestaties, gedeeltelijk vertraagd terwijl ze wachtten tot CPU's sommige taken hadden voltooid. Op de ResNet-50-test voor computervisie, die uitsluitend door GPU's wordt uitgevoerd, haalden ze 100%.
NVIDIA Quantum Infiniband-netwerken, NVIDIA ConnectX SmartNIC's en software zoals NVIDIA GPUDirect speelden een belangrijke rol in de testresultaten.
Orin verbetert aan de rand
Afzonderlijk leverde het NVIDIA Jetson AGX Orin systeem-op-module winsten op tot 63 procent in energie-efficiëntie en 81 procent in prestaties in vergelijking met de resultaten van vorig jaar. Jetson AGX Orin levert gevolgtrekking wanneer AI nodig is in besloten ruimtes met een laag vermogen, inclusief systemen op batterijen.
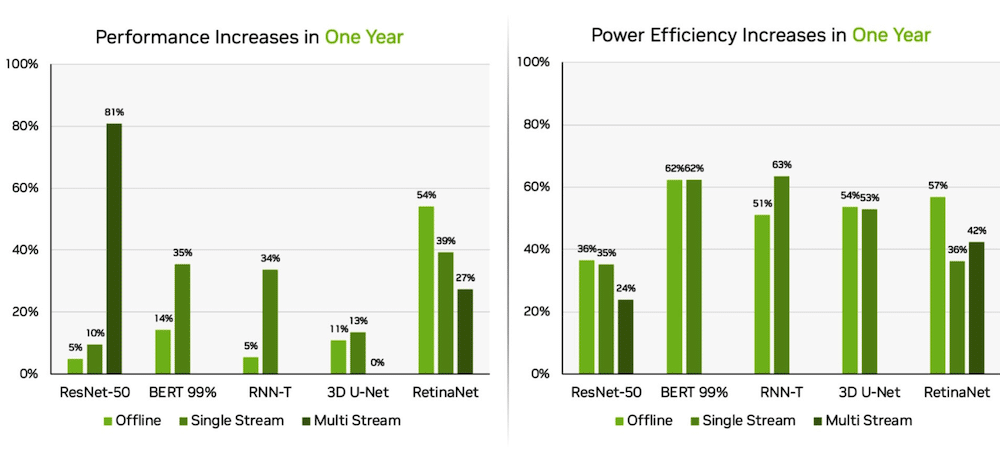
De Jetson Orin NX 16G, een kleinere module die minder stroom nodig heeft, presteerde goed in de benchmarks. Het leverde tot 3.2x de prestaties van de Jetson Xavier NX-processor.
NVIDIA AI-ecosysteem
De MLPerf-resultaten laten zien dat NVIDIA AI wordt ondersteund door een breed ecosysteem in machine learning. Tien bedrijven dienden in deze ronde resultaten in op het NVIDIA-platform, waaronder Microsoft Azure cloudservice- en systeemmakers, ASUS, Dell Technologies, GIGABYTE, H3C, Lenovo, Nettrix, Supermicro en xFusion. Hun werk illustreert dat gebruikers geweldige prestaties kunnen behalen met NVIDIA AI, zowel in de cloud als op servers die in hun eigen datacenters draaien.
Neem contact op met StorageReview
Nieuwsbrief | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed