
Optimaliseer LLM-inferentie met Pliops en vLLM. Verbeter prestaties, verlaag kosten en schaal AI-workloads met KV-cacheversnelling.
Pliops heeft een strategische samenwerking aangekondigd met de vLLM-productiestack, een open-source, clusterbrede referentie-implementatie die is ontworpen om grote taalmodel (LLM) inferentiewerklasten te optimaliseren. Deze samenwerking is cruciaal nu de AI-community zich voorbereidt om bijeen te komen op de GTC 2025-conferentie. Door de geavanceerde key-value (KV) storage backend van Pliops te combineren met de robuuste architectuur van de vLLM Production Stack, stelt de samenwerking een nieuwe maatstaf voor AI-prestaties, efficiëntie en schaalbaarheid.
Junchen Jiang, hoofd van het LMCache Lab aan de Universiteit van Chicago, benadrukte het potentieel van de samenwerking en benadrukte het vermogen om de efficiëntie en prestaties van LLM-inferentie te verbeteren. De gezamenlijke oplossing biedt geavanceerde Vector Search and Retrieval-mogelijkheden door een nieuwe petabyte-schaal geheugenlaag onder High Bandwidth Memory (HBM) te introduceren. Berekende KV-caches worden efficiënt bewaard en opgehaald met behulp van gedisaggregeerde slimme opslag, wat vLLM-inferentie versnelt.
Voor een inleiding tot Pliops, bekijk onze diepgaand artikel.
Over die KVCache
De meeste grote taalmodellen gebruiken transformerarchitecturen, die vertrouwen op aandachtsmechanismen met Query-, Key- en Value-matrices. Bij het sequentieel genereren van tokens berekenen transformers herhaaldelijk aandacht, wat de herberekening van eerdere Key- en Value (KV)-matrices vereist, wat leidt tot hogere rekenkosten. KV-caching pakt dit aan door eerder berekende KV-matrices op te slaan, wat hergebruik in latere tokenvoorspellingen mogelijk maakt, wat de generatie-efficiëntie en doorvoer aanzienlijk verbetert.
Dit brengt echter nieuwe uitdagingen met zich mee. KV-caches kunnen behoorlijk groot worden, met name tijdens lange generaties of batch-inferentie met typische batchgroottes van 32, en uiteindelijk het beschikbare geheugen overschrijden. Om deze beperking aan te pakken, wordt een KV-cacheopslagbackend essentieel.
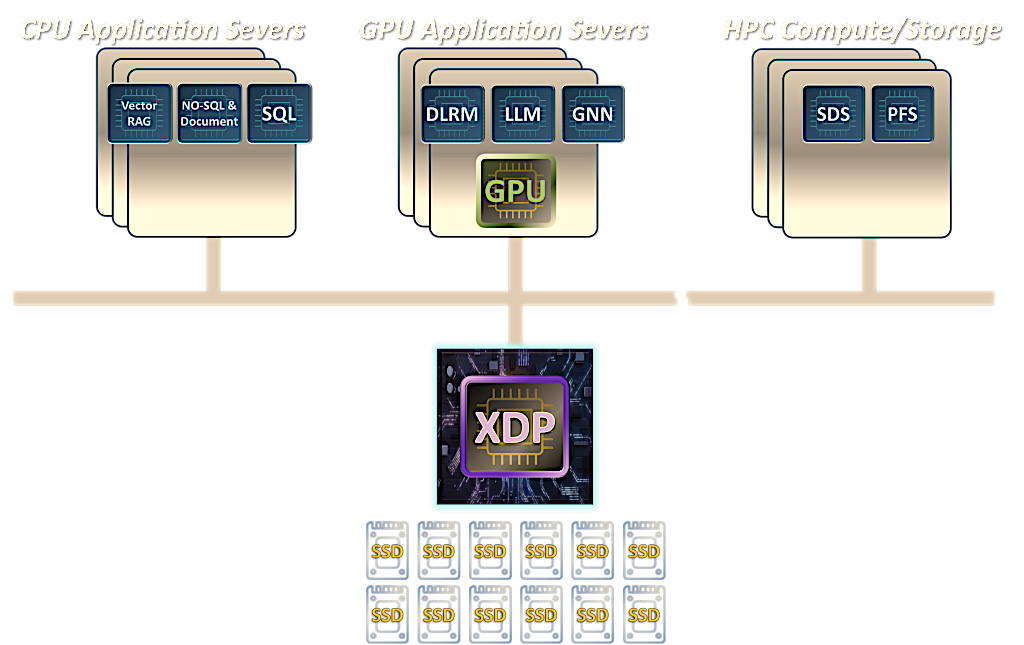
Pliops XDP LightningAI
Het implementeren van Pliops' XDP LightningAI in datacenters vertegenwoordigt een paradigmaverschuiving in kosteneffectiviteit, wat aanzienlijke kostenbesparingen oplevert in vergelijking met traditionele architecturen. Door speciale XDP LightningAI-servers toe te voegen naast bestaande infrastructuur, kunnen organisaties opmerkelijke besparingen realiseren, waaronder een optimalisatie van 67% in rackruimte, een vermindering van 66% in stroomverbruik, een jaarlijkse OpEx-besparing van 58% en een daling van 69% in initiële investeringskosten.
Pliops blijft vooruitgang boeken met zijn Extreme Data Processor (XDP), de XDP-PRO ASIC, aangevuld met een uitgebreide AI-softwarestack en gedistribueerde knooppunten. Door gebruik te maken van een GPU-geïnitieerde Key-Value I/O-interface, maakt deze oplossing ongekende schaalbaarheid en prestaties mogelijk. Pliops' XDP LightningAI levert substantiële end-to-end prestatieverbeteringen, met tot 8X winst voor vLLM-inferentie, wat Generative AI (GenAI)-workloads aanzienlijk versnelt. Met de integratie van geavanceerde industrietrends zoals DeepSeek, zorgt Pliops voor robuuste aanpasbaarheid voor toekomstige AI-ontwikkelingen.
Pliops toonde deze ontwikkelingen op AI DevWorld, waarbij werd benadrukt hoe XDP LightningAI de LLM-prestaties revolutioneert door de rekenkracht en kosten aanzienlijk te verminderen. Deze demonstratie illustreerde Pliops' toewijding om duurzame AI-innovatie op ondernemingsniveau mogelijk te maken.
Doorlopende samenwerking
Pliops zorgt ervoor dat organisaties het potentieel van AI-gestuurde inzichten optimaal kunnen benutten en een concurrentievoordeel kunnen behouden in een snel veranderend technologisch landschap. Dit doen ze door directe toegang te bieden tot bruikbare gegevens en een naadloos integratiepad te garanderen.
De toekomstige routekaart voor de samenwerking omvat de essentiële integratie van de KV-IO-stack van Pliops in de productiestack, waarbij wordt doorgegaan naar geavanceerde mogelijkheden zoals snelle caching voor multi-turn-conversaties, schaalbare KV-cache-offloading en gestroomlijnde routeringsstrategieën.
Neem contact op met StorageReview
Nieuwsbrief | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed