
Procyon blijft zijn benchmarksuite uitbreiden en zal binnenkort een reeks benchmarks en prestatietests voor professionele gebruikers aanbieden. De AI Text and Image Generation-benchmarks maken het werken met grote taal- en afbeeldingsmodellen eenvoudiger.
De AI Text and Image Generation benchmarks van Procyon zijn ontworpen om het werken met grote taal- en afbeeldingsmodellen eenvoudiger te maken. Deze tests zijn gestandaardiseerd, herhaalbaar en weerspiegelen scenario's uit de echte wereld, dus u hoeft zich geen zorgen te maken over de complexiteit van het meten van prestaties.
AI-tekst- en beeldgeneratieworkloads kunnen hardware tot het uiterste drijven, dus consistente en praktische benchmarks zijn essentieel. Of u nu tests uitvoert op een high-performance GPU of een kleinere neurale verwerkingseenheid, Procyon biedt duidelijke en bruikbare inzichten om u te helpen precies te begrijpen hoe uw hardware presteert.
Door de kloof tussen geavanceerde AI-mogelijkheden en praktische prestatiemeting te overbruggen, biedt Procyon gebruikers een intuïtieve manier om te zien hoe goed hun systemen de meest veeleisende AI-taken van vandaag de dag aankunnen.
De Procyon AI-tekstgeneratiebenchmark
De Procyon AI Text Generation Benchmark evalueert hoe effectief een computer of apparaat AI-modellen kan uitvoeren, zoals die achter tools als ChatGPT, om tekst te genereren. Het controleert hoe snel en soepel het systeem reacties kan produceren, content kan schrijven of informatie kan samenvatten wanneer het prompts krijgt, terwijl het ook controleert hoeveel van de bronnen van de computer, zoals de processor, grafische kaart en het geheugen, worden gebruikt tijdens het proces.
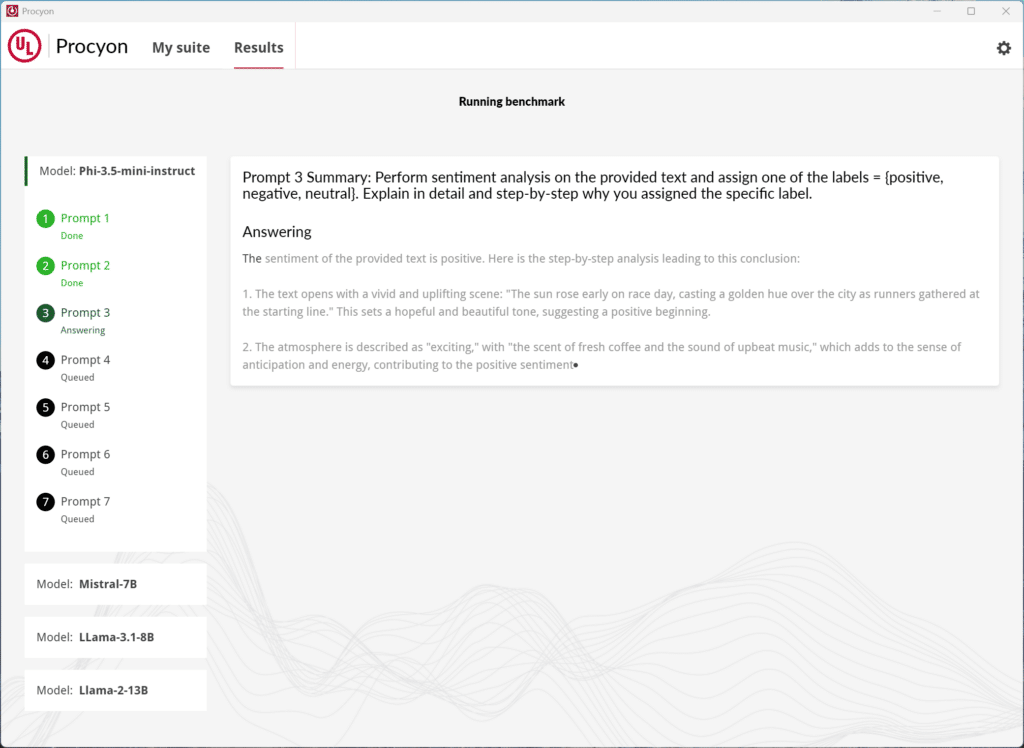
Het unieke aan de benchmark van Procyon is dat het de complexe taak van het evalueren van de prestaties van lokale grote taalmodellen (LLM) vereenvoudigt, waardoor het toegankelijk wordt voor gebruikers zoals zakelijke professionals, hardware-recensenten en engineeringteams. Traditionele benchmarking vereist aanzienlijke opslag, uitgebreide downloads en zorgvuldige configuratie om variabelen zoals kwantificering en tokenverwerking te beheren. Procyon stroomlijnt dit proces met een gestructureerd testframework en vooraf verpakte, geoptimaliseerde AI-modellen die consistente, herhaalbare resultaten leveren zonder de noodzaak van technische expertise of handmatige installatie.
Hoe Procyon AI-tekstgeneratie Werken en waarom het belangrijk is
Procyon automatiseert LLM-testen door vier algemeen erkende modellen vooraf te laden, wat snelle en betrouwbare prestatie-evaluatie van inferentietaken mogelijk maakt: de realtime generatie van tekst op basis van invoerprompts. Het bewaakt kritieke statistieken zoals tokens per seconde, latentie en hardwareresourcegebruik (CPU, GPU en geheugen) tijdens tests. Het platform biedt realtime inzichten en genereert gedetailleerde post-testrapporten die de inferentiesnelheid, mogelijke resourceknelpunten en algehele efficiëntie benadrukken.
Met deze resultaten kunnen gebruikers hun prestaties optimaliseren en kunnen bedrijven beoordelen hoe goed hun hardware veeleisende AI-workloads aankan.
Testscenario's voor de echte wereld
De benchmarkingsuite van Procyon simuleert realistische use cases met zeven verschillende testprompts, die twee belangrijke workloads bestrijken:
| Testtype | Werklastfocus | Invoer formaat | Voorbeelden van prominente use cases | Unieke functies |
| Retrieval-augmented generatie (RAG) | Ophalen met hoge complexiteit | Getokeniseerde gegevens | Kennisgebaseerde samenvattingen genereren | Test de nauwkeurigheid van de integratie van het ophalen |
| Creatieve niet-RAG-tekst | Vrije-vorm generatie | Natuurlijke taaltekst | Creatieve concepten en verhalen schrijven | Evalueert generatieve vloeiendheid |
- Retrieval-augmented generatie (RAG): RAG-taken meten hoe effectief een model externe kennis integreert in zijn antwoorden. Dit kan het genereren van samenvattingen of het beantwoorden van vragen omvatten waarvoor datatoegang buiten de trainingsset van de LLM vereist is.
- Creatieve Non-RAG:Bij taken waarbij vrije vormen worden gegenereerd, ligt de nadruk op het evalueren van de vloeiendheid van de tekst, de samenhang en de creatieve output wanneer het model uitsluitend op zijn interne training vertrouwt.
Procyon is geschikt voor toepassingen in de echte wereld door beide taken te bestrijken, waaronder AI-workflows voor ondernemingen (kennisophalen) en het genereren van creatieve content (vrije taken).
Procyon AI-beeldgeneratiebenchmark
Net als de tekstversie meet de Procyon AI Image Generation Benchmark hoe efficiënt een computer of apparaat AI-gestuurde taken voor het genereren van afbeeldingen verwerkt, zoals het omzetten van tekstprompts in afbeeldingen van hoge kwaliteit. Het werd ontwikkeld met input van leiders in de industrie om een reeks hardware te evalueren, van low-power neural processing units (NPU's) tot high-performance GPU's, met behulp van Stable Diffusion-modellen, die veel worden gebruikt voor het genereren van tekst naar afbeelding door professionals en alledaagse gebruikers.
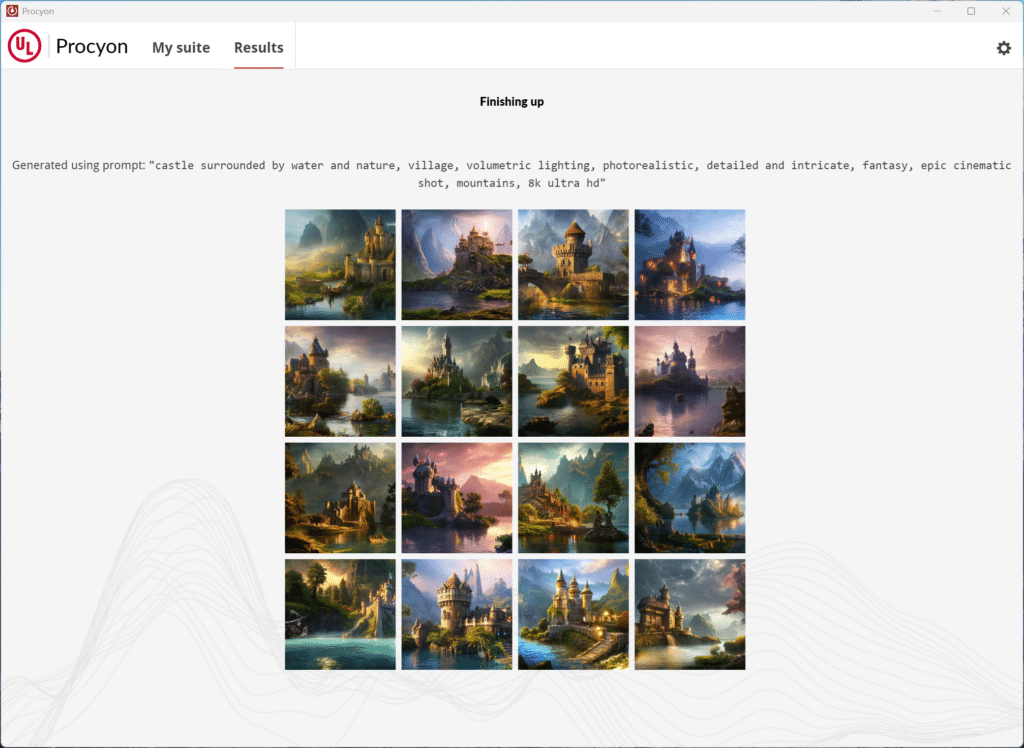
Wat maakt Procyon AI Image Generation tot een benchmark? Uniek?
De imagebenchmark van Procyon biedt drie afzonderlijke tests, die elk zijn afgestemd op verschillende hardwaremogelijkheden. Zo wordt een uitgebreide evaluatie voor verschillende apparaten gegarandeerd:
- Stabiele Diffusie XL (FP16): Ontworpen voor high-end GPU's, dit is de meest veeleisende test. Het genereert 1024×1024 resolutie afbeeldingen met 100 stappen.
- Stabiele diffusie 1.5 (FP16): Een evenwichtige werklast voor mid-range GPU's, die beelden produceert met een resolutie van 512×512 met een batchgrootte van 4 en 100 stappen.
- Stabiele diffusie 1.5 (INT8): Een geoptimaliseerde test voor apparaten met een laag stroomverbruik, zoals NPU's, waarbij de nadruk ligt op 512×512-afbeeldingen met lichtere instellingen van 50 stappen en één afbeeldingsbatch.
Hoe Procyon AI-beeldgeneratie Werken en waarom het belangrijk is
Procyon evalueert de prestaties van uw systeem door kritische factoren te meten, zoals de snelheid van het genereren van afbeeldingen, GPU-gebruik en algehele resource-efficiëntie. Het houdt realtime-statistieken bij, zoals GPU-temperatuur, kloksnelheden en geheugengebruik, terwijl het ook de kwaliteit van de gegenereerde afbeeldingen analyseert. Procyon ondersteunt ook meerdere inferentie-engines, waaronder NVIDIA TensorRT, Intel OpenVINO en ONNX met DirectML, waardoor het naadloos kan worden uitgevoerd op verschillende platforms en hardwareconfiguraties.
Aan het einde van de test genereert Procyon gedetailleerde rapporten met prestatiescores, resourcebottlenecks en de kwaliteit van de outputs, waardoor gebruikers een duidelijk inzicht krijgen in hoe goed hun hardware de rekenkundige eisen van tekst-naar-afbeeldingstaken aankan. Dit is geweldig voor een reeks use cases, of u nu een ontwikkelaar bent die AI-engines finetuned, een hardware-reviewer die systemen vergelijkt of een onderneming die workflows optimaliseert.
De benchmark zorgt voor betrouwbare vergelijkingen tussen hardware door het gebruik van tekstprompts en Stable Diffusion-modellen te standaardiseren. De bijbehorende rapporten stellen gebruikers in staat om de algehele prestatiescores en de kwaliteit van gegenereerde afbeeldingen te bekijken, wat een compleet beeld geeft van hoe hun systemen omgaan met de rekenkundige eisen van tekst-naar-afbeeldingstaken.
Benchmarking-testen
Bij het evalueren van systemen voor AI-workloads kan de hardware sterk variëren, van draagbare laptops voor consumenten tot high-end werkstations die zijn ontworpen voor professionele omgevingen. Elke configuratie heeft sterke en zwakke punten, waardoor het essentieel is om op verschillende platforms te testen om te begrijpen hoe verschillende hardwareprofielen veeleisende AI-taken aankunnen.
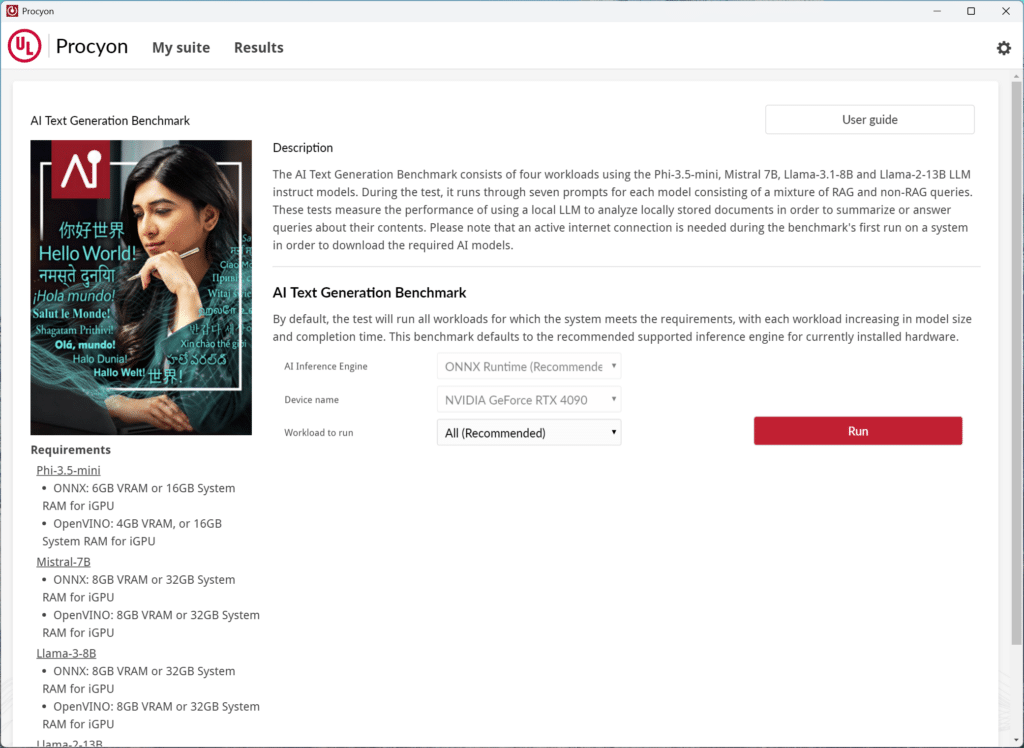
Voor deze analyse gebruikten we de Procyon-benchmarks op verschillende systemen, waaronder een gaming-laptop, een op ondernemingen gericht werkstation en twee veelzijdige professionele apparaten. De verscheidenheid stelde ons in staat om prestatieverschillen te observeren die werden beïnvloed door GPU-capaciteit, geheugenarchitectuur, opslagoplossingen en processortypen.
- Alienware-laptop: De Alienware laptop draait op Windows 11 Home en is een laptop voor consumenten die primair is ontworpen voor gaming, maar goed geschikt is voor AI-werklasten dankzij de uitgeruste NVIDIA RTX 4090 GPU. De Intel Core i9-14900KF-processor en 32 GB DDR4-geheugen zorgen voor solide rekenkracht, terwijl een Samsung PM9A1 NVMe SSD de opslag afhandelt.
- Precisie 5860-toren: De Precision 5860 Tower is gebouwd voor prestaties op ondernemingsniveau en beschikt over NVIDIA's RTX 6000 GPU, een professionele krachtpatser die is afgestemd op intensieve workloads zoals AI en 3D-rendering. De Intel Xeon w7-2595X CPU biedt verwerkingsmogelijkheden van werkstationklasse, aangevuld met 128 GB DDR5 RAM.
- Lenovo ThinkPads: De Lenovo ThinkPad combineert draagbaarheid met professionele prestaties, waardoor hij ideaal is voor gebruikers die mobiliteit nodig hebben zonder dat dit ten koste gaat van de capaciteit. Hij heeft een NVIDIA RTX A4000 GPU, een workstation-class kaart die is ontworpen voor AI en grafische workloads. Het systeem wordt aangestuurd door een Intel Xeon W-11955M processor, ondersteund door 32 GB DDR4 geheugen. De opslagoplossing is een Samsung 980 Pro SSD, een populaire NVMe drive.
- Lenovo ThinkStation: De Lenovo ThinkStation is een professioneel werkstation dat is ontworpen om de zwaarste rekenlasten aan te kunnen. Het is ontworpen voor piek-AI-inferentieprestaties met een NVIDIA RTX A5500 GPU en een Intel Xeon Gold 5420+ CPU. Ondersteund door 256 GB DDR5-geheugen biedt het immense multitasking- en gegevensverwerkingsmogelijkheden. Het systeem maakt gebruik van een Kioxia Exceria Pro SSD, een uiterst duurzame, snelle schijf die voldoet aan de eisen van grootschalige gegevensverwerking. Net als de anderen draait het op Windows 11 Pro.
Door deze systemen te testen met de Procyon AI-benchmarks kunnen we zien hoe deze tools in actie werken en tegelijkertijd laten zien hoe verschillende soorten hardware AI-taken verwerken. Of het nu gaat om een gaminglaptop met een consumenten-GPU van topklasse of een professioneel werkstation dat is gebouwd voor zware workloads, elke opstelling biedt iets unieks.
AI-tekstgeneratie
| Systeem | Model | Totale score | Uitvoertokens/s |
|---|---|---|---|
| Alienware-Procyon (NVIDIA RTX 4090, ONNXRuntime-DirectML 1.20.0) |
PHI3.5 | 3031 | 226.56 tokens/seconden |
| Mistral 7B | 3507 | 171.9 tokens/seconden | |
| LAMA3.1 | 3487 | 142.26 tokens/seconden | |
| LAMA2 | 3527 | 90.59 tokens/seconden | |
| Precisie 5860-toren (NVIDIA RTX 6000, ONNXRuntime-DirectML 1.20.0) |
PHI3.5 | 2245 | 180.472 tokens/seconden |
| Mistral 7B | 2725 | 146.639 tokens/seconden | |
| LAMA3.1 | 2692 | 118.806 tokens/seconden | |
| LAMA2 | 2733 | 77.326 tokens/seconden | |
| Lenovo Thinkpad (Intel UHD-graphics (iGPU), Intel OpenVINO 2024.5.0) |
PHI3.5 | 133 | 8.98 tokens/seconden |
| Mistral 7B | 108 | 5.54 tokens/seconden | |
| LAMA3.1 | 107 | 2.93 tokens/seconden | |
| LAMA2 | 100 | 8.98 tokens/seconden | |
| Lenovo Thinkstation (NVIDIA RTX A5500, ONNXRuntime-DirectML 1.20.0) |
PHI3.5 | 1551 | 99.43 tokens/seconden |
| Mistral 7B | 1556 | 64.18 tokens/seconden | |
| LAMA3.1 | 1580 | 59.55 tokens/seconden | |
| LAMA2 | 1644 | 37.38 tokens/seconden |
AI-beeldgeneratie
| Systeem | criterium | Totale score | Snelheid van beeldgeneratie (/s) |
|---|---|---|---|
| Alienware-Procyon (NVIDIA RTX 4090, NVIDIA TensorRT) |
Stabiele diffusie 1.5 (FP16) | 5995 | 1.043 s/afbeelding |
| Stabiele diffusie 1.5 (INT8) | 49692 | 0.629 s/afbeelding | |
| Stabiele Diffusie XL (FP16) | 4944 | 7.584 s/afbeelding | |
| Precisie 5860-toren (NVIDIA RTX 6000, NVIDIA TensorRT) |
Stabiele diffusie 1.5 (FP16) | 44169 | 0.708 s/afbeelding |
| Stabiele diffusie 1.5 (INT8) | 3094 | 12.120 s/afbeelding | |
| Stabiele Diffusie XL (FP16) | 4182 | 1.494 s/afbeelding | |
| Lenovo Thinkpad (NVIDIA RTX A4000, TensorRT) |
Stabiele diffusie 1.5 (FP16) | 1308 | 4.778 s/afbeelding |
| Stabiele diffusie 1.5 (INT8) | 15133 | 2.065 s/afbeelding | |
| Stabiele Diffusie XL (FP16) | 858 | 43.702 s/afbeelding | |
| Lenovo Thinkstation (NVIDIA RTX A5500, NVIDIA TensorRT) |
Stabiele diffusie 1.5 (FP16) | 2401 | 2.603 s/afbeelding |
| Stabiele diffusie 1.5 (INT8) | 25489 | 1.226 s/afbeelding | |
| Stabiele Diffusie XL (FP16) | 2000 | 18.747 s/afbeelding |
Blijf deze pagina volgen terwijl we doorgaan met het uitvoeren van deze nieuwe tests op een breed scala aan systemen die via het StorageReview-lab worden getest.
Neem contact op met StorageReview
Nieuwsbrief | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed