
![]() Hoje, no AWS Global Summit, a Alluxio anunciou a versão mais recente de sua tecnologia de orquestração de dados, Alluxio 2.0. A versão mais recente vem com inovações para engenheiros de dados e é voltada para análise multinuvem e IA.
Hoje, no AWS Global Summit, a Alluxio anunciou a versão mais recente de sua tecnologia de orquestração de dados, Alluxio 2.0. A versão mais recente vem com inovações para engenheiros de dados e é voltada para análise multinuvem e IA.
Hoje, no AWS Global Summit, a Alluxio anunciou a versão mais recente de sua tecnologia de orquestração de dados, Alluxio 2.0. A versão mais recente vem com inovações para engenheiros de dados e é voltada para análise multinuvem e IA.
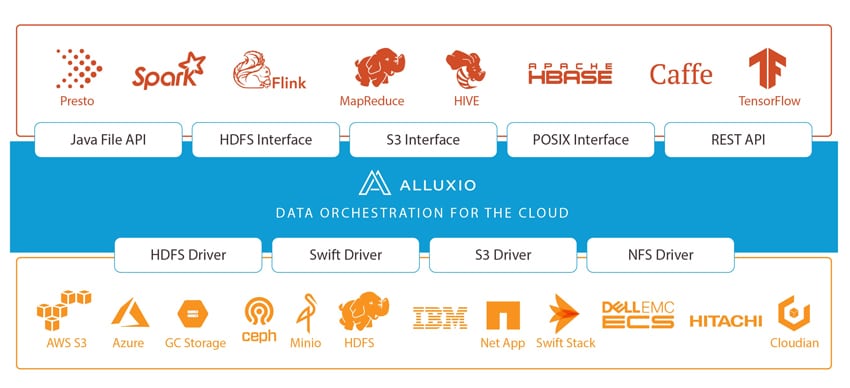
Como dissemos inicialmente, Alluxio afirma que eles são o primeiro sistema do mundo que unifica dados na velocidade da memória. A “velocidade da memória” permitiria que as empresas acessassem dados rapidamente em diferentes sistemas de armazenamento, o que, por sua vez, significa que eles podem gerenciar seus dados com mais eficiência, descobrir insights valiosos mais rapidamente e facilitar a adoção da nuvem híbrida. Atualmente, o Alluxio executa cargas de trabalho críticas para empresas como Alibaba, Baidu, Barclay's Bank, CERN, ESRI, Huawei, Intel e Juniper.
O mundo está mudando para cargas de trabalho intensivas de computação baseadas em nuvem. Esse novo foco significa que a computação precisa ser dimensionada independentemente do armazenamento de maneira elástica. Embora haja vários benefícios nisso do ponto de vista do desempenho, ele apresenta possíveis dores de cabeça para os engenheiros de dados. O Alluxio visa corrigir isso adicionando uma camada de abstração que traz localidade de dados, acessibilidade de dados e elasticidade de dados para computação em silos de dados, zonas, regiões e até nuvens.
Os recursos e capacidades incluem:
- Inovação de orquestração de dados para várias nuvens:
- Gerenciamento de dados orientado por políticas
- O Alluxio 2.0 inclui um novo recurso que permite aos engenheiros de dados automatizar a movimentação de dados em sistemas de armazenamento com base em políticas predefinidas de forma automatizada e contínua. Isso significa que, à medida que os dados são criados e os dados quentes, mornos e frios são gerenciados, o Alluxio pode automatizar a hierarquização dos dados em qualquer número de sistemas de armazenamento no local e em todas as nuvens.
- As equipes de plataforma de dados agora podem reduzir os custos de armazenamento gerenciando automaticamente apenas os dados mais importantes em sistemas de armazenamento caros e movendo outros dados para alternativas de armazenamento mais baratas.
- Administração aprimorada de políticas de acesso a dados: além de políticas refinadas no nível do arquivo, agora os usuários podem configurar políticas em qualquer nível de diretório e pasta para simplificar o acesso aos dados, bem como o desempenho das cargas de trabalho. Isso inclui a definição de comportamentos para conjuntos de dados individuais em várias funções principais, como gravação de dados ou sincronização de dados com sistemas de armazenamento no Alluxio.
- Movimentação de dados eficiente entre armazenamento em nuvem por meio do serviço de dados: o novo serviço de dados permite a movimentação de dados altamente eficiente, inclusive entre armazenamentos em nuvem como AWS S3 e Google GCS, tornando as operações caras no armazenamento de objetos integradas à estrutura de computação.
- Gerenciamento de dados orientado por políticas
- Acesso a dados otimizados para computação para análise em nuvem:
- Particionamento de cluster com foco em computação: os usuários agora podem particionar um único Alluxio com base em qualquer dimensão, de modo que os conjuntos de dados para cada estrutura ou carga de trabalho não sejam contaminados pelo outro. O uso mais comum inclui o particionamento do cluster por framework Spark, Presto etc. Além disso, isso permite reduzir os custos de transferência de dados, restringindo os dados a permanecerem em uma zona ou região específica.
- Integração com fontes de dados externas sobre REST: Os usuários agora podem trazer dados até mesmo de fontes de dados baseadas na web para agregar no Alluxio para realizar suas análises. Qualquer local da web com arquivos pode ser simplificado apontado para o Alluxio para ser puxado conforme necessário com base na consulta ou execução do modelo.
- Outros recursos, incluem:
- Serviços de Dados Altamente Distribuídos – 2.0 apresenta o Alluxio Data Service, um serviço de cluster distribuído, que opera dados como replicação, persistência, para permitir alto desempenho e escala massiva.
- Replicação adaptável para maior localidade de dados – Novo recurso para configurar um intervalo para o número de cópias de dados armazenados no Alluxio que são gerenciados automaticamente.
- Alta disponibilidade com diário incorporado – Um novo modo de tolerância a falhas e alta disponibilidade para metadados de arquivo e objeto chamado diário incorporado que usa o algoritmo de consenso RAFT e é independente de qualquer outro sistema de armazenamento externo. Isso é particularmente útil para abstrair o armazenamento de objetos.
- Alluxio POSIX API – O recurso FUSE do Alluxio permite uma API compatível com POSIX para que estruturas como Tensorflow, Caffe e outros modelos baseados em Python possam acessar dados diretamente de qualquer sistema de armazenamento via Alluxio usando o acesso tradicional ao sistema de arquivos.
- Suporte Amazon AWS:
- Integração do serviço AWS Elastic Map Reduce (EMR): à medida que os usuários migram para serviços de nuvem para implantar cargas de trabalho analíticas e de IA, serviços como o AWS EMR são cada vez mais usados. O Alluxio agora pode ser facilmente inicializado em um cluster AWS EMR, tornando-o disponível como uma camada de dados no EMR para estruturas Spark, Presto e Hive. Os usuários agora têm uma alternativa de alto desempenho para armazenar dados em cache do S3 ou dados remotos, além de reduzir as cópias de dados mantidas no EMR.
Disponibilidade
Ambos Alluxio 2.0 Community e Enterprise Edition estão agora disponíveis.
Discuta esta história
Inscreva-se no boletim informativo StorageReview