
Hoje, no NetApp Insight, a empresa anunciou que estava fazendo parceria com a empresa de virtualização de infraestrutura de IA, Run:AI, para permitir uma experimentação de IA mais rápida com a utilização total da GPU. As duas empresas acelerarão a IA executando muitos experimentos em paralelo, com acesso rápido aos dados, utilizando recursos de computação ilimitados. O objetivo é o melhor de todos os mundos: experimentos mais rápidos enquanto aproveitam todos os recursos.
Hoje, no NetApp Insight, a empresa anunciou que estava fazendo parceria com a empresa de virtualização de infraestrutura de IA, Run:AI, para permitir uma experimentação de IA mais rápida com a utilização total da GPU. As duas empresas acelerarão a IA executando muitos experimentos em paralelo, com acesso rápido aos dados, utilizando recursos de computação ilimitados. O objetivo é o melhor de todos os mundos: experimentos mais rápidos enquanto aproveitam todos os recursos.
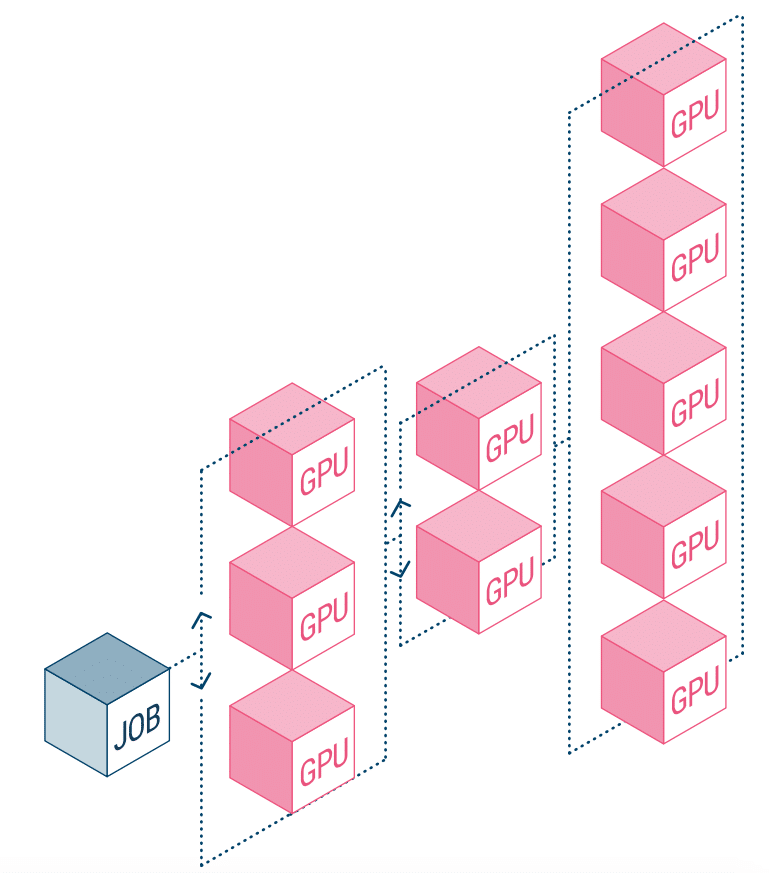
A velocidade se tornou um aspecto crítico da maioria das cargas de trabalho modernas. No entanto, a experimentação de IA está um pouco mais ligada à velocidade, pois quanto mais rápida a experimentação, mais próximos estão os resultados de negócios bem-sucedidos. Embora isso não seja segredo, os projetos de IA sofrem com processos que os tornam pouco eficientes, principalmente a combinação de tempo de processamento de dados e soluções de armazenamento desatualizadas. Outros problemas que podem limitar o número de experimentos executados são problemas de orquestração de carga de trabalho e alocação estática de recursos de computação da GPU.
A NetApp AI e a Run:AI estão se associando para resolver o problema acima. Isso significa uma simplificação da orquestração de cargas de trabalho de IA, simplificando o processo de pipelines de dados e agendamento de máquina para aprendizado profundo (DL). Com a arquitetura comprovada do NetApp ONTAP AI, a empresa afirma que os clientes podem realizar melhor AI e DL simplificando, acelerando e integrando seu pipeline de dados. No lado do Run:AI, sua orquestração de cargas de trabalho de IA adiciona uma plataforma proprietária de programação e utilização de recursos baseada em Kubernetes para ajudar os pesquisadores a gerenciar e otimizar a utilização da GPU. A tecnologia combinada permitirá que vários experimentos sejam executados em paralelo em diferentes nós de computação, com acesso rápido a muitos conjuntos de dados em armazenamento centralizado.
A Run:AI construiu o que chama de primeira plataforma de orquestração e virtualização do mundo para infraestrutura de IA. Eles abstraem a carga de trabalho do hardware e criam pools compartilhados de recursos de GPU que podem ser provisionados dinamicamente. Executar isso nos sistemas de storage da NetApp permite que os pesquisadores se concentrem em seu trabalho sem se preocupar com gargalos.
Envolva-se com a StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | RSS feed