
Technology moves in cycles, and no cycle is more evident right now than the emphasis on AI at the edge. In particular, we’re finding a massive swing to edge inferencing. NVIDIA is a big part of this push, wanting to drive adoption of their GPUs outside the data center. Still, the fact is that enterprises need to make more decisions more quickly, so AI infrastructure needs to get closer to the data.
Technology moves in cycles, and no cycle is more evident right now than the emphasis on AI at the edge. In particular, we’re finding a massive swing to edge inferencing. NVIDIA is a big part of this push, wanting to drive adoption of their GPUs outside the data center. Still, the fact is that enterprises need to make more decisions more quickly, so AI infrastructure needs to get closer to the data.

Remember Hub-and-Spoke?
In the “old days,” we talked about the edge in terms of data creation and how to get that data back to the data center quickly and efficiently by employing the traditional hub-and-spoke methodology. That design gave way to the hierarchical design, based on core, access, and distribution with lots of redundancy and hardware and the sole purpose of getting data back to the primary data center. All that data collected at the edge just to be transported back to the main data center for processing and then pushed back to the edge devices proved inefficient, costly, and time-consuming.
So maybe that hub-and-spoke design wasn’t so bad after all. With the push to deliver more intelligence at the edge with AI and the disruption of cloud computing, it appears that design is significantly impacting network design, edge deployments, and where data is being processed. In fact, this year’s HPE Discover conference had a tagline that would have been very familiar in any year prior to the cloud craze if you just swapped core for cloud, “The Edge-to-Cloud Conference.”
Jumping on the Edge Momentum
HPE wasn’t the only vendor to realize the importance of edge-to-cloud computing for the industry, with Dell Technologies delivering a similar story during the Dell Technologies World event. IBM, Lenovo, NetApp, and Supermicro have also been vocal on the need to do more at the edge while utilizing cloud resources more effectively.
What is driving the laser focus of edge computing? Customers are generating volumes of data at the edge collected from sensors, IoT devices, and Autonomous Vehicle data collections. Proximity to data at the source will deliver business benefits, including faster insights with accurate predictions and faster response times with better bandwidth utilization. AI inferencing at the edge (actionable intelligence using AI techniques) improves performance, reduces time (inference time), and reduces the dependency on network connectivity, ultimately improving the business bottom line.
Why Not Do Edge Inferencing in the Cloud?
Why can’t edge inferencing be done in the cloud? It can, and for applications that are not time-sensitive and deemed non-critical, then cloud AI inferencing might be the solution. Real-time inferencing, though, has a lot of technical challenges, latency being primary among them. Further, with the continued growth of IoT devices and associated applications requiring processing at the edge, it may not be feasible to have a high-speed cloud connection available to all devices.
Edge computing brings its own challenges that include on-site support, physical and application security, and limited space leading to limited storage. Today’s edge servers deliver adequate computational power for traditional edge workloads, with GPUs adding more power without more complexity.
Growth of Edge Options
Interestingly, the smaller systems providers have primarily dominated the edge infrastructure market. Supermicro, for instance, has been talking 5G and data centers on telephone poles for years, and Advantech and many other specialty server providers have been doing the same. But as the GPUs have improved and, more importantly, the software to support them, the entire notion of AI at the edge is becoming more real.

We’ve recently seen this transition in our lab in a few different ways. First, new server designs bring NVIDIA’s single slot, low-power GPUs like the A2 and the ever-popular T4. Recently both Lenovo and Supermicro have sent us servers to evaluate that have integrated these GPUs, and the performance has been impressive.
 SuperMicro IoT SuperServer SYS-210SE-31A with NVIDIA T4
SuperMicro IoT SuperServer SYS-210SE-31A with NVIDIA T4
Secondly, there’s a significant emphasis by infrastructure providers to deliver edge solutions with metrics tied directly to data center staples like low latency and security. We recently looked at some of these use cases with the Dell PowerVault ME5. Although pitched as an SMB storage solution, the ME5 generates a lot of interest for edge use cases due to its cost/performance ratio.
Ultimately though, the edge inferencing story is pretty simple. It comes down to the GPU’s ability to process data, often on the fly. We’ve been working on expanding our testing to get a better idea of how these new servers and GPUs can work for the edge inferencing role. Specifically, we’ve looked at popular edge workloads like image recognition and natural language processing models.

Testing Background
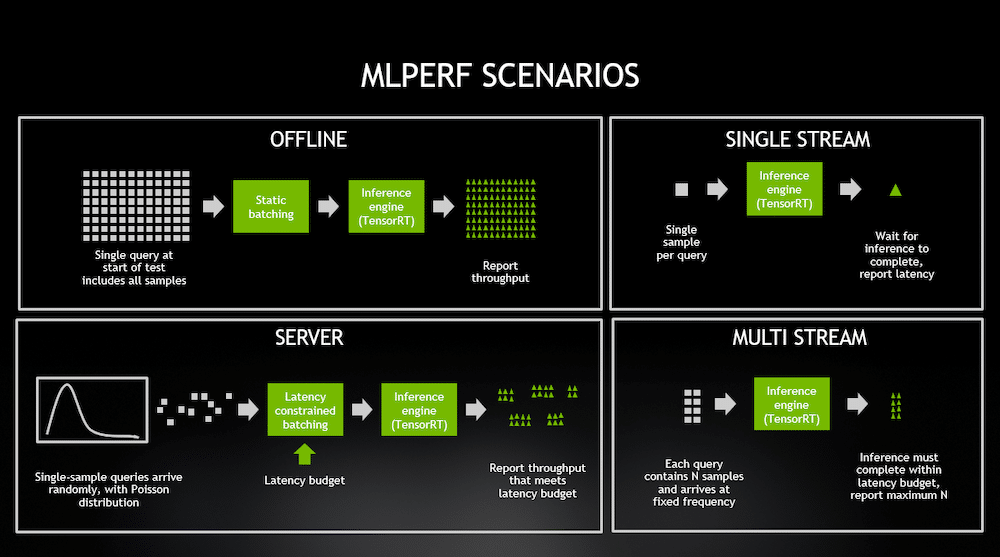
We are working with the MLPerf Inference: Edge benchmark suite. This set of tools compares inference performance for popular DL models in various real-world edge scenarios. In our testing, we have numbers for the ResNet50 image classification model and the BERT-Large NLP model for Question-Answering tasks. Both are run in Offline and SingleStream configurations.
The Offline scenario evaluates inference performance in a “batch mode,” when all the testing data is immediately available, and latency is not a consideration. In this task, the inference script can process testing data in any order, and the goal is to maximize the number of queries per second (QPS=throughput). The higher the QPS number, the better.
The Single Stream config, in contrast, processes one testing sample at a time. Once inference is performed on a single input (in the ResNet50 case, the input is a single image), the latency is measured, and the next sample is made available to the inference tool. The goal is to minimize latency for processing each query; the lower the latency, the better. The query stream’s 90th percentile latency is captured as the target metric for brevity.
The image below is from an NVIDIA blog post about MLPerf inference 0.5, which visualizes the scenarios very well. You can read more about the various scenarios in the original MLPerf Inference paper here.
Edge Inferencing – Lenovo ThinkEdge SE450
After reviewing the ThinkEdge SE450, we worked with Lenovo to run MLPerf on the NVIDIA A2 and T4 in the system. The goal was to get an idea of what the SE450 could do with just a single GPU. It should be noted the system can support up to four of the low-power NVIDIA GPUs, and it’s logical to take these numbers and extrapolate them out to the number of desired cards.

For this testing, we worked directly with Lenovo, testing the various configurations in our lab with both the NVIDIA A2 and T4. With MLPerf, vendors have a specific test harness that’s been tuned for their particular platform. We used Lenovo’s test harness for this edge inferencing benchmarking to get an idea of where these popular GPUs come out.
The results from the tests for the A2 and T4 in the SE450 in our lab:
| Benchmark | NVIDIA A2 (40-60W TDP) | NVIDIA T4 (70W TDP) |
|---|---|---|
| ResNet50 SingleStream | 0.714ms latency | 0.867 latency |
| ResNet50 Offline | 3,032.18 samples/s | 5,576.01 samples/s |
| BERT SingleStream | 8.986ms latency | 8.527ms latency |
| BERT Offline | 244.213 samples/s | 392.285 samples/s |
Interestingly, the NVIDIA T4 did really well throughout, which is surprising to some based solely on its age. The T4’s performance profile is a pretty apparent reason why the T4 is still wildly popular. That said, the A2 has a meaningful latency advantage over the T4 in real-time image inferencing.
Ultimately the decision on GPU is tuned for the specific task at hand. The older NVIDIA T4 consumes more power (70W) and uses a PCIe Gen3 x16 slot while the newer A2 is designed to operate on less power (40-60W) and uses a PCIe Gen4 x8 slot. As organizations better grasp what they’re asking from their infrastructure at the edge, the results will be more meaningful, and edge inferencing projects will be more likely to succeed.
Final Thoughts
Vendors are racing to develop smaller, faster, more rugged servers for the edge market. Organizations from retail to factories to healthcare are clamoring to gain quicker insights into the data collected at the source. Improving inference time, reducing latency, with options to improve performance, and utilizing emerging technology will quickly separate the winners and losers.

The edge market is not standing still as organizations find new ways to utilize the insights gathered from the ever-expanding number of IoT devices. Our team sees a major opportunity for those that can move quickly in their respective industries to take advantage of AI at the edge, which includes this edge inferencing use case.
We expect the prominent IT infrastructure players to respond with innovative solutions for this specific use case over the next year. Also, and maybe more importantly, we expect to see many advancements in software to help democratize the use of GPUs in these edge use cases. For this technology to be transformative, it must be easier to deploy than it is today. Given the work we’re seeing not just from NVIDIA but from software companies like Vantiq, Viso.ai, and many others, we are optimistic that more organizations can bring this technology to life.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | RSS Feed