

For years, automated storage tiering has been an essential solution for enterprises looking to manage their data center footprint efficiently while reducing the total cost of ownership (TCO). The strategy is simple: use auto-tiering algorithms and policies, and keep active data on primary storage while moving inactive data to inexpensive storage categories. In recent years, Cloud Tiering has emerged as a robust, cost-effective solution that manages the movement of inactive data to low-cost object storage in the cloud. With the ThinkSystem DM series, Lenovo enables enterprises to manage data and cloud alternatives with an intelligent storage solution. This cloud strategy successfully addresses capacity, agility, and security in hybrid-cloud environments, without compromising manageability, security, or performance.

This article discusses how Lenovo ThinkSystem Storage Solutions and the DM Series offers an end-to-end data center strategy, from the on-prem to the cloud. Firstly, we’ll touch on some fundamental concepts about data storage, cloud tiering, and new storage management challenges. We’ll look at Lenovo’s data management ecosystem, and how the company stands out in the storage market with the DM series. Also, we’ll take a close look at the ONTAP software and the FabricPool storage tiering policies. And finally, from our lab, we’ll show Lenovo’s cloud tiering solution’s setup and validation.
In a traditional data center model, as a business grows, it starts collecting critical data and files on its premises. However, this data eventually becomes old and is rarely accessed, appropriating valuable performance and capacity from the primary and secondary storage, impacting critical workloads. Archiving this data in the past was a practical solution for enterprises; however, by doing this, the data isn’t immediately available in the event it is suddenly required.
This issue has created awareness among IT organizations to consider storage tiers with different capacity, cost, and performance characteristics. They also need to acknowledge and be prepared to meet data growth requirements across multiple and cloud environments. Cloud Tiering is the answer, and it must be considered in modern storage architectures. Otherwise, an expanding data footprint will overwhelm the investment the business made in high-performance primary storage in its data center.
The Cloud as a Storage Tier
As more advanced technologies become accessible, existing storage tiers can be transformed as required, and additional ones can be added to diversify the tiered storage architecture further. The cloud has opened new possibilities to IT organizations, enabling storage solutions from public cloud providers as an additional (lower) tier. If designed and conducted well, the cloud will be an excellent and less expensive solution than a lower on-prem tier.
In primary storage tiers that use flash for extremely high performance, about 50% of cold data could be allocated to the cloud. Snapshot copies and unstructured data often comprise this category, including mission-critical apps. In secondary tiers, cold data sitting in the storage could be up to 90% from backup copies. All this valuable, but only occasionally accessed, data could be moved to the cloud as well. Popular cloud providers and services ready to tier inactive data include Azure Blob storage, AWS S3, and Google Cloud Storage.
Like on-prem automated storage tiering, we can create policies and rules to administer the data for the cloud. The conditions allow us to transfer files directly from on-premises to the public cloud. Policies are applied in several ways. For instance, data can be moved based on the file’s extension, from patterns included in the file’s name, or by how often the file is accessed within a particular period. This last option is probably the best-case scenario, where storage files and blocks are given temperature values, tagging newly written data as hot, and inactive ones as cold. Implementing a set of storage-tiering policies, cold data quickly can be moved to the cloud by running rules on-demand or by schedule.
New Storage Management Challenges
The main challenges observed in the market today surrounding hybrid-cloud data management consist of volume and variety, data velocity, and data integrity.
Data volumes are growing at a nearly exponential rate. IT organizations have to get a handle on not just data growth, but data growth and management across multiple environments. The volume and variety of data generated continue to be overwhelming. Without the capabilities to store, categorize, and process this data in a hybrid-cloud solution, organizations miss out on critical insights about their customers and business. Moreover, it is predicted that data volumes are to expand 10x by 2025 (about 163ZB), driven by IoT and edge technology. If data is the most valued asset, it must be treated with care and must be able to provide insights to focused decisions, while allowing for a look into the future. Moreover, finding more efficient ways to process this data to turn it into a value is vital for customers’ purchasing decisions.
IT threats are also evolving–and keeping the infrastructure secure is an ongoing battle. A good security strategy is to build a solid foundation based upon knowing exactly when, where, and how data is stored. This kind of strategy helps companies avoid the rising costs associated with data breaches, as well as new malware, disasters, and regulations that pose significant risks to operations. Data security is of absolute importance to enterprises, whether it be protecting from data loss or ensuring data integrity. Here’s where Lenovo covers all the options and assures their customers’ data will always be protected.
Lenovo ThinkSystem Storage Solutions
Anticipating new developments is also challenging, as is keeping abreast of the best storage and cloud strategy. However, the industry has already made a tremendous investment in research ecosystems and platforms that deliver value and opportunities for the enterprise. Taking the next strategic step for the storage industry, Lenovo has tailored its solution to meet the main challenges observed in data management. This smart move from Lenovo aims to provide the ultimate solution to its customers and offers a unique blend of products and services to enable businesses to best utilize the hybrid cloud.
Lenovo is one of the unique technology companies in the market that provides an end-to-end data center solution through the Lenovo Data Center Group (DCG). Even further, Lenovo provides end-to-end security and software management with its Intelligent Device Group (IDG) ecosystem. With these offerings and Lenovo’s ThinkSystem DM series, enterprises can improve their infrastructure and handle any workload running in their environments.
The ThinkSystem DM Series is Lenovo’s Flagship Storage solution that offers a versatile data management suite for structured and unstructured data. It spans from the entry space to a high midrange and can provide data-rich capabilities such as onboard data reduction, data protection, and data security. Each of the DM Series can deliver integrated hybrid cloud capability for public cloud provider solutions. Simultaneously, Lenovo is building out their end-to-end NVMe offerings with their recently released DM7100F series, and later this year plans to expand the offering of end-to-end NVMe to more entry-level workloads for customers to create an infrastructure-wide enterprise NVMe fabric.
FabricPools
The DM Series Data Management Suite unifies data management across flash, disk, and cloud to simplify storage environments. This comprehensive software is simple to use and highly flexible, architected for efficient storage, and has robust data management features as well as seamless cloud integration. Overall, the DM Series aims to simplify the deployment and management of data and boost enterprise applications; i.e., it is future-ready for data infrastructures.
Alongside the onboard Data Management capability is FabricPool Cloud Tiering technology. It enables automated tiering of data to low-cost S3 object storage tiers, located either on-premises or in the public cloud. Unlike manual-tiering solutions, FabricPool automates the tiering of data to lower the cost of storage. Active data remains on high-performance drives, and inactive data is tiered to object storage while preserving DM Series functionality and data efficiencies.
FabricPool supports a wide range of public cloud providers and their storage services. These include Amazon S3, Alibaba Cloud Object Storage Service, Microsoft Azure Blob Storage, Google Cloud Storage, IBM Cloud Object Storage, and private clouds. Customers will also benefit from retaining the onboard data reduction features when moving data to and from the cloud. This saves on transportation costs when data needs to be moved back from the cloud. Additionally, onboard data encryption protects both data while moving to the cloud and continues once in the cloud. This ensures there are no vulnerabilities throughout the cloud tiering process.
FabricPool Policies
FabricPool has two primary use cases: reclaim capacity on primary storage or shrink the secondary storage footprint. Our focus in this article is on the option to reclaim capacity on the primary storage. There are three different and unique policies for primary storage cloud tiering: auto-tiering, snapshots-only, and all-tiering.
Maintaining infrequently accessed data associated with productivity software, completed projects, and old datasets on primary storage is an inefficient use of high-performance flash storage. Tiering this data to an object store is an easy way to reclaim existing flash capacity and reduce the amount of required capacity moving forward. The Auto Tiering Policy moves all cold blocks in the volume to the cloud tier. If read by random reads, cold data blocks on the cloud tier become hot and are transferred to the local tier. If read by sequential reads such as those associated with index and antivirus scans, cold data blocks on the cloud tier stay cold and are not written to the local tier.
Snapshot copies can frequently consume more than 10% of a typical storage environment. Although essential for data protection and disaster recovery, these point-in-time copies are rarely used and are an inefficient use of high-performance flash. The Snapshot-Only Tiering Policy for FabricPool is an easy way to reclaim storage space on flash storage. During our testing, Snapshot-Only was the policy used to test cloud tiering operations. Cold Snapshot blocks in the volume that are not shared with the active file system are moved to the cloud tier. If read, cold data blocks on the cloud tier become hot and are transferred to the local tier.
One of the most common uses of FabricPool is to move entire volumes of data to clouds. Completed projects, legacy reports, or historical records are ideal candidates to be tiered to low-cost object storage. Moving entire volumes is accomplished by setting the All Tiering Policy on a volume. This policy is primarily used with secondary data and data protection volumes. Still, it can also be used to tier all data in read/write volumes.
Data in volumes using the All Tiering Policy is immediately labeled as cold and tiered to the cloud as soon as possible. There is no waiting for a minimum number of days to pass before the data is made cold and tiered. If read, cold data blocks on the cloud tier stay cold and are not written back to the local tier.
A fourth tiering policy option is also available with Lenovo and is aptly named the ‘None’ tiering policy. With this policy, no data is tiered, allowing maintaining everything in flash. A good example of its usage are snapshots in DevOps environments, where the previous point-in-time copies are frequently used.
Lenovo Storage Cloud Tiering Configuration
To test the capabilities and some of the Lenovo storage solution features for the cloud, we set up a DM7000F model in our lab.
First, we created a storage container using Azure Blob Storage, our cloud solution for this test. Again, it is good to note the wide range of options available from Lenovo which include Alibaba Cloud, Amazon S3, Google Cloud, IBM Cloud, and others. During the test, the purpose was to use Microsoft Azure Blob Storage for the cloud as the cloud tier for FabricPool. Once we finished the cloud storage setup, it was time to log into the DM7000’s GUI interface.
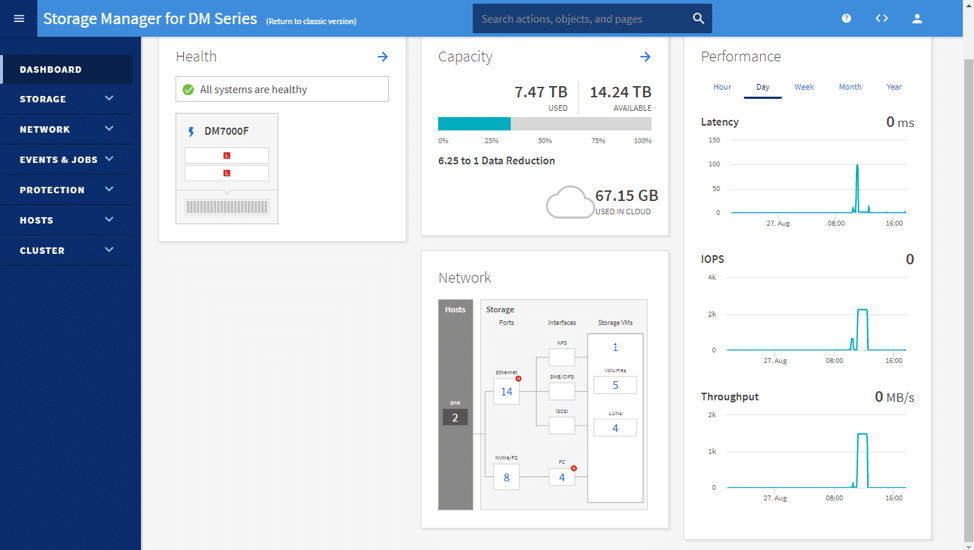
Once logged in, the default Dashboard page appears. The Dashboard shows the health, capacity, performance, and network information of the array in question.
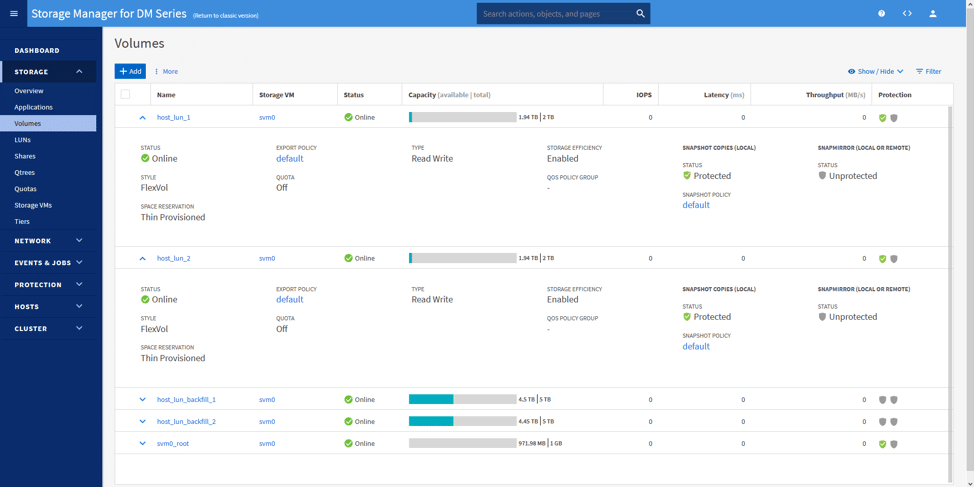
We then created two volumes (one per controller) and two VMs (one for each volume). The plan was to let these VMs run and then let them sit idle for a while. The image below shows the volumes used: host_lun_1 and host_lun_2.
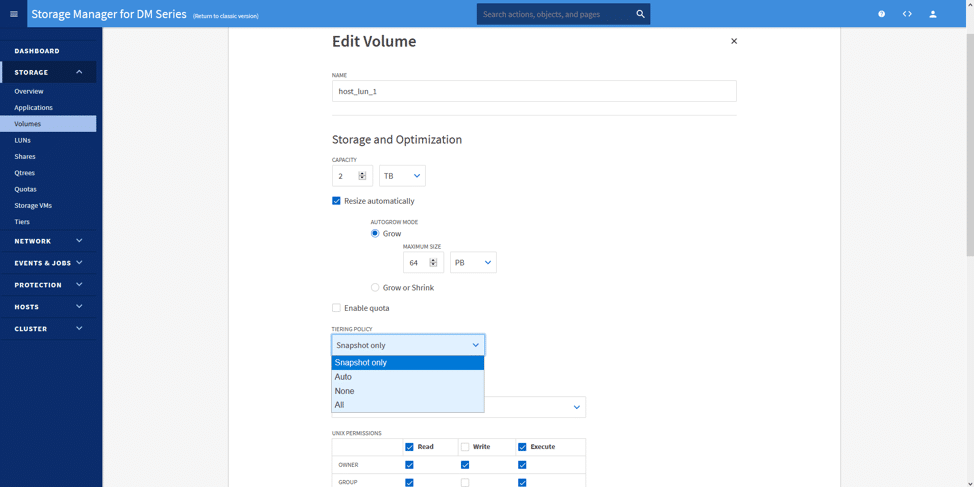
While editing or creating the volume, we can select the desired tiering policy. Here, we selected Snapshot only. Selecting this tiering policy, our data (as seen as cold after each snapshot) moves off to the Azure Blob Storage created on a background interval. The interval runs on its own time, predicting when workloads will be least impacted.
Under the Tiers page is where we can add our cloud tier from the public clouds. Here we have attached the Azure Blob Storage resource and connected it to the two local storage tiers. Under the image below, you can see two resources attached to Azure.
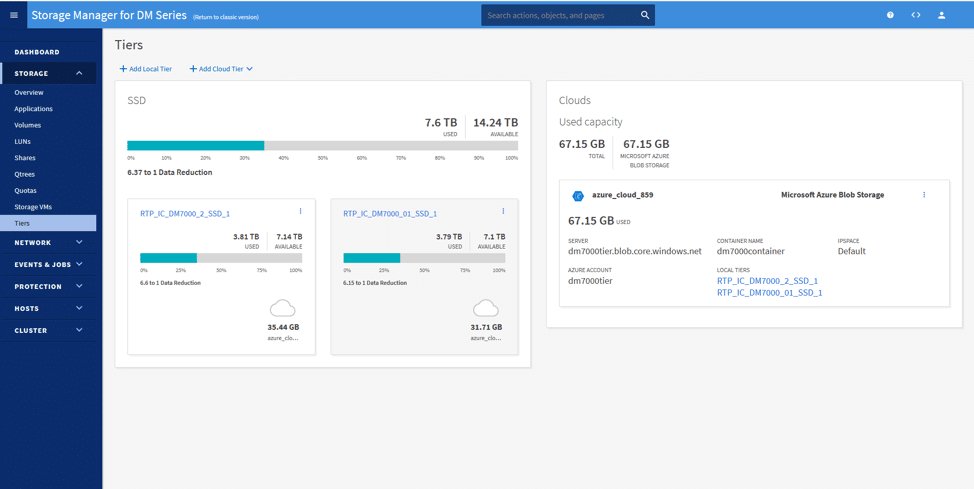
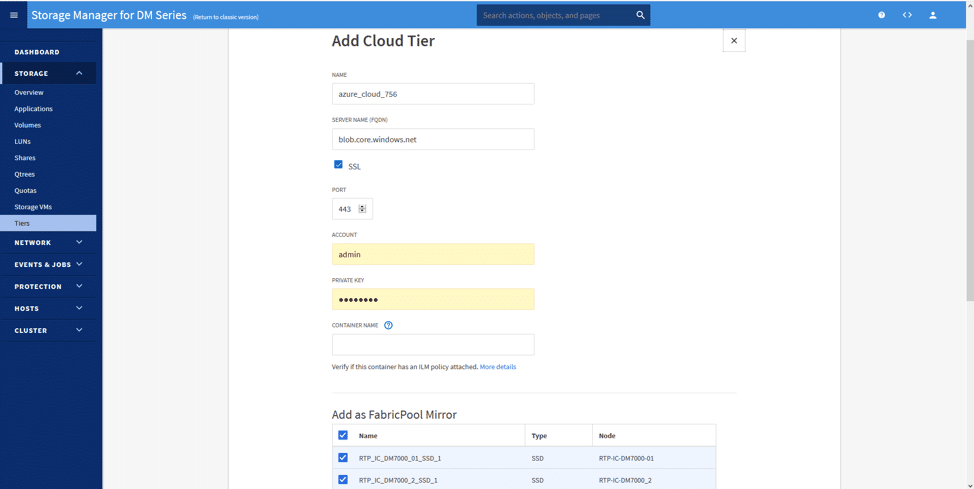
The configuration is simple; by clicking on Add Cloud Tier, and selecting our desired cloud (Azure, in this scenario), we could immediately set up the cloud tier.
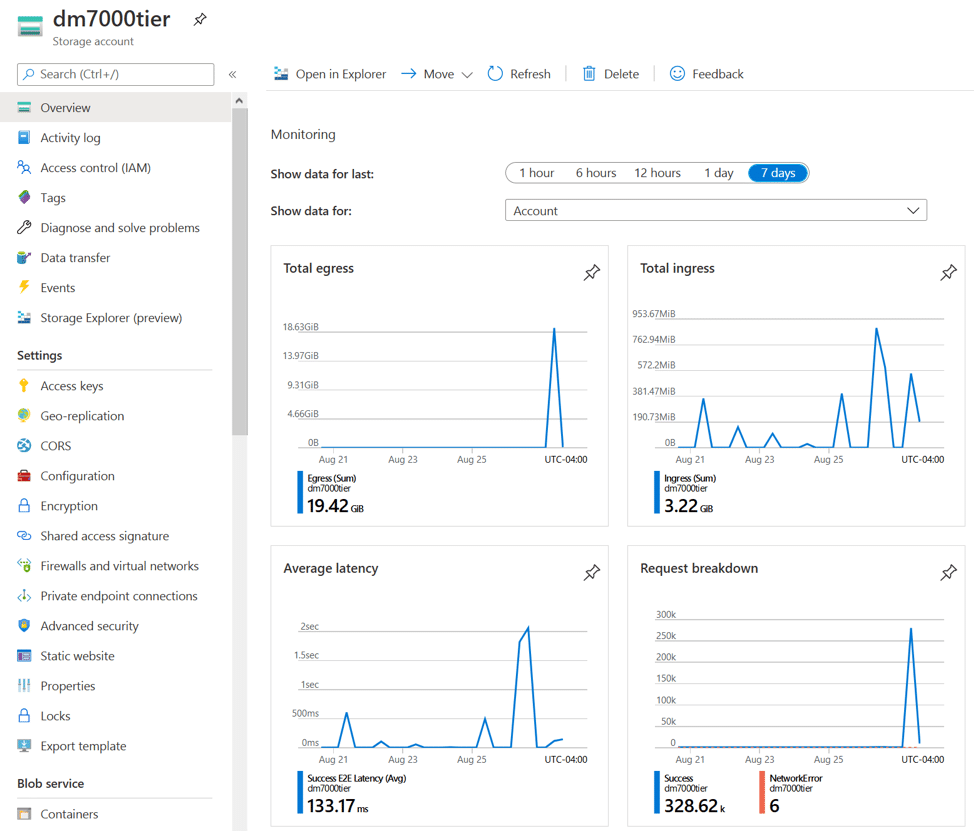
Finally, from our Azure Storage account dashboard, we wanted to show both data going into Azure (ingress) and data moving out (egress). The small peaks shown each day are new snapshots of data being transferred to Azure. On the other hand, the egress spikes show outgoing data, illustrating a snapshot restore from a volume to roll back.
Final Thoughts
In general, the cloud and the management of the data is a broad, evolving topic among enterprises. Lenovo wants to provide solutions that get customers ready for changing needs, be it in the data center or via hybrid-cloud environments. We at StorageReview are quite impressed by Lenovo’s approach to their storage arrays. Through this evaluation, we experienced how tiering data to the cloud works from the Storage Manager for DM Series, and how valuable flash capacity is reclaimed or extended into the cloud. Importantly, the DM7000F storage system delivers this flexibility without making any changes to the infrastructure. Furthermore, the functionality is easy to implement.
Supported by DCG and IDG, we see Lenovo in a strong position in the data storage market. Their storage solutions enable customers to buy what they need today while leveraging the cloud to meet the data growth requirements of the future. The net result is Lenovo cloud tiering will reduce costs and enable businesses to have the flexibility they desire when considering an investment in storage.
Lenovo ThinkSystem DM Series Storage Arrays
This report is sponsored by Lenovo. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.


 Amazon
Amazon