
Checkpointing is critical to AI model training, ensuring resilience, efficiency, and the ability to resume or fine-tune training from saved states.
Checkpointing is critical to AI model training, ensuring resilience, efficiency, and the ability to resume or fine-tune training from saved states. However, the demands of modern AI workloads, with increasingly complex models and extensive training datasets, push storage to its limit.

The Role of Checkpoints in AI Workflows
Checkpointing in AI training is a critical process that involves periodically saving the complete state of the model during training. This state includes the model weights and parameters, optimizer states, learning rate schedules, and training metadata. Checkpointing creates a comprehensive snapshot of the training process at specific intervals, providing training continuity and recovery in case of interruptions.
Checkpoints are typically taken on iteration-based intervals (e.g., every thousand training steps). Modern LLM training, which can span weeks or months and consume enormous computational resources, relies heavily on these checkpoints as a safety net against potential failures. For instance, training a model like the GPT-4 class can generate checkpoints ranging from several hundred gigabytes to multiple terabytes, depending on the model size and training configuration.
Training Process Generated by DALL-E
The primary purpose of checkpointing extends beyond mere backup functionality. It serves as a crucial mechanism for training resilience, enabling the resumption of training from the last saved state rather than starting from scratch in the event of system failures, power outages, or hardware issues. Additionally, checkpoints are invaluable for model analysis, allowing researchers to examine the model’s evolution at different training stages and potentially roll back to previous states if performance degradation is detected.
The write patterns during checkpointing are particularly interesting from a storage perspective. When a checkpoint is triggered, the system must write massive amounts of data in a burst pattern. This creates a distinctive I/O profile characterized by periods of relatively low storage activity during training computations, followed by intense, high-bandwidth write operations during checkpointing. These write operations are typically sequential and can benefit significantly from storage systems optimized for high-bandwidth sequential writes.
Different parallelism strategies in distributed training can significantly impact checkpointing behavior. These parallelism strategies affect when checkpointing occurs during training and what part of the model is being checkpointed. In modern distributed training setups, multiple GPUs can simultaneously write different parts of the same layer, creating complex I/O patterns. This parallel writing capability is key for efficiency but demands careful coordination and robust storage systems that can handle concurrent write operations while maintaining data consistency. The storage system must be capable of managing these simultaneous writes effectively, as any bottleneck in this process can cascade into overall training delays.
Slow checkpointing can create significant training bottlenecks, as the entire training process must pause while the checkpoint is being written to storage. For example, in a large-scale training setup, if checkpointing takes 30 minutes every few hours, this could result in several hours of accumulated downtime over the entire training period. This directly impacts training efficiency and increases operational costs, especially in cloud environments where computing resources are billed by time.
With faster checkpointing, teams can also afford to create checkpoints more frequently, reducing the maximum potential data loss in case of failures. This enables more aggressive training approaches and better experimental iteration cycles. Moreover, rapid checkpoint loading times facilitate quicker experimentation with different training configurations and model architectures, as researchers can more readily restore from previous states to try alternative approaches.
The storage system’s ability to efficiently handle these checkpoint operations becomes a pivotal factor in the overall training infrastructure. High-performance storage solutions that can manage both the burst write patterns of checkpointing and the sustained read/write operations of training can significantly impact the total time and cost of training large language models. Thus, the storage subsystem’s performance characteristics, particularly in handling large sequential writes and maintaining consistent high bandwidth, are crucial considerations in designing LLM training infrastructure.
For this report, we wanted to evaluate SSD performance for AI checkpointing, evaluating the benefits of the latest Gen5 SSDs when checkpoint speed is critical, compared with the largest QLC SSDs on the market, which can store vast numbers of checkpoints should that be more beneficial for the model being trained.
Checkpoint Performance – Benchmarking with DLIO
To evaluate the Solidigm SSD’s real-world performance in AI training environments, we utilized the Data and Learning Input/Output (DLIO) benchmark tool. Developed by Argonne National Laboratory, DLIO is specifically designed to test I/O patterns in deep learning workloads. It provides insights into how storage systems handle checkpointing, data ingestion, and model training challenges.

Working with DLIO, we aimed to measure the drive’s throughput, latency, and reliability under intensive checkpointing scenarios. While this testing was performed on the 61.44TB D5-P5336, initial performance data showed that the Solidigm D5-P5336 122TB version offers a similar performance profile. We also included results from a TLC-based D7-PS1010 to show the advantages of PCIe Gen5 in this test. We chose these two drives to show both angles on checkpoints, one being the fastest possible checkpoint time and the other storing the most checkpoints on a single SSD.
The platform chosen for this work was our Dell PowerEdge R760 running Ubuntu 22.04.02 LTS. We used DLIO benchmark version 2.0 from the August 13, 2024 release. Our system configuration is outlined below:
- 2 x Intel Xeon Gold 6430 (32-Core, 2.1GHz)
- 16 x 64GB DDR5-4400
- 480GB Dell BOSS SSD
- Serial Cables Gen5 JBOF
- 7.68TB Solidigm D7-PS1010
- 61.44TB Solidigm D5-P5336
To ensure our benchmarking reflected real-world scenarios, we based our testing on the LLAMA 3.1 405B model architecture, implementing checkpointing through torch.save() to capture model parameters, optimizer states, and layer states. Our setup simulated an 8-GPU system, implementing a hybrid parallelism strategy with 4-way tensor parallel and 2-way pipeline parallel processing distributed across the eight GPUs. This configuration resulted in checkpoint sizes of 1,636 GB, representative of modern large language model training requirements.

Our testing process for the DLIO checkpoint workload consisted of filling each drive to a similar utilization level. For the 61.44TB Solidigm D5-P5336, each pass included 33 checkpoint intervals, totaling 54TB. The smaller 7.68TB D7-PS1010 comfortably fit three checkpoint intervals, with a total footprint of 4.9TB. One additional checkpoint could fit into the D7-PS1010, although it brought its utilization slightly higher than we wanted.
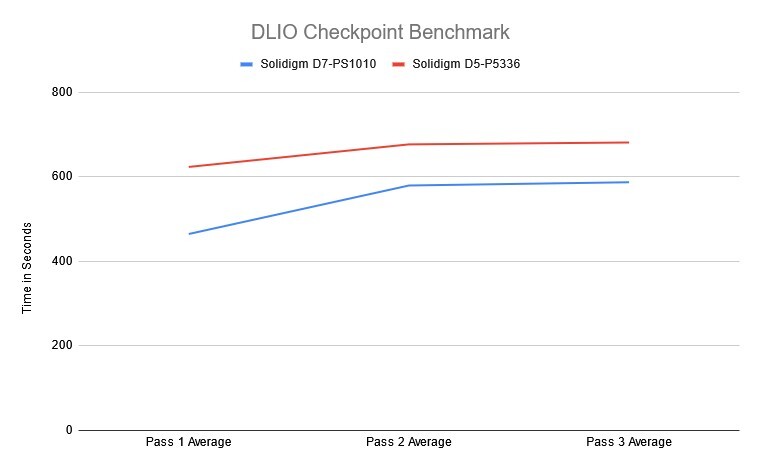
The DLIO checkpoint workload yielded interesting results when we compared the Gen4 QLC-based 61.44TB D5-P5536 to the Gen5 TLC-based 7.68TB D7-PS1010. During the first pass, as the drives filled up, we witnessed a wider gap in performance between the two SSD models. The faster Gen5 PS1010 completed each checkpoint on average in 464 seconds, compared to 623 seconds from the Gen4 P5336. In passes two and three, the gap narrowed to 579 and 587 seconds for the PS1010 and 676 and 680 seconds for the P5336.
For businesses looking to have the smallest possible gap in checkpointing intervals, the TLC-based Gen5 PS1010 offers an advantage in the fastest completion time. If the goal is to retain many checkpoints cost-effectively, the QLC-based Gen4 P5336 can do just that. We measured a difference in average checkpoint times of less than 17% between both drives during passes two and three.
GPUDirect Storage Bandwidth
While DLIO shows flash performance in an AI workflow, the workload is wholly write-based until a checkpoint is restored. To paint a fuller picture of the Solidigm D7-PS1010 and D5-P5336 in AI workloads, we included read bandwidth measurements using GDSIO.

How GPU Direct Storage Works
Traditionally, when a GPU processes data stored on an NVMe drive, the data must first travel through the CPU and system memory before reaching the GPU. This process introduces bottlenecks, as the CPU becomes a middleman, adding latency and consuming valuable system resources. GPU Direct Storage eliminates this inefficiency by enabling the GPU to access data directly from the storage device via the PCIe bus. This direct path reduces the overhead associated with data movement, allowing faster and more efficient data transfers.
AI workloads, especially those involving deep learning, are highly data-intensive. Training large neural networks requires processing terabytes of data, and any delay in data transfer can lead to underutilized GPUs and longer training times. GPU Direct Storage addresses this challenge by ensuring that data is delivered to the GPU as quickly as possible, minimizing idle time and maximizing computational efficiency.
Like the DLIO test, the goal is to better understand and characterize the differences between high-speed Gen5 SSDs and high-capacity QLC drives. Not every AI workload is the same, and each drive offers distinct advantages, depending on the need.
Testing Configuration Matrix
We systematically tested every combination of the following parameters with an NVIDIA L4 in our test platform:
- Block Sizes: 1M, 128K, 64K, 16K, 8K
- Thread Counts: 128, 64, 32, 16, 8, 4, 1
- Job Counts: 16
- Batch Sizes: 16
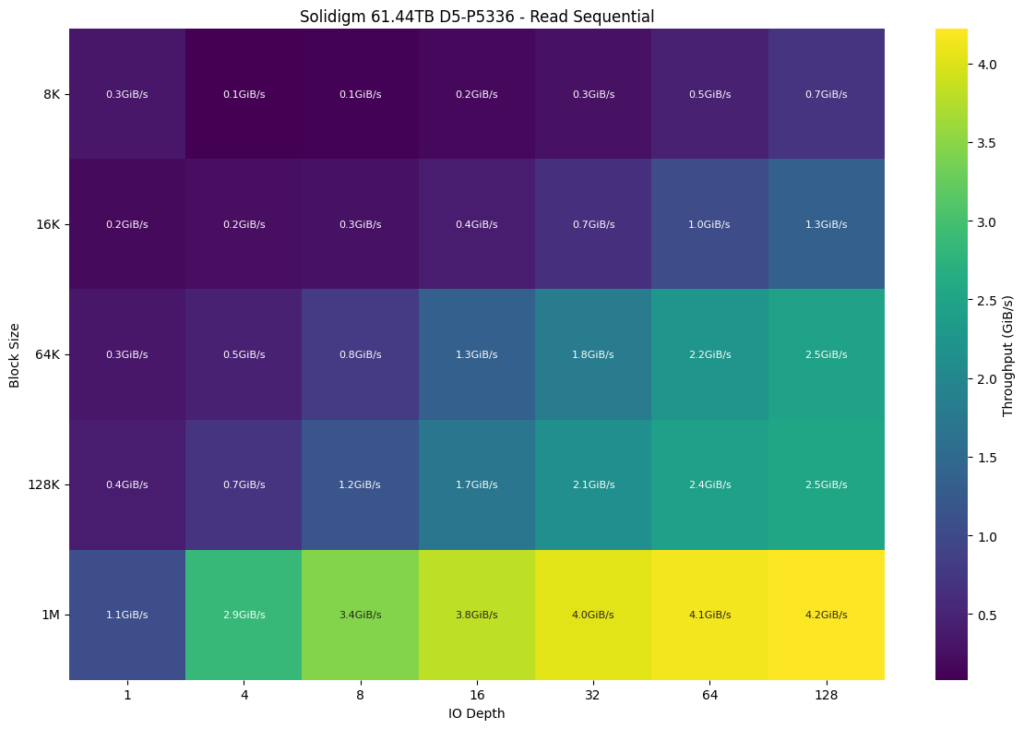
Our first look was at the QLC-based D5-P5336, which topped out at 4.2GiB/s using a 1M transfer size at an IO depth of 128. The effect of block sizes produced a substantial uplift in bandwidth, moving up from 8K to 1M. The advantage of increased IO depth started to taper off at 32, where workloads began to level off.
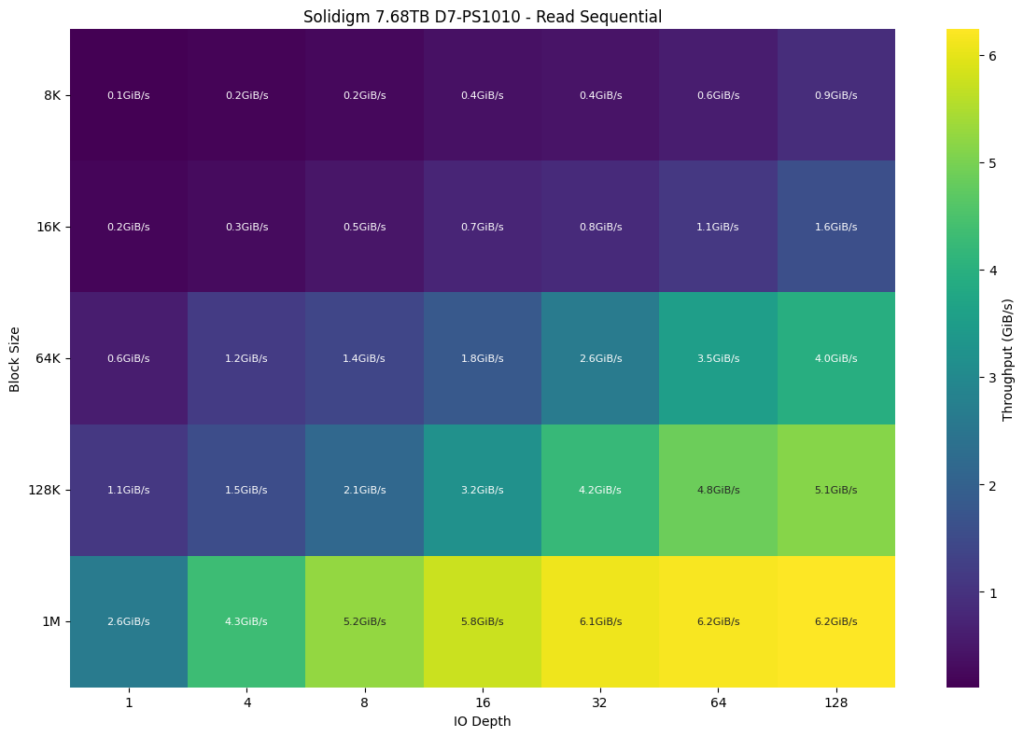
Next, we look at the Gen5 PS-1010, which can scale up to 6.2GiB/s at a 1M block size and an IO depth of 128. Across the board, it outperformed the Gen4-based P5336, with particular workloads demonstrating a substantial uplift. One notable area of improvement came in the 128K blocksize, where at an IO depth of 64 and 128, the PS1010 offered double the read bandwidth of the P5336.
It’s important to note that both SSDs were tested using the NVIDIA L4. While the Gen4 D5-P5336 is at or near its top end, upper-model NVIDIA GPUs like the H100 demonstrated a higher performance with the D7-PS1010. A drive’s speed is the ultimate deciding factor for some customers, while others prioritize overall density. Solidigm provides solutions for both, with its QLC and TLC SSD offerings.
Conclusion
As the scale and complexity of AI training continue to surge, the underlying storage infrastructure must not only keep pace but also set the tempo. Our tests with two very different SSDs illustrate the importance of aligning storage solutions with specific training priorities, such as minimizing checkpoint latency or maximizing checkpoint density for cost-effective scalability.
In our evaluation, we tested the Solidigm D5-P5336 (61.44TB) and the D7-PS1010 (7.68TB) under realistic AI training conditions using the DLIO benchmark and an extensive hybrid-parallel LLM checkpointing workflow. We captured metrics reflecting checkpoint write performance across multiple runs as the drives filled, highlighting differences in completion times between the Gen4 QLC-based D5-P5336 and the Gen5 TLC-based D7-PS1010.

While the D7-PS1010 delivered the fastest possible checkpoint writes, the D5-P5336 demonstrated compelling cost-effectiveness and capacity advantages with only a modest performance penalty. We further examined GPU Direct Storage read bandwidths with GDSIO through an NVIDIA L4 GPU. We found the Solidigm D5-P5336 offered up to 4.2GiB/s of read bandwidth with a 1M transfer size, while the D7-PS1010 offered a substantial uplift to 6.2GiB/s. You’d see an even stronger performance by leveraging an even larger GPU, such as the NVIDIA L40s or H100/H200.
Looking ahead, the unprecedented capacity of the Solidigm D5-P5336 122TB SSD stands to reshape AI training and deployment. As model sizes and checkpointing requirements continue to surge, these massive drives open doors to new levels of efficiency and flexibility, enabling training strategies that were previously out of reach. Solidigm’s leadership in high-capacity SSD solutions empowers organizations to store more data and checkpoints on fewer drives and helps future-proof their infrastructures against the next wave of AI complexity.
This report is sponsored by Solidigm. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed