
![]() Idag vid AWS Global Summit tillkännagav Alluxio den senaste versionen av sin dataorkestreringsteknologi, Alluxio 2.0. Den senaste versionen kommer med nya innovationer för dataingenjörer och är inriktad på multimolnanalys och AI.
Idag vid AWS Global Summit tillkännagav Alluxio den senaste versionen av sin dataorkestreringsteknologi, Alluxio 2.0. Den senaste versionen kommer med nya innovationer för dataingenjörer och är inriktad på multimolnanalys och AI.
Idag vid AWS Global Summit tillkännagav Alluxio den senaste versionen av sin dataorkestreringsteknologi, Alluxio 2.0. Den senaste versionen kommer med nya innovationer för dataingenjörer och är inriktad på multimolnanalys och AI.
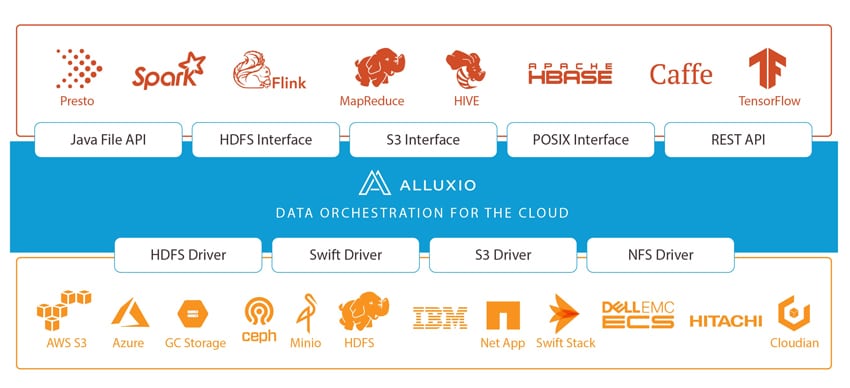
Som vi inledningsvis sa, uppger Alluxio att de är världens första system som förenar data med minneshastighet. "Minneshastigheten" skulle göra det möjligt för företag att snabbt få tillgång till data över olika lagringssystem, vilket i sin tur innebär att de kan hantera sin data mer effektivt, upptäcka värdefulla insikter snabbare och underlätta deras användning av hybridmolnet. För närvarande kör Alluxio kritiska arbetsbelastningar för företag som Alibaba, Baidu, Barclay's Bank, CERN, ESRI, Huawei, Intel och Juniper.
Världen går över till molnbaserade datorintensiva arbetsbelastningar. Detta nya fokus innebär att beräkningar måste skalas oberoende av lagring på ett elastiskt sätt. Även om det finns flera fördelar med detta ur en prestandavinkel, introducerar det potentiell huvudvärk för dataingenjörer. Alluxio strävar efter att åtgärda detta genom att lägga till ett abstraktionslager som ger datalokalitet, datatillgänglighet och datalelasticitet för att beräkna över datasilos, zoner, regioner och till och med moln.
Funktioner och funktioner inkluderar:
- Data Orchestration Innovation för multi-moln:
- Policydriven datahantering
- Alluxio 2.0 inkluderar en ny funktion som gör det möjligt för dataingenjörer att automatisera datarörelser över lagringssystem baserat på fördefinierade policyer på en automatiserad och kontinuerlig basis. Detta innebär att när data skapas och heta, varma, kalla data hanteras, kan Alluxio automatisera nivåindelning av data över valfritt antal lagringssystem över lokala och över alla moln.
- Dataplattformsteam kan nu minska lagringskostnaderna genom att automatiskt hantera endast den viktigaste datan i dyra lagringssystem och flytta annan data till billigare lagringsalternativ.
- Förbättrad administration av dataåtkomstpolicyer: Förutom finkorniga policyer på filnivå kan användare nu konfigurera policyer på vilken katalog- och mappnivå som helst för att effektivisera åtkomsten av data såväl som prestanda för arbetsbelastningar. Dessa inkluderar att definiera beteenden för individuella datauppsättningar på olika kärnfunktioner som att skriva data eller synkronisera data med lagringssystem under Alluxio.
- Cross Cloud Storage Effektiv dataförflyttning via datatjänst: Den nya datatjänsten möjliggör högeffektiv dataförflyttning inklusive mellan molnbutiker som AWS S3 och Google GCS, vilket gör dyra operationer på objektlagring sömlösa till beräkningsramverket.
- Policydriven datahantering
- Beräkna optimerad dataåtkomst för molnanalys:
- Beräkningsfokuserad klusterpartitionering: Användare kan nu partitionera en enskild Alluxio baserat på vilken dimension som helst, så att datauppsättningar för varje ramverk eller arbetsbelastning inte kontamineras av den andra. Den vanligaste användningen inkluderar partitionering av klustret med ramverk Spark, Presto etc. Dessutom möjliggör detta minskade kostnader för dataöverföring, vilket begränsar data att stanna inom en specifik zon eller region.
- Integration med externa datakällor över REST: Användare kan nu ta in data även från webbaserade datakällor för att aggregera i Alluxio för att utföra sina analyser. Alla webbplatser med filer kan förenklat pekas till Alluxio för att dras in efter behov baserat på frågan eller modellkörningen.
- Andra funktioner, inkluderar:
- Highly Distributed Data Services – 2.0 introducerar Alluxio Data Service, en distribuerad klustrad tjänst, som dataoperationer som replikering, persistens, för att möjliggöra hög prestanda och massiv skala.
- Adaptiv replikering för ökad datalokalitet – Ny funktion för att konfigurera ett intervall för antalet kopior av data som lagras i Alluxio som hanteras automatiskt.
- Hög tillgänglighet med inbyggd journal – Ett nytt feltolerans- och högtillgänglighetsläge för fil- och objektmetadata som kallas den inbäddade journalen som använder RAFT-konsensusalgoritmen och är oberoende av alla andra externa lagringssystem. Detta är särskilt användbart för att abstrahera objektlagring.
- Alluxio POSIX API – Alluxios FUSE-funktion möjliggör ett POSIX-kompatibelt API så att ramverk som Tensorflow, Caffe och andra Python-baserade modeller kan direkt komma åt data från vilket lagringssystem som helst via Alluxio med traditionell filsystemåtkomst.
- Amazon AWS Support:
- AWS Elastic Map Reduce (EMR) Service Integration: När användare flyttar till molntjänster för att distribuera analytiska och AI-arbetsbelastningar, används tjänster som AWS EMR alltmer. Alluxio kan nu sömlöst kopplas in i ett AWS EMR-kluster vilket gör det tillgängligt som ett datalager inom EMR för Spark-, Presto- och Hive-ramverk. Användare har nu ett högpresterande alternativ till cachedata från S3 eller fjärrdata samtidigt som de minskar antalet datakopior som underhålls i EMR.
Tillgänglighet
Både Alluxio 2.0 Community och Enterprise Edition är nu tillgängliga.
Diskutera den här historien
Anmäl dig till StorageReviews nyhetsbrev