
Idag på NetApp Insight meddelade företaget att det samarbetar med det virtualiserande AI-infrastrukturföretaget, Run:AI, för att möjliggöra snabbare AI-experimentering med full GPU-användning. De två företagen kommer att påskynda AI genom att köra många experiment parallellt, med snabb tillgång till data, med gränslösa beräkningsresurser. Målet är den bästa av alla världar: snabbare experiment samtidigt som man utnyttjar alla resurser.
Idag på NetApp Insight meddelade företaget att det samarbetar med det virtualiserande AI-infrastrukturföretaget, Run:AI, för att möjliggöra snabbare AI-experimentering med full GPU-användning. De två företagen kommer att påskynda AI genom att köra många experiment parallellt, med snabb tillgång till data, med gränslösa beräkningsresurser. Målet är den bästa av alla världar: snabbare experiment samtidigt som man utnyttjar alla resurser.
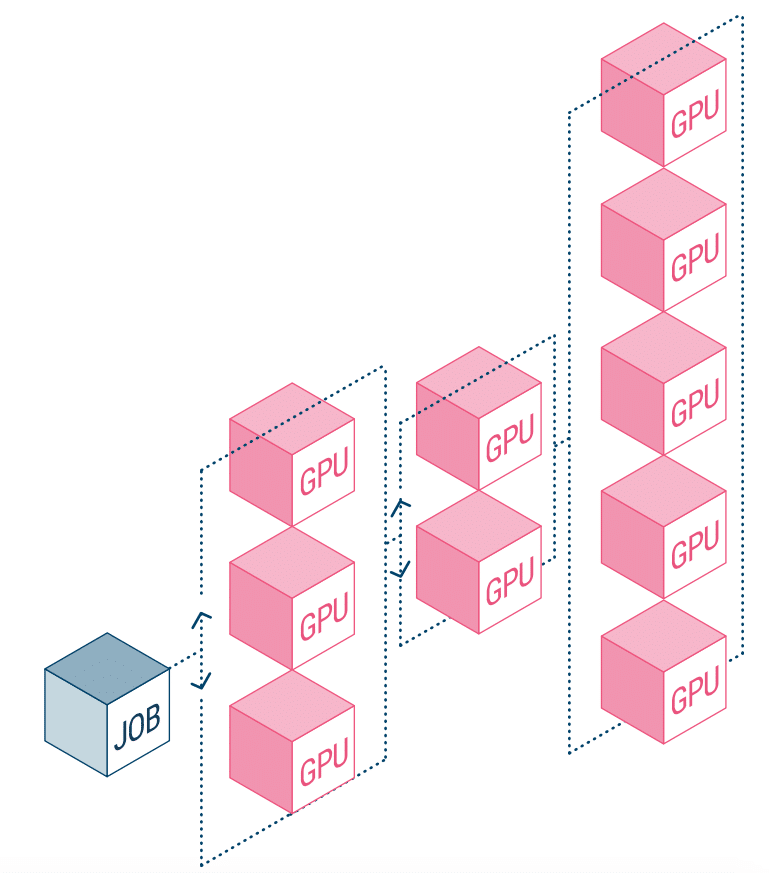
Hastighet har blivit en kritisk aspekt av de flesta moderna arbetsbelastningar. AI-experiment är dock lite närmare knutet till hastighet eftersom ju snabbare experiment, desto närmare blir de framgångsrika affärsresultaten. Även om detta inte är någon hemlighet, lider AI-projekt av processer som gör dem mindre än effektiva, främst kombinationen av databehandlingstid och föråldrade lagringslösningar. Andra problem som kan begränsa antalet körda experiment är problem med orkestrering av arbetsbelastning och statisk tilldelning av GPU-beräkningsresurser.
NetApp AI och Run:AI samarbetar för att ta itu med ovanstående. Detta innebär en förenkling av orkestreringen av AI-arbetsbelastningar, effektivisering av processen för både datapipelines och maskinschemaläggning för djupinlärning (DL). Med NetApp ONTAP AI:s beprövade arkitektur säger företaget att kunder bättre kan realisera AI och DL genom att förenkla, accelerera och integrera sin datapipeline. På Run:AI-sidan lägger dess orkestrering av AI-arbetsbelastningar till en proprietär Kubernetes-baserad plattform för schemaläggning och resursanvändning för att hjälpa forskare att hantera och optimera GPU-användning. Den kombinerade tekniken kommer att tillåta flera experiment att köras parallellt på olika beräkningsnoder, med snabb åtkomst till många datamängder på centraliserad lagring.
Run:AI byggde vad den kallar världens första orkestrerings- och virtualiseringsplattform för AI-infrastruktur. De tar bort arbetsbelastningen från hårdvaran och skapar delade pooler av GPU-resurser som kan tillhandahållas dynamiskt. Genom att köra detta på NetApps lagringssystem kan forskare fokusera på sitt arbete utan att oroa sig för flaskhalsar.
Engagera dig med StorageReview
Nyhetsbrev | Youtube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | Rssflöde