
I det blixtsnabba, ständigt föränderliga landskapet av artificiell intelligens (AI) framstår NVIDIA DGX GH200 som en ledstjärna för innovation. Detta kraftpaket i ett system, designat med de mest krävande AI-arbetsbelastningarna i åtanke, är en komplett lösning för att revolutionera hur företag närmar sig Generativ AI. NVIDIA har nya detaljer som visar hur GH200 går ihop och erbjuder en topp på hur AI-prestanda ser ut med den här senaste generationens GPU-teknik.
I det blixtsnabba, ständigt föränderliga landskapet av artificiell intelligens (AI) framstår NVIDIA DGX GH200 som en ledstjärna för innovation. Detta kraftpaket i ett system, designat med de mest krävande AI-arbetsbelastningarna i åtanke, är en komplett lösning för att revolutionera hur företag närmar sig Generativ AI. NVIDIA har nya detaljer som visar hur GH200 går ihop och erbjuder en topp på hur AI-prestanda ser ut med den här senaste generationens GPU-teknik.

NVIDIA DGX GH200: En komplett lösning
DGX GH200 är inte bara en snygg rackmaskinvara; det är en heltäckande lösning som kombinerar högpresterande datoranvändning (HPC) med AI. Den är designad för att hantera de mest komplexa AI-arbetsbelastningarna och erbjuder en prestandanivå som verkligen är oöverträffad.
DGX GH200 drar ihop en komplett hårdvarustapel, inklusive NVIDIA GH200 Grace Hopper Superchip, NVIDIA NVLink-C2C, NVIDIA NVLink Switch System och NVIDIA Quantum-2 InfiniBand, till ett system. NVIDIA stödjer allt detta med en optimerad mjukvarustack speciellt utformad för att påskynda utvecklingen av modeller.
| Specifikation | Detaljer |
|---|---|
| GPU | Hopper 96 GB HBM3, 4 TB/s |
| CPU | 72 Core Arm Neoverse V2 |
| CPU-minne | Upp till 480 GB LPDDR5 vid upp till 500 GB/s, 4 gånger mer energieffektiv än DDR5 |
| CPU-till-GPU | NVLink-C2C 900 GB/s dubbelriktad koherent länk, 5 gånger mer energieffektiv än PCIe Gen5 |
| GPU-till-GPU | NVLink 900 GB/s dubbelriktad |
| Höghastighets I/O | 4x PCIe Gen5 x16 med upp till 512 GB/s |
| TDP | Konfigurerbar från 450W till 1000W |
Utökat GPU-minne
NVIDIA Grace Hopper Superchip, utrustad med sin Extended GPU Memory (EGM)-funktion, är designad för att hantera applikationer med enorma minnesfotavtryck, större än kapaciteten hos sina egna HBM3- och LPDDR5X-minnesubsystem. Den här funktionen gör att GPU:er kan komma åt upp till 144 TB minne från alla processorer och GPU:er i systemet, med dataladdningar, lagringar och atomoperationer möjliga vid LPDDR5X-hastigheter. EGM kan användas med standard MAGNUM IO-bibliotek och kan nås av CPU och andra grafikprocessorer via NVIDIA NVLink- och NVLink-C2C-anslutningar.
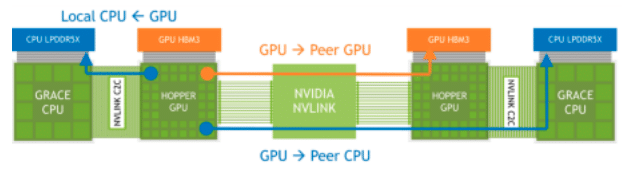
NVLink-minnesåtkomst över anslutna Grace Hopper Superchips
NVIDIA säger att funktionen Extended GPU Memory (EGM) på NVIDIA Grace Hopper Superchip avsevärt förbättrar träningen av Large Language Models (LLM) genom att tillhandahålla en enorm minneskapacitet. Detta beror på att LLM:er vanligtvis kräver enorma mängder minne för att lagra sina parametrar, beräkningar och hantera träningsdatauppsättningar.
Genom att ha tillgång till upp till 144 TB minne från alla processorer och grafikprocessorer i systemet kan modellerna tränas mer effektivt och effektivt. En stor minneskapacitet bör leda till högre prestanda, mer komplexa modeller och förmågan att arbeta med större, mer detaljerade datauppsättningar, och därigenom potentiellt förbättra noggrannheten och användbarheten av dessa modeller.
NVLink Switch System
Eftersom kraven från Large Language Models (LLM) fortsätter att tänja på gränserna för nätverkshantering, förblir NVIDIAs NVLink Switch System en robust lösning. Genom att utnyttja kraften i fjärde generationens NVLink-teknik och tredje generationens NVSwitch-arkitektur, levererar detta system hög bandbredd, låg latens-anslutning till imponerande 256 NVIDIA Grace Hopper Superchips i DGX GH200-systemet. Resultatet är häpnadsväckande 25.6 Tbps full-duplex bandbredd, vilket markerar ett stort steg i dataöverföringshastigheter.

DGX GH200 Supercomputer NVSwitch 4:e generationens NVLink Logic Översikt
I DGX GH200-systemet är varje GPU i grunden en nyfiken granne, som kan peta in i HBM3- och LPDDR5X-minnet hos sina kamrater på NVLink-nätverket. Tillsammans med NVIDIA Magnum IO-accelerationsbiblioteken optimerar detta "nosiga område" GPU-kommunikation, skalar upp effektivt och fördubblar den effektiva nätverksbandbredden. Så medan din LLM-utbildning laddas upp och kommunikationskostnaderna tar en vandring, får AI-verksamheten en turboboost.
NVIDIA NVLink Switch System i DGX GH200 kan avsevärt förbättra träningen av modeller som LLM:er genom att underlätta anslutning med hög bandbredd och låg latens mellan ett stort antal GPU:er. Detta leder till snabbare och effektivare datadelning mellan GPU:er, vilket förbättrar modellens träningshastighet och effektivitet. Dessutom ökar varje GPU:s förmåga att komma åt peer-minne från andra Superchips på NVLink-nätverket det tillgängliga minnet, vilket är avgörande för stora parameter LLM.
Medan den imponerande prestandan hos Grace Hopper Superchips obestridligen är en spelväxlare inom området för AI-beräkningar, sker den verkliga magin i detta system i NVLink, där anslutning med hög bandbredd och låg latens över flera GPU:er kräver datadelning och effektivitet till en helt ny nivå.
DGX GH200 systemarkitektur
Arkitekturen hos superdatorn DGX GH200 är komplex, men ändå noggrant designad. Består av 256 GH200 Grace Hopper-beräkningsbrickor och ett NVLink Switch System som bildar ett NVLink-fettträd på två nivåer. Varje datorbricka innehåller ett GH200 Grace Hopper Superchip, nätverkskomponenter, ett hanteringssystem/BMC och SSD:er för datalagring och körning av operativsystem.
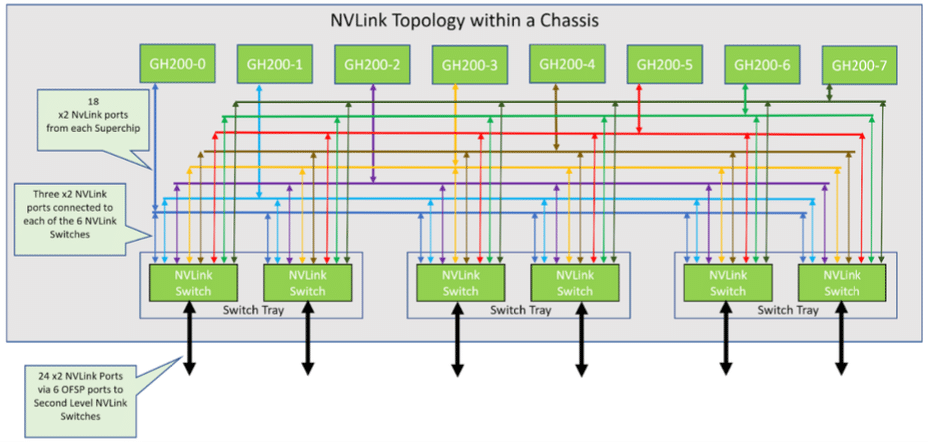
NVLink-topologi i 8-GraceHopper Superchip-chassi
| Kategori | Detaljer |
|---|---|
| CPU / GPU | 1x NVIDIA Grace Hopper Superchip med NVLink-C2C |
| GPU/GPU | 18x NVLink fjärde generationens portar |
| nätverk | 1x NVIDIA ConnectX-7 med OSFP: > NDR400 InfiniBand Compute Network 1x Dual-port NVIDIA BlueField-3 med 2x QSFP112 eller 1x Dual-port NVIDIA ConnectX-7 med 2x QSFP112: > 200 GbE In-band Ethernet-nätverk > NDR200 IB lagringsnätverk Out of Band Network: > 1 GbE RJ45 |
| lagring | Dataenhet: 2x 4 TB (U.2 NVMe SSD) SW RAID 0 OS-enhet: 2x 2 TB (M.2 NVMe SSD) SW RAID 1 |
I den här installationen är åtta beräkningsbrickor länkade till tre NVLink NVSwitch-brickor på första nivån för att skapa ett enda 8-GPU-chassi. Varje NVLink Switch-bricka har två NVSwitch ASIC:er som ansluts till beräkningsbrickorna genom en anpassad blindmate-kabelpatron och till NVLink-switcharna på andra nivån via LinkX-kablar.
Det resulterande systemet består av 36 NVLink-switchar på andra nivån som ansluter 32 chassin för att bilda den omfattande NVIDIA DGX GH200 superdatorn. För ytterligare information, se Tabell 2 för specifikationer för beräkningsfacket med Grace Hopper Superchip och Tabell 3 för NVLink Switch-specifikationer.
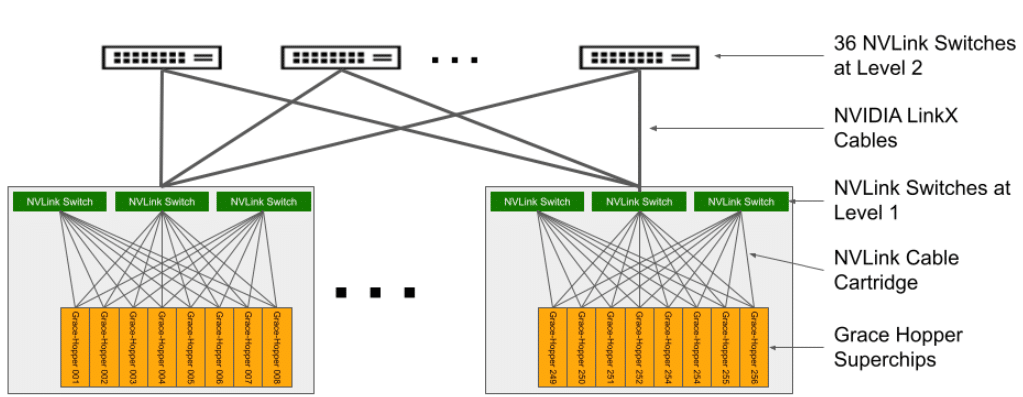
DGX GH200 NVLink Topologi
Nätverksarkitektur för DGX GH200
NVIDIA DGX GH200-systemet innehåller fyra sofistikerade nätverksarkitekturer för att tillhandahålla banbrytande beräknings- och lagringslösningar. För det första bildar ett Compute InfiniBand-tyg, konstruerat av NVIDIA ConnectX-7- och Quantum-2-switchar, ett rälsoptimerat, fullfettträd NDR400 InfiniBand-tyg, vilket möjliggör sömlös anslutning mellan flera DGX GH200-enheter.
För det andra, Storage Fabric, som drivs av NVIDIA BlueField-3 Data Processing Unit (DPU), levererar högpresterande lagring via en QSFP112-port. Detta etablerar ett dedikerat, anpassningsbart lagringsnätverk som skickligt förhindrar trafikstockningar.
In-band Management Fabric fungerar som den tredje arkitekturen, ansluter alla systemhanteringstjänster och underlättar åtkomst till lagringspooler, in-systemtjänster som Slurm och Kubernetes och externa tjänster som NVIDIA GPU Cloud.
Slutligen övervakar out-of-band Management Fabric, som arbetar på 1 GbE, viktig out-of-band-hantering för Grace Hopper-superchippen, BlueField-3 DPU och NVLink-switchar genom Baseboard Management Controller (BMC), vilket optimerar driften och förhindrar konflikter med andra tjänster.
Släpp lös kraften i AI – NVIDIA DGX GH200 Software Stack
DGX GH200 har all den råa kraftutvecklare kan önska sig; det är mycket mer än bara en fancy superdator. Det handlar om att utnyttja den kraften för att driva AI framåt. Utan tvekan är mjukvarustacken som levereras med DGX GH200 en av dess framstående funktioner.
Denna heltäckande lösning består av flera optimerade SDK:er, bibliotek och verktyg utformade för att fullt ut utnyttja hårdvarans kapacitet, vilket säkerställer effektiv applikationsskalning och förbättrad prestanda. Men bredden och djupet på DGX GH200:s mjukvarustapel förtjänar mer än att nämnas förbigående, se till att kolla in NVIDIAs vitbok på ämnet för en djupdykning i mjukvarustacken.
Förvaringskrav för DGX GH200
För att fullt ut utnyttja DGX GH200-systemets kapacitet är det avgörande att para ihop det med ett balanserat, högpresterande lagringssystem. Varje GH200-system har kapacitet att läsa eller skriva data med hastigheter på upp till 25 GB/s över NDR200-gränssnittet. För en 256 Grace Hopper DGX GH200-konfiguration föreslår NVIDIA en sammanlagd lagringsprestanda på 450 GB/s för att maximera läskapaciteten.
Behovet av att driva AI-projekt, och de underliggande GPU:erna, med lämplig lagring är sommarens populäraste mässkretsprat. Bokstavligen varje show vi har varit på har ett segment av deras keynote dedikerat till AI-arbetsflöden och lagring. Det återstår dock att se hur mycket av det här snacket som bara är ompositionering av befintliga lagringsprodukter och hur mycket av det som leder till meningsfulla förbättringar för AI-lagring. För närvarande är det för tidigt att säga, men vi hör många mullrande från lagringsleverantörer som har potential att leda till meningsfull förändring för AI-arbetsbelastningar.
Ett hinder hoppade, mer att följa
Medan DGX GH200 effektiviserar hårdvarudesignaspekten av AI-utveckling, är det viktigt att inse att inom området Generativ AI finns det andra betydande utmaningar; generering av träningsdata.
Utvecklingen av en generativ AI-modell kräver en enorm mängd data av hög kvalitet. Men data, i sin råa form, är inte direkt användbar. Det kräver omfattande insamlings-, rengörings- och märkningsinsatser för att göra den lämplig för träning av AI-modeller.
Datainsamling är det första steget och det innebär att man skaffar och ackumulerar stora mängder relevant information, vilket ofta kan vara tidskrävande och dyrt. Därefter kommer datarensningsprocessen, som kräver noggrann uppmärksamhet på detaljer för att identifiera och korrigera fel, hantera saknade poster och eliminera all irrelevant eller redundant data. Slutligen, uppgiften med datamärkning, ett viktigt steg i övervakat lärande, innebär att klassificera varje datapunkt så att AI kan förstå och lära av den.
Kvaliteten på träningsdata är avgörande. Smutsig, dålig kvalitet eller partisk data kan leda till felaktiga förutsägelser och felaktigt beslutsfattande av AI. Det finns fortfarande ett behov av mänsklig expertis och stora ansträngningar krävs för att säkerställa att data som används i utbildningen är både riklig och av högsta kvalitet.
Dessa processer är icke-triviala och kräver betydande resurser, både mänskliga och kapital, inklusive specialiserad kunskap om träningsdata, vilket understryker komplexiteten i AI-utveckling bortom hårdvaran. En del av detta åtgärdas med projekt som NeMo skyddsräcken som är designad för att hålla Generative AI exakt och säker.
Utgående Tankar
NVIDIA DGX GH200 är en komplett lösning positionerad för att omdefiniera AI-landskapet. Med sin oöverträffade prestanda och avancerade kapacitet är det en spelväxlare för att driva framtiden för AI. Oavsett om du är en AI-forskare som vill tänja på gränserna för vad som är möjligt eller ett företag som vill utnyttja kraften i AI, är DGX GH200 ett verktyg som kan hjälpa dig att nå dina mål. Det kommer att vara spännande att se hur genereringen av träningsdata hanteras när rå beräkningskraft blir mer utbredd. Denna aspekt förbises ofta i diskussioner om hårdvaruversioner.
När allt kommer omkring är det viktigt att erkänna den höga kostnaden för DGX GH200-systemet. DGX GH200 är inte billig och dess premium prislapp placerar den helt och hållet inom området för de största företagen och de mest välfinansierade AI-företagen (NVIDIA, slå mig, jag vill ha en), men för de enheter som har råd det representerar DGX GH200 en paradigmskiftande investering, en som har potential att omdefiniera gränserna för AI-utveckling och applikation.
När fler stora företag anammar denna teknik och börjar skapa och distribuera avancerade AI-lösningar, kan det leda till en bredare demokratisering av AI-teknik. Innovationer kommer förhoppningsvis att sippra ner till mer kostnadseffektiva lösningar, vilket gör AI mer tillgänglig för mindre företag. Molnbaserad åtkomst till DGX GH200-liknande beräkningskraft blir mer allmänt tillgänglig, vilket gör det möjligt för mindre företag att utnyttja dess kapacitet på en betal-per-användningsbasis. Även om initialkostnaden kan vara hög, kan det långsiktiga inflytandet från DGX GH200 sprida sig genom branschen och hjälpa till att jämna ut villkoren för företag av alla storlekar.
Engagera dig med StorageReview
Nyhetsbrev | Youtube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | Rssflöde