
Meta 透過對硬體基礎設施的策略性投資持續進行人工智慧創新,這對於推進人工智慧技術至關重要。該公司最近公佈了其 24,576 GPU 資料中心規模集群的兩次迭代的詳細信息,這對於驅動下一代人工智慧模型(包括 Llama 3 的開發)發揮了重要作用。
Meta 透過對硬體基礎設施的策略性投資持續進行人工智慧創新,這對於推進人工智慧技術至關重要。該公司最近公佈了其24,576 GPU 資料中心規模集群的兩次迭代的詳細信息,這對於驅動下一代人工智慧模型(包括Llama 3 的開發)發揮了重要作用。這一舉措是Meta 願景的基礎,即產生開放和負責任的構建所有人都可以使用通用人工智慧(AGI)。
照片由 META 工程提供
在其持續發展的過程中,Meta 完善了其人工智慧研究超級叢集 (RSC),最初於 2022 年披露,配備 16,000 個 NVIDIA A100 GPU。 RSC 在推動開放式人工智慧研究和促進複雜人工智慧模型的創建方面發揮了關鍵作用,其應用涵蓋電腦視覺、自然語言處理 (NLP)、語音識別等多個領域。
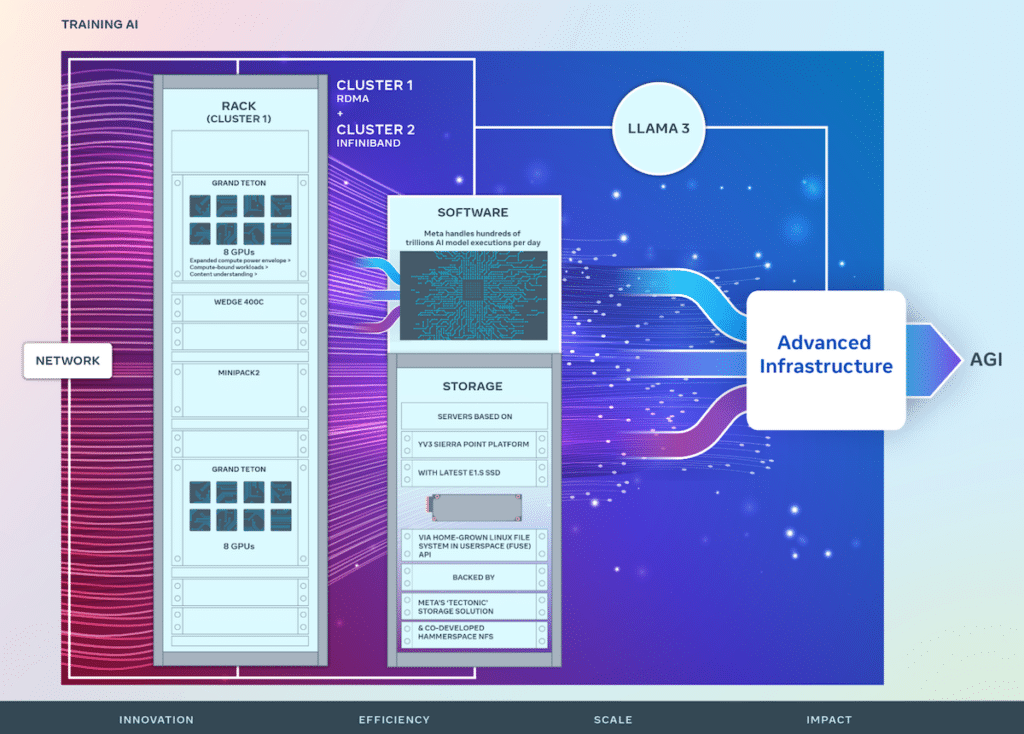
在 RSC 的成功基礎上,Meta 的新人工智慧叢集增強了端到端人工智慧系統開發,重點是優化研究人員和開發人員的體驗。這些叢集整合了 24,576 個 NVIDIA Tensor Core H100 GPU,並利用高效能網路結構來支援比以前更複雜的模型,為 GenAI 產品開發和研究設立了新標準。
Meta 的基礎設施非常先進且適應性強,每天處理數百萬億個人工智慧模型執行。硬體和網路結構的客製化設計可確保人工智慧研究人員獲得最佳化的效能,同時保持資料中心的高效運作。
創新的網路解決方案已實施,包括一個採用融合乙太網路(RoCE) 上的遠端直接記憶體存取(RDMA) 的集群,以及另一個採用NVIDIA Quantum2 InfiniBand 結構的集群,兩者都能夠實現400 Gbps 互連。這些技術實現了可擴展性和效能洞察,這對於未來大規模人工智慧叢集的設計至關重要。

大提頓在 OCP 2022 期間推出
Meta 的 Grand Teton 是一個內部設計的開放式 GPU 硬體平台,為開放運算專案 (OCP) 做出了貢獻,並體現了多年的 AI 系統開發經驗。它將電源、控制、運算和結構介面合併為一個緊密結合的單元,促進資料中心環境中的快速部署和擴展。
為了解決儲存在 AI 訓練中經常被忽視但至關重要的作用,Meta 在用戶空間 (FUSE) API 中實作了自訂 Linux 檔案系統,並由「Tectonic」分散式儲存解決方案的最佳化版本提供支援。此設定與共同開發的 Hammerspace 平行網路檔案系統 (NFS) 結合,提供了一個可擴展的高吞吐量儲存解決方案,對於處理多模式 AI 訓練作業的大量資料需求至關重要。
Meta 的 YV3 Sierra Point 伺服器平台由 Tectonic 和 Hammerspace 解決方案提供支持,凸顯了該公司對效能、效率和可擴展性的致力於。這種遠見確保儲存基礎設施能夠滿足當前的需求並進行擴展,以適應未來人工智慧計畫不斷增長的需求。
隨著人工智慧系統的複雜性不斷增加,Meta 繼續在硬體和軟體方面進行開源創新,為 OCP 和 PyTorch 做出了重大貢獻,從而促進了人工智慧研究社群內的協作進步。
這些人工智慧訓練集群的設計是Meta 路線圖不可或缺的一部分,旨在擴展其基礎設施,目標是到350,000 年底整合100 個NVIDIA H2024 GPU。這一軌跡凸顯了Meta 積極主動的基礎設施開發方法,旨在滿足人工智慧的動態需求。未來人工智慧的研究和應用。
參與 StorageReview
電子報 | YouTube | 播客 iTunes/Spotify | Instagram | Twitter | 的TikTok | RSS訂閱