
今天,在 NetApp Insight 上,該公司宣布與虛擬化 AI 基礎設施公司 Run:AI 合作,以實現更快的 AI 實驗並充分利用 GPU。 兩家公司將通過並行運行許多實驗、快速訪問數據、利用無限的計算資源來加速人工智能。 目標是世界上最好的:在利用全部資源的同時進行更快的實驗。
今天,在 NetApp Insight 上,該公司宣布與虛擬化 AI 基礎設施公司 Run:AI 合作,以實現更快的 AI 實驗並充分利用 GPU。 兩家公司將通過並行運行許多實驗、快速訪問數據、利用無限的計算資源來加速人工智能。 目標是世界上最好的:在利用全部資源的同時進行更快的實驗。
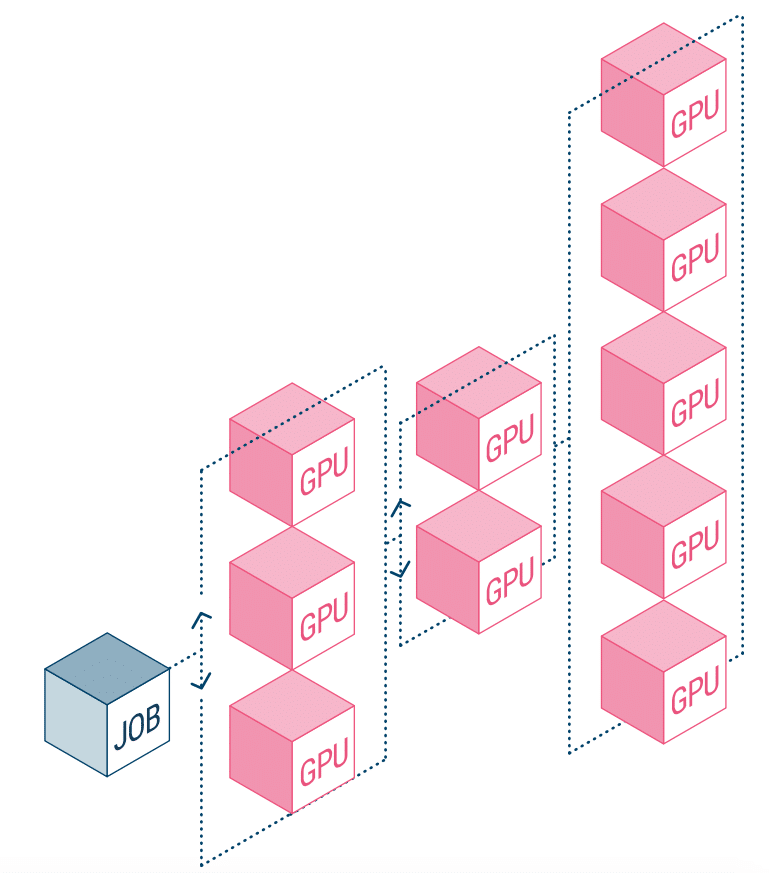
速度已成為大多數現代工作負載的一個關鍵方面。 然而,人工智能實驗與速度的關係更為密切,因為實驗越快,成功的業務成果就越緊密。 雖然這不是什麼秘密,但人工智能項目的流程使其效率低下,主要是數據處理時間和過時的存儲解決方案的結合。 其他可能限制實驗運行數量的問題是工作負載編排問題和 GPU 計算資源的靜態分配。
NetApp AI 和 Run:AI 正在合作解決上述問題。 這意味著簡化 AI 工作負載的編排,簡化數據管道和深度學習 (DL) 機器調度的過程。 借助 NetApp ONTAP AI 經驗證的架構,該公司表示,客戶可以通過簡化、加速和集成其數據管道來更好地實現 AI 和 DL。 在 Run:AI 方面,其 AI 工作負載編排增加了專有的基於 Kubernetes 的調度和資源利用平台,以幫助研究人員管理和優化 GPU 利用率。 結合的技術將允許多個實驗在不同的計算節點上並行運行,并快速訪問集中存儲上的許多數據集。
Run:AI 構建了它所謂的世界上第一個用於 AI 基礎設施的編排和虛擬化平台。 他們從硬件中抽像出工作負載,並創建可動態配置的 GPU 資源共享池。 在 NetApp 的存儲系統上運行它可以讓研究人員專注於他們的工作,而不必擔心瓶頸。
參與 StorageReview
電子報 | YouTube | 播客 iTunes/Spotify | Instagram | Twitter | Facebook | RSS訂閱