
En el panorama de la inteligencia artificial (IA) en constante evolución y a la velocidad del rayo, NVIDIA DGX GH200 emerge como un modelo de innovación. Esta central eléctrica de un sistema, diseñada teniendo en cuenta las cargas de trabajo de IA más exigentes, es un conjunto de soluciones completo para revolucionar la forma en que las empresas abordan la IA generativa. NVIDIA tiene nuevos detalles que muestran cómo se combina el GH200 y ofrece un pico de cómo se ve el rendimiento de la IA con esta tecnología de GPU de última generación.
En el panorama de la inteligencia artificial (IA) en constante evolución y a la velocidad del rayo, NVIDIA DGX GH200 emerge como un modelo de innovación. Esta central eléctrica de un sistema, diseñada teniendo en cuenta las cargas de trabajo de IA más exigentes, es un conjunto de soluciones completo para revolucionar la forma en que las empresas abordan la IA generativa. NVIDIA tiene nuevos detalles que muestran cómo se combina el GH200 y ofrece un pico de cómo se ve el rendimiento de la IA con esta tecnología de GPU de última generación.

NVIDIA DGX GH200: una solución completa
El DGX GH200 no es solo una elegante pieza de hardware de rack; es una solución integral que combina computación de alto rendimiento (HPC) con IA. Está diseñado para manejar las cargas de trabajo de IA más complejas y ofrece un nivel de rendimiento verdaderamente incomparable.
El DGX GH200 reúne una pila de hardware completa, que incluye NVIDIA GH200 Grace Hopper Superchip, NVIDIA NVLink-C2C, NVIDIA NVLink Switch System y NVIDIA Quantum-2 InfiniBand, en un solo sistema. NVIDIA respalda todo esto con una pila de software optimizada diseñada específicamente para acelerar el desarrollo de modelos.
| Especificaciones | Detalles |
|---|---|
| GPU | Tolva 96 GB HBM3, 4 TB/s |
| CPU | Brazo de 72 núcleos Neoverse V2 |
| Memoria de la CPU | Hasta 480 GB LPDDR5 a hasta 500 GB/s, 4 veces más eficiente energéticamente que DDR5 |
| CPU a GPU | Enlace coherente bidireccional NVLink-C2C de 900 GB/s, 5 veces más eficiente energéticamente que PCIe Gen5 |
| GPU a GPU | NVLink 900 GB/s bidireccional |
| E/S de alta velocidad | 4x PCIe Gen5 x16 hasta 512 GB/s |
| TDP | Configurable de 450W a 1000W |
Memoria GPU extendida
El superchip NVIDIA Grace Hopper, equipado con su función de memoria de GPU extendida (EGM), está diseñado para manejar aplicaciones con huellas de memoria masivas, más grandes que la capacidad de sus propios subsistemas de memoria HBM3 y LPDDR5X. Esta característica permite que las GPU accedan a hasta 144 TB de memoria desde todas las CPU y GPU del sistema, con cargas de datos, almacenamiento y operaciones atómicas posibles a velocidades LPDDR5X. El EGM se puede usar con las bibliotecas MAGNUM IO estándar y la CPU y otras GPU pueden acceder a él a través de las conexiones NVIDIA NVLink y NVLink-C2C.
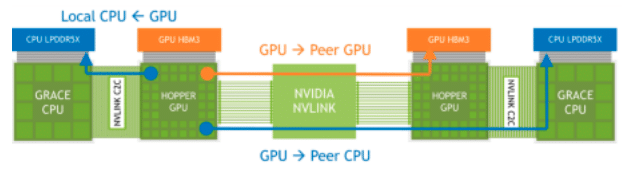
Accesos a memoria NVLink a través de superchips Grace Hopper conectados
NVIDIA dice que la función de memoria de GPU extendida (EGM) en NVIDIA Grace Hopper Superchip mejora significativamente el entrenamiento de modelos de lenguaje grande (LLM) al proporcionar una gran capacidad de memoria. Esto se debe a que los LLM generalmente requieren grandes cantidades de memoria para almacenar sus parámetros, cálculos y administrar conjuntos de datos de capacitación.
Al tener la capacidad de acceder a hasta 144 TB de memoria desde todas las CPU y GPU del sistema, los modelos se pueden entrenar de manera más eficiente y efectiva. Una gran capacidad de memoria debería conducir a un mayor rendimiento, modelos más complejos y la capacidad de trabajar con conjuntos de datos más grandes y detallados, lo que podría mejorar la precisión y la utilidad de estos modelos.
Sistema de conmutación NVLink
A medida que las demandas de los modelos de lenguaje grande (LLM) continúan superando los límites de la administración de redes, el sistema de conmutadores NVLink de NVIDIA sigue siendo una solución sólida. Aprovechando el poder de la tecnología NVLink de cuarta generación y la arquitectura NVSwitch de tercera generación, este sistema ofrece conectividad de baja latencia y gran ancho de banda a unos impresionantes 256 Superchips NVIDIA Grace Hopper dentro del sistema DGX GH200. El resultado es un asombroso ancho de banda de dúplex completo de 25.6 Tbps, lo que marca un salto sustancial en las velocidades de transferencia de datos.

DGX GH200 Supercomputadora NVSwitch 4.ª generación NVLink Logic Descripción general
En el sistema DGX GH200, cada GPU es esencialmente un vecino entrometido, capaz de hurgar en la memoria HBM3 y LPDDR5X de sus pares en la red NVLink. Junto con las bibliotecas de aceleración NVIDIA Magnum IO, este "vecindario entrometido" optimiza las comunicaciones de la GPU, escala de manera eficiente y duplica el ancho de banda efectivo de la red. Por lo tanto, mientras su capacitación LLM está sobrecargada y los gastos generales de comunicación están aumentando, las operaciones de IA están recibiendo un impulso turbo.
El sistema de conmutador NVIDIA NVLink en el DGX GH200 es capaz de mejorar significativamente el entrenamiento de modelos como LLM al facilitar la conectividad de baja latencia y gran ancho de banda entre una gran cantidad de GPU. Esto conduce a un intercambio de datos más rápido y eficiente entre las GPU, lo que mejora la velocidad y la eficiencia del entrenamiento del modelo. Además, la capacidad de cada GPU para acceder a la memoria del mismo nivel desde otros Superchips en la red NVLink aumenta la memoria disponible, lo cual es fundamental para los LLM de parámetros grandes.
Si bien el rendimiento impresionante de Grace Hopper Superchips es indiscutiblemente un cambio de juego en el ámbito de los cálculos de IA, la verdadera magia de este sistema ocurre en NVLink, donde la conectividad de baja latencia y gran ancho de banda a través de numerosas GPU requiere el intercambio de datos y la eficiencia. a un nivel completamente nuevo.
Arquitectura del sistema DGX GH200
La arquitectura de la supercomputadora DGX GH200 es compleja, pero está meticulosamente diseñada. Consta de 256 bandejas de cómputo GH200 Grace Hopper y un sistema de interruptores NVLink que forma un fat tree NVLink de dos niveles. Cada bandeja de cómputo alberga un Superchip GH200 Grace Hopper, componentes de red, un sistema de administración/BMC y SSD para el almacenamiento de datos y la ejecución del sistema operativo.
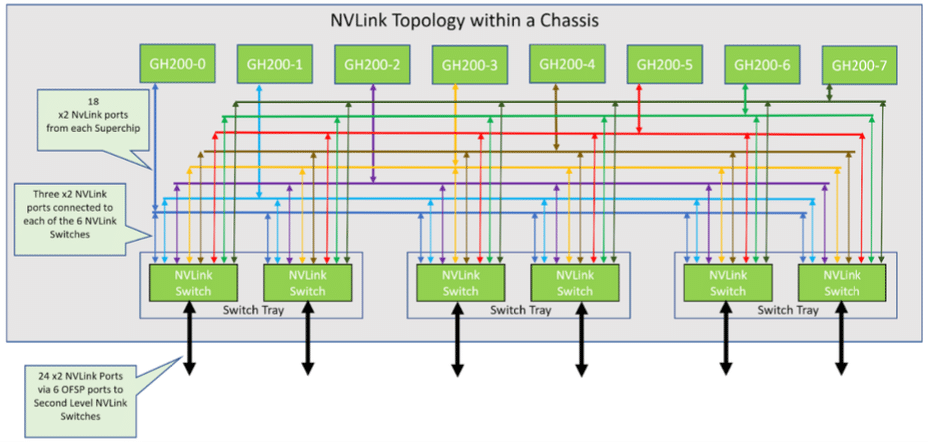
Topología NVLink en chasis 8-GraceHopper Superchip
| Categoría: | Detalles |
|---|---|
| CPU / GPU | 1 superchip NVIDIA Grace Hopper con NVLink-C2C |
| GPU/GPU | 18 puertos NVLink de cuarta generación |
| Networking | 1x NVIDIA ConnectX-7 con OSFP: > Red informática NDR400 InfiniBand 1 NVIDIA BlueField-3 de puerto dual con 2 QSFP112 o 1 NVIDIA ConnectX-7 de puerto dual con 2 QSFP112: > Red Ethernet en banda de 200 GbE > Red de almacenamiento NDR200 IB Red fuera de banda: > 1GbE RJ45 |
| Storage | Unidad de datos: 2x 4 TB (SSD U.2 NVMe) SW RAID 0 Unidad de SO: 2x 2 TB (SSD M.2 NVMe) SW RAID 1 |
En esta configuración, ocho bandejas de cómputo están vinculadas a tres bandejas NVLink NVSwitch de primer nivel para establecer un solo chasis de 8 GPU. Cada bandeja de NVLink Switch posee dos NVSwitch ASIC que se conectan a las bandejas de cómputo a través de un cartucho de cable ciego personalizado y a los NVLink Switches de segundo nivel a través de cables LinkX.
El sistema resultante consta de 36 conmutadores NVLink de segundo nivel que conectan 32 chasis para formar la completa supercomputadora NVIDIA DGX GH200. Para obtener más información, consulte la Tabla 2 para conocer las especificaciones de la bandeja de cómputo con Grace Hopper Superchip y la Tabla 3 para conocer las especificaciones del conmutador NVLink.
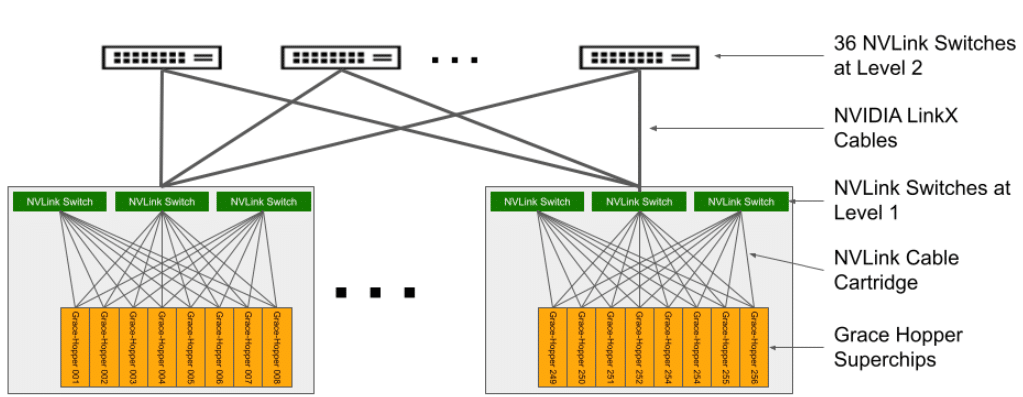
Topología DGX GH200 NVLink
Arquitectura de red del DGX GH200
El sistema NVIDIA DGX GH200 incorpora cuatro arquitecturas de red sofisticadas para proporcionar soluciones informáticas y de almacenamiento de vanguardia. En primer lugar, una Compute InfiniBand Fabric, construida a partir de los switches NVIDIA ConnectX-7 y Quantum-2, forma una estructura InfiniBand NDR400 Full-Fat Tree optimizada para rieles, lo que permite una conectividad perfecta entre varias unidades DGX GH200.
En segundo lugar, Storage Fabric, impulsado por la unidad de procesamiento de datos (DPU) NVIDIA BlueField-3, ofrece almacenamiento de alto rendimiento a través de un puerto QSFP112. Esto establece una red de almacenamiento dedicada y personalizable que evita hábilmente la congestión del tráfico.
El Management Fabric en banda sirve como la tercera arquitectura, conectando todos los servicios de administración del sistema y facilitando el acceso a grupos de almacenamiento, servicios en el sistema como Slurm y Kubernetes, y servicios externos como NVIDIA GPU Cloud.
Por último, el tejido de gestión fuera de banda, que funciona a 1 GbE, supervisa la gestión fuera de banda esencial para los superchips Grace Hopper, la DPU BlueField-3 y los conmutadores NVLink a través del controlador de gestión de placa base (BMC), optimizando las operaciones y evitando conflictos con otros servicios.
Desatando el poder de la IA: pila de software NVIDIA DGX GH200
El DGX GH200 tiene toda la potencia bruta que los desarrolladores podrían desear; es mucho más que una supercomputadora elegante. Se trata de aprovechar ese poder para impulsar la IA. Sin duda, la pila de software que viene con la DGX GH200 es una de sus características más destacadas.
Esta solución integral comprende varios SDK, bibliotecas y herramientas optimizados diseñados para aprovechar al máximo las capacidades del hardware, lo que garantiza un escalado de aplicaciones eficiente y un rendimiento mejorado. Sin embargo, la amplitud y profundidad de la pila de software de la DGX GH200 merece más que una mención pasajera, asegúrese de consultar Informe técnico de NVIDIA sobre el tema para una inmersión profunda en la pila de software.
Requisitos de almacenamiento de la DGX GH200
Para aprovechar al máximo las capacidades del sistema DGX GH200, es fundamental combinarlo con un sistema de almacenamiento equilibrado y de alto rendimiento. Cada sistema GH200 tiene la capacidad de leer o escribir datos a velocidades de hasta 25 GB/s en la interfaz NDR200. Para una configuración 256 Grace Hopper DGX GH200, NVIDIA sugiere un rendimiento de almacenamiento agregado de 450 GB/s para maximizar el rendimiento de lectura.
La necesidad de impulsar los proyectos de IA y las GPU subyacentes con el almacenamiento adecuado es el tema de conversación más popular del circuito de ferias comerciales del verano. Literalmente, todos los espectáculos en los que hemos estado tienen algún segmento de su discurso de apertura dedicado a los flujos de trabajo y el almacenamiento de IA. Queda por ver, sin embargo, cuánto de esta charla se trata simplemente de reposicionar los productos de almacenamiento existentes y cuánto conduce a mejoras significativas para el almacenamiento de IA. Por el momento, es demasiado pronto para decirlo, pero escuchamos muchos rumores de los proveedores de almacenamiento que tienen el potencial de generar cambios significativos para las cargas de trabajo de IA.
Un obstáculo saltado, más por seguir
Si bien el DGX GH200 agiliza el aspecto del diseño de hardware del desarrollo de IA, es importante reconocer que en el campo de la IA generativa existen otros desafíos considerables; la generación de datos de entrenamiento.
El desarrollo de un modelo de IA generativa requiere un volumen inmenso de datos de alta calidad. Pero los datos, en su forma cruda, no se pueden usar de inmediato. Requiere grandes esfuerzos de recolección, limpieza y etiquetado para que sea adecuado para entrenar modelos de IA.
La recopilación de datos es el paso inicial e implica obtener y acumular grandes cantidades de información relevante, lo que a menudo puede llevar mucho tiempo y ser costoso. Luego viene el proceso de limpieza de datos, que requiere una atención meticulosa a los detalles para identificar y corregir errores, manejar entradas faltantes y eliminar cualquier dato irrelevante o redundante. Finalmente, la tarea de etiquetado de datos, una etapa esencial en el aprendizaje supervisado, implica clasificar cada punto de datos para que la IA pueda comprenderlos y aprender de ellos.
La calidad de los datos de entrenamiento es primordial. Los datos sucios, de mala calidad o sesgados pueden conducir a predicciones inexactas y a una toma de decisiones defectuosa por parte de la IA. Todavía se necesita experiencia humana y se necesita un gran esfuerzo para garantizar que los datos utilizados en la capacitación sean abundantes y de la más alta calidad.
Estos procesos no son triviales y requieren recursos significativos, tanto humanos como de capital, incluido el conocimiento especializado de los datos de entrenamiento, lo que subraya la complejidad del desarrollo de IA más allá del hardware. Parte de esto se está abordando con proyectos como Barandillas NeMo que está diseñado para mantener la IA generativa precisa y segura.
Pensamientos Finales
NVIDIA DGX GH200 es una solución completa posicionada para redefinir el panorama de la IA. Con su rendimiento incomparable y capacidades avanzadas, es un cambio de juego establecido para impulsar el futuro de la IA. Ya sea que sea un investigador de IA que busca ampliar los límites de lo que es posible o una empresa que busca aprovechar el poder de la IA, el DGX GH200 es una herramienta que puede ayudarlo a alcanzar sus objetivos. Será intrigante observar cómo se aborda la generación de datos de entrenamiento a medida que la potencia de cómputo sin procesar se generaliza. Este aspecto se pasa por alto con frecuencia en las discusiones sobre lanzamientos de hardware.
A fin de cuentas, es importante reconocer el alto costo del sistema DGX GH200. El DGX GH200 no es barato y su precio premium lo coloca directamente dentro del ámbito de las empresas más grandes y las compañías de IA mejor financiadas (NVIDIA, contáctame, quiero uno), pero para aquellas entidades que pueden pagar En él, el DGX GH200 representa una inversión que cambia el paradigma, una que tiene el potencial de redefinir las fronteras del desarrollo y la aplicación de la IA.
A medida que más empresas grandes adopten esta tecnología y comiencen a crear e implementar soluciones avanzadas de IA, podría conducir a una democratización más amplia de la tecnología de IA. Se espera que las innovaciones se conviertan en soluciones más rentables, lo que hará que la IA sea más accesible para las empresas más pequeñas. El acceso basado en la nube a la potencia computacional similar a DGX GH200 está cada vez más disponible, lo que permite a las empresas más pequeñas aprovechar sus capacidades mediante el pago por uso. Si bien el costo inicial puede ser alto, la influencia a largo plazo del DGX GH200 podría extenderse por toda la industria, ayudando a nivelar el campo de juego para empresas de todos los tamaños.
Interactuar con StorageReview
Boletín | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed