
I modelli di intelligenza artificiale di Google Gemma 3 e AMD Instella potenziano le capacità di intelligenza artificiale multimodale e aziendale, ridefinendo gli standard delle prestazioni dell'intelligenza artificiale.
Google e AMD hanno annunciato sviluppi significativi nell'intelligenza artificiale. Google ha introdotto Gemma 3, l'ultima generazione della sua serie di modelli AI open source. Allo stesso tempo, AMD ha annunciato l'integrazione con Open Platform for Enterprise AI (OPEA) e ha lanciato i suoi modelli di linguaggio Instella.
Gemma 3 di Google: efficienza dell'intelligenza artificiale multimodale con hardware minimo
La versione del 12 marzo di Gemma 3 si basa sul successo di Gemma 2. Il nuovo modello introduce funzionalità multimodali, supporto multilingue ed efficienza migliorata, consentendo prestazioni AI avanzate anche su hardware limitato.
Gemma 3 è disponibile in quattro dimensioni: parametri 1B, 4B, 12B e 27B. Ogni variante è disponibile sia in versione base (pre-addestrata) che in versione instruction-tuned. I modelli più grandi (4B, 12B e 27B) offrono funzionalità multimodali, elaborando senza problemi testo, immagini e brevi video. Il codificatore di visione SigLIP di Google converte gli input visivi in token interpretabili dal modello linguistico, consentendo a Gemma 3 di rispondere a domande basate su immagini, identificare oggetti e leggere testo incorporato.
Gemma 3 espande anche significativamente la sua finestra di contesto, supportando fino a 128,000 token rispetto agli 2 token di Gemma 80,000. Ciò consente al modello di gestire più informazioni all'interno di un singolo prompt. Inoltre, Gemma 3 supporta oltre 140 lingue, migliorando l'accessibilità globale.
Classifica LMSYS Chatbot Arena
Gemma 3 è rapidamente emerso come un modello di intelligenza artificiale ad alte prestazioni su LMSYS Chatbot Arena, un benchmark che valuta grandi modelli linguistici basati sulle preferenze umane. Gemma-3-27B ha ottenuto un punteggio Elo di 1338, classificandosi al nono posto a livello mondiale. Ciò lo pone davanti a concorrenti degni di nota come DeepSeek-V3 (1318), Llama3-405B (1257), Qwen2.5-72B (1257), Mistral Large e i precedenti modelli Gemma 2 di Google.
AMD rafforza l'intelligenza artificiale aziendale con l'integrazione OPEA
AMD ha annunciato il suo supporto per Open Platform for Enterprise AI (OPEA) il 12 marzo 2025. Questa integrazione collega il framework OPEA GenAI con lo stack software ROCm di AMD, consentendo alle aziende di distribuire in modo efficiente applicazioni di intelligenza artificiale generativa scalabili su GPU per data center AMD.
La collaborazione affronta le principali sfide dell'AI aziendale, tra cui la complessità dell'integrazione del modello, la gestione delle risorse GPU, la sicurezza e la flessibilità del flusso di lavoro. Come membro del comitato direttivo tecnico di OPEA, AMD collabora con i leader del settore per abilitare soluzioni AI generative componibili che siano distribuibili in ambienti cloud pubblici e privati.
OPEA fornisce componenti essenziali per applicazioni AI, tra cui flussi di lavoro predefiniti, capacità di valutazione, modelli di incorporamento e database vettoriali. La sua architettura basata su microservizi e cloud-native assicura un'integrazione fluida tramite flussi di lavoro basati su API.
AMD lancia Instella: modelli di linguaggio completamente aperti a 3B parametri
AMD ha inoltre presentato Instella, una famiglia di modelli di linguaggio completamente open source da 3 miliardi di parametri, sviluppati interamente su hardware AMD.
Innovazioni tecniche e approccio formativo
I modelli Instella impiegano un'architettura di trasformatore autoregressivo solo testo con 36 livelli di decodifica e 32 teste di attenzione per livello, supportando sequenze fino a 4,096 token. I modelli utilizzano un vocabolario di circa 50,000 token tramite il tokenizzatore OLMo.
Seguendo una pipeline multi-fase, l'addestramento è avvenuto su 128 GPU AMD Instinct MI300X su 16 nodi. Il pre-addestramento iniziale ha coinvolto circa 4.065 trilioni di token da diversi set di dati che coprono codifica, accademici, matematica e cultura generale. Una seconda fase di pre-addestramento ha perfezionato le capacità di risoluzione dei problemi utilizzando altri 57.575 miliardi di token da benchmark specializzati come MMLU, BBH e GSM8k.
Dopo il pre-training, Instella è stata sottoposta a un fine-tuning supervisionato (SFT) con 8.9 miliardi di token di dati istruzione-risposta curati, migliorando le capacità interattive. Una fase finale di Direct Preference Optimization (DPO) ha allineato strettamente il modello alle preferenze umane, utilizzando 760 milioni di token di dati attentamente selezionati.
Prestazioni di riferimento impressionanti
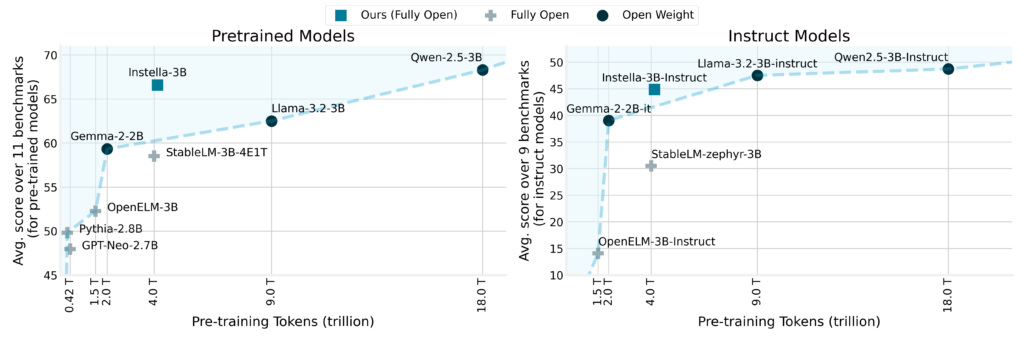
I risultati del benchmark evidenziano i notevoli guadagni di prestazioni di Instella. Il modello ha superato i modelli completamente aperti esistenti con un margine medio di oltre l'8%, con risultati impressionanti in benchmark come ARC Challenge (+8.02%), ARC Easy (+3.51%), Winograde (+4.7%), OpenBookQA (+3.88%), MMLU (+13.12%) e GSM8k (+48.98%).
A differenza dei principali modelli open-weight come Llama-3.2-3B e Gemma-2-2B, Instella ha dimostrato prestazioni superiori o altamente competitive in più attività. La variante instruction-tuned, Instella-3B-Instruct, ha mostrato vantaggi significativi rispetto ad altri modelli instruction-tuned completamente open con un vantaggio medio in termini di prestazioni di oltre il 14%, pur mantenendo prestazioni competitive rispetto ai principali modelli instruction-tuned open-weight.
Rilascio e disponibilità open source completi
In linea con l'impegno di AMD verso i principi open source, l'azienda ha rilasciato tutti gli artefatti correlati ai modelli Instella, inclusi pesi dei modelli, configurazioni di training dettagliate, set di dati e codice. Questa trasparenza completa consente alla comunità AI di collaborare, replicare e innovare con questi modelli.
Conclusione
Questi annunci di Google e AMD preparano il terreno per un anno entusiasmante nell'innovazione dell'IA. Lo slancio del settore è chiaro con Gemma 3 che ridefinisce l'efficienza multimodale e i modelli Instella di AMD e l'integrazione OPEA che potenziano l'IA aziendale. Mentre ci avviciniamo alla conferenza GTC di NVIDIA e anticipiamo ulteriori rilasci rivoluzionari, è evidente che questi sviluppi sono solo l'inizio di ciò che verrà.
Interagisci con StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS feed