
No cenário em constante evolução da inteligência artificial (IA), a NVIDIA DGX GH200 surge como um farol de inovação. Este poderoso sistema, projetado tendo em mente as cargas de trabalho de IA mais exigentes, é uma solução completa definida para revolucionar a forma como as empresas abordam a IA generativa. A NVIDIA tem novos detalhes mostrando como o GH200 vem junto e oferece um pico de desempenho de IA com esta tecnologia de GPU de última geração.
No cenário em constante evolução da inteligência artificial (IA), a NVIDIA DGX GH200 surge como um farol de inovação. Este poderoso sistema, projetado tendo em mente as cargas de trabalho de IA mais exigentes, é uma solução completa definida para revolucionar a forma como as empresas abordam a IA generativa. A NVIDIA tem novos detalhes mostrando como o GH200 vem junto e oferece um pico de desempenho de IA com esta tecnologia de GPU de última geração.

NVIDIA DGX GH200: uma solução completa
O DGX GH200 não é apenas uma peça sofisticada de hardware de rack; é uma solução abrangente que combina computação de alto desempenho (HPC) com IA. Ele foi projetado para lidar com as cargas de trabalho de IA mais complexas, oferecendo um nível de desempenho verdadeiramente incomparável.
O DGX GH200 reúne uma pilha completa de hardware, incluindo o NVIDIA GH200 Grace Hopper Superchip, NVIDIA NVLink-C2C, NVIDIA NVLink Switch System e NVIDIA Quantum-2 InfiniBand, em um sistema. A NVIDIA está apoiando tudo isso com uma pilha de software otimizada projetada especificamente para acelerar o desenvolvimento de modelos.
| Especificação | Detalhes |
|---|---|
| GPU | Funil 96 GB HBM3, 4 TB/s |
| CPU | Braço Neoverse V72 de 2 núcleos |
| Memória CPU | Até 480 GB LPDDR5 em até 500 GB/s, 4x mais eficiente em termos de energia do que DDR5 |
| CPU para GPU | Link coerente bidirecional NVLink-C2C de 900 GB/s, 5 vezes mais eficiente em termos de energia do que o PCIe Gen5 |
| GPU para GPU | NVLink 900 GB/s bidirecional |
| E/S de alta velocidade | 4x PCIe Gen5 x16 até 512 GB/s |
| TDP | Configurável de 450W a 1000W |
Memória estendida da GPU
O NVIDIA Grace Hopper Superchip, equipado com seu recurso Extended GPU Memory (EGM), foi projetado para lidar com aplicativos com grande volume de memória, maior que a capacidade de seus próprios subsistemas de memória HBM3 e LPDDR5X. Esse recurso permite que as GPUs acessem até 144 TBs de memória de todas as CPUs e GPUs do sistema, com cargas de dados, armazenamentos e operações atômicas possíveis em velocidades LPDDR5X. O EGM pode ser usado com bibliotecas MAGNUM IO padrão e pode ser acessado pela CPU e outras GPUs por meio de conexões NVIDIA NVLink e NVLink-C2C.
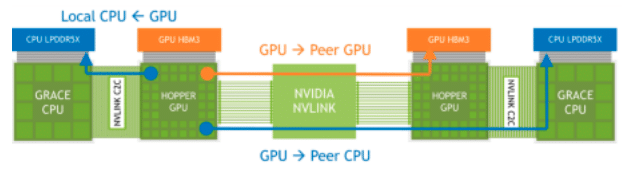
Acessos de memória NVLink através de superchips Grace Hopper conectados
A NVIDIA diz que o recurso Extended GPU Memory (EGM) no NVIDIA Grace Hopper Superchip aprimora significativamente o treinamento de Large Language Models (LLMs) fornecendo uma vasta capacidade de memória. Isso ocorre porque os LLMs geralmente exigem quantidades enormes de memória para armazenar seus parâmetros, cálculos e gerenciar conjuntos de dados de treinamento.
Tendo a capacidade de acessar até 144 TB de memória de todas as CPUs e GPUs do sistema, os modelos podem ser treinados com mais eficiência e eficácia. Uma grande capacidade de memória deve levar a um desempenho mais alto, modelos mais complexos e a capacidade de trabalhar com conjuntos de dados maiores e mais detalhados, melhorando potencialmente a precisão e a utilidade desses modelos.
Sistema de comutação NVLink
Como as demandas de Large Language Models (LLMs) continuam a ultrapassar os limites do gerenciamento de rede, o NVLink Switch System da NVIDIA continua sendo uma solução robusta. Aproveitando o poder da tecnologia NVLink de quarta geração e da arquitetura NVSwitch de terceira geração, este sistema oferece conectividade de alta largura de banda e baixa latência para impressionantes 256 NVIDIA Grace Hopper Superchips no sistema DGX GH200. O resultado são impressionantes 25.6 Tbps de largura de banda full-duplex, marcando um salto substancial nas velocidades de transferência de dados.

Supercomputador DGX GH200 NVSwitch 4ª geração Visão geral da lógica NVLink
No sistema DGX GH200, cada GPU é essencialmente um vizinho intrometido, podendo invadir a memória HBM3 e LPDDR5X de seus pares na rede NVLink. Juntamente com as bibliotecas de aceleração NVIDIA Magnum IO, essa “vizinhança intrometida” otimiza as comunicações da GPU, aumenta a escala com eficiência e duplica a largura de banda efetiva da rede. Assim, enquanto seu treinamento LLM está sendo sobrecarregado e as despesas gerais de comunicação estão aumentando, as operações de IA estão recebendo um impulso turbo.
O NVIDIA NVLink Switch System no DGX GH200 é capaz de melhorar significativamente o treinamento de modelos como LLMs, facilitando a conectividade de alta largura de banda e baixa latência entre um grande número de GPUs. Isso leva a um compartilhamento de dados mais rápido e eficiente entre as GPUs, melhorando assim a velocidade e a eficiência do treinamento do modelo. Além disso, a capacidade de cada GPU de acessar a memória de outros Superchips na rede NVLink aumenta a memória disponível, o que é crítico para LLMs de parâmetros grandes.
Embora o desempenho impressionante dos Superchips Grace Hopper seja indiscutivelmente um divisor de águas no reino dos cálculos de IA, a verdadeira mágica desse sistema acontece no NVLink, onde conectividade de alta largura de banda e baixa latência em várias GPUs leva compartilhamento de dados e eficiência a um nível totalmente novo.
Arquitetura do sistema DGX GH200
A arquitetura do supercomputador DGX GH200 é complexa, mas meticulosamente projetada. Composto por 256 bandejas de computação Grace Hopper GH200 e um sistema de comutação NVLink que forma uma árvore gorda NVLink de dois níveis. Cada bandeja de computação abriga um superchip GH200 Grace Hopper, componentes de rede, um sistema de gerenciamento/BMC e SSDs para armazenamento de dados e execução do sistema operacional.
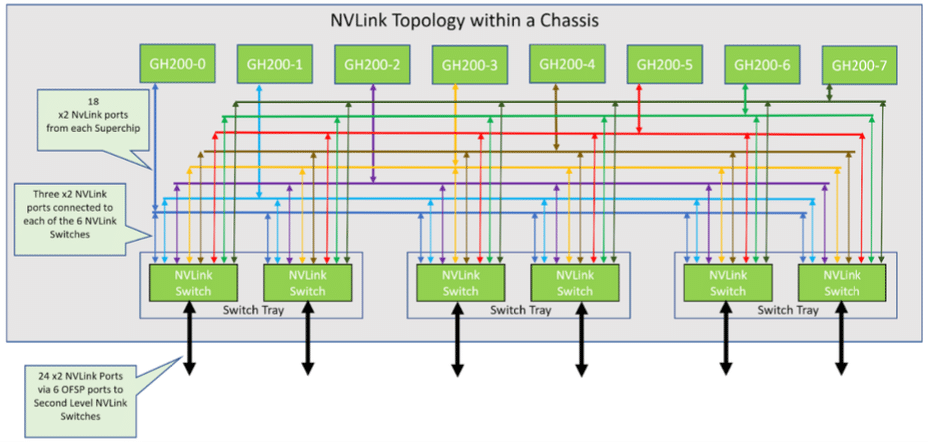
Topologia NVLink em 8-GraceHopper Superchip Chassis
| Categoria | Detalhes |
|---|---|
| CPU / GPU | 1x Superchip NVIDIA Grace Hopper com NVLink-C2C |
| GPU/GPU | 18 portas NVLink de quarta geração |
| Networking | 1x NVIDIA ConnectX-7 com OSFP: > Rede de computação NDR400 InfiniBand 1x NVIDIA BlueField-3 de porta dupla com 2x QSFP112 ou 1x NVIDIA ConnectX-7 de porta dupla com 2x QSFP112: > Rede Ethernet em banda de 200 GbE > Rede de armazenamento NDR200 IB Rede Fora de Banda: > 1 GbE RJ45 |
| Armazenamento | Unidade de dados: 2 x 4 TB (U.2 NVMe SSDs) SW RAID 0 Unidade do sistema operacional: 2 x 2 TB (SSDs M.2 NVMe) SW RAID 1 |
Nesta configuração, oito bandejas de computação são vinculadas a três bandejas NVLink NVSwitch de primeiro nível para estabelecer um único chassi de 8 GPUs. Cada bandeja do switch NVLink possui dois ASICs NVSwitch que se conectam às bandejas de computação por meio de um cartucho de cabo blind mate personalizado e aos switches NVLink de segundo nível por meio de cabos LinkX.
O sistema resultante compreende 36 switches NVLink de segundo nível que conectam 32 chassis para formar o abrangente supercomputador NVIDIA DGX GH200. Para obter mais informações, consulte a Tabela 2 para obter as especificações da bandeja de computação com Grace Hopper Superchip e a Tabela 3 para obter as especificações do comutador NVLink.
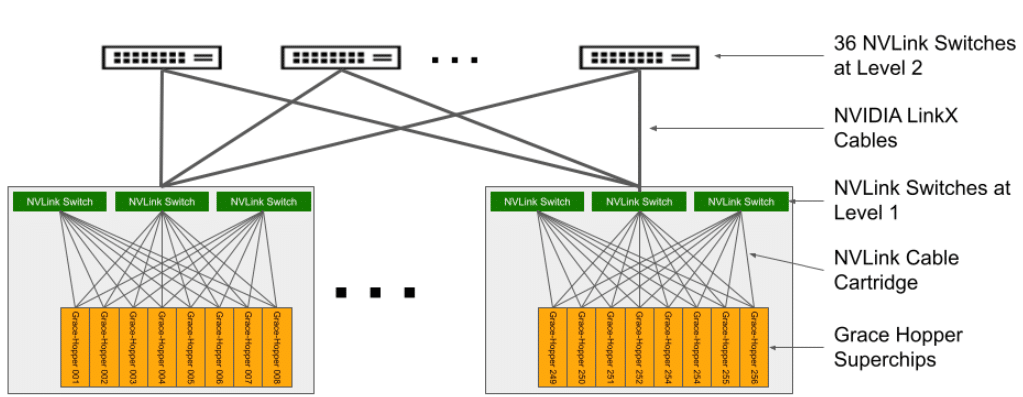
Topologia DGX GH200 NVLink
Arquitetura de rede do DGX GH200
O sistema NVIDIA DGX GH200 incorpora quatro arquiteturas de rede sofisticadas para fornecer soluções computacionais e de armazenamento de ponta. Em primeiro lugar, um Compute InfiniBand Fabric, construído a partir de switches NVIDIA ConnectX-7 e Quantum-2, forma um tecido NDR400 InfiniBand de árvore totalmente otimizado para trilhos, permitindo conectividade perfeita entre várias unidades DGX GH200.
Em segundo lugar, o Storage Fabric, impulsionado pela unidade de processamento de dados (DPU) NVIDIA BlueField-3, oferece armazenamento de alto desempenho por meio de uma porta QSFP112. Isso estabelece uma rede de armazenamento dedicada e personalizável que evita habilmente o congestionamento do tráfego.
O in-band Management Fabric serve como a terceira arquitetura, conectando todos os serviços de gerenciamento do sistema e facilitando o acesso a pools de armazenamento, serviços no sistema, como Slurm e Kubernetes, e serviços externos, como NVIDIA GPU Cloud.
Por fim, o Out-of-band Management Fabric, operando em 1GbE, supervisiona o gerenciamento essencial fora de banda para os superchips Grace Hopper, BlueField-3 DPU e switches NVLink por meio do Baseboard Management Controller (BMC), otimizando as operações e evitando conflitos com outros serviços.
Liberando o poder da IA – pilha de software NVIDIA DGX GH200
O DGX GH200 tem toda a potência bruta que os desenvolvedores poderiam desejar; é muito mais do que apenas um supercomputador sofisticado. Trata-se de aproveitar esse poder para impulsionar a IA. Sem dúvida, a pilha de software que acompanha o DGX GH200 é um de seus recursos de destaque.
Essa solução abrangente inclui vários SDKs, bibliotecas e ferramentas otimizadas projetadas para aproveitar totalmente os recursos do hardware, garantindo dimensionamento eficiente de aplicativos e desempenho aprimorado. No entanto, a amplitude e a profundidade da pilha de software do DGX GH200 merecem mais do que uma menção passageira, certifique-se de verificar Informe técnico da NVIDIA sobre o tema para um mergulho profundo na pilha de software.
Requisitos de armazenamento do DGX GH200
Para aproveitar totalmente os recursos do sistema DGX GH200, é crucial combiná-lo com um sistema de armazenamento balanceado e de alto desempenho. Cada sistema GH200 tem a capacidade de ler ou gravar dados em velocidades de até 25 GB/s na interface NDR200. Para uma configuração 256 Grace Hopper DGX GH200, a NVIDIA sugere um desempenho de armazenamento agregado de 450 GB/s para maximizar a taxa de transferência de leitura.
A necessidade de alimentar projetos de IA e as GPUs subjacentes, com armazenamento apropriado, é a conversa mais popular do circuito de feiras de negócios do verão. Literalmente, todos os shows em que participamos têm algum segmento de sua palestra dedicado a fluxos de trabalho e armazenamento de IA. Resta saber, no entanto, quanto dessa conversa é apenas reposicionar os produtos de armazenamento existentes e quanto disso leva a melhorias significativas para o armazenamento de IA. No momento, é muito cedo para dizer, mas estamos ouvindo muitos rumores de fornecedores de armazenamento que têm o potencial de levar a mudanças significativas nas cargas de trabalho de IA.
Um obstáculo saltado, mais a seguir
Embora o DGX GH200 simplifique o aspecto de design de hardware do desenvolvimento de IA, é importante reconhecer que no campo da IA generativa existem outros desafios consideráveis; geração de dados de treinamento.
O desenvolvimento de um modelo de IA generativa requer um imenso volume de dados de alta qualidade. Mas os dados, em sua forma bruta, não podem ser usados imediatamente. Requer esforços extensivos de coleta, limpeza e rotulagem para torná-lo adequado para o treinamento de modelos de IA.
A coleta de dados é a etapa inicial e envolve a obtenção e o acúmulo de grandes quantidades de informações relevantes, o que geralmente pode ser demorado e caro. Em seguida, vem o processo de limpeza de dados, que requer atenção meticulosa aos detalhes para identificar e corrigir erros, lidar com entradas ausentes e eliminar quaisquer dados irrelevantes ou redundantes. Por fim, a tarefa de rotulagem de dados, etapa essencial do aprendizado supervisionado, envolve a classificação de cada ponto de dados para que a IA possa entendê-lo e aprender com ele.
A qualidade dos dados de treinamento é fundamental. Dados sujos, de baixa qualidade ou tendenciosos podem levar a previsões imprecisas e tomadas de decisão incorretas pela IA. Ainda há necessidade de conhecimento humano e um grande esforço é necessário para garantir que os dados usados no treinamento sejam abundantes e da mais alta qualidade.
Esses processos não são triviais, exigindo recursos significativos, tanto humanos quanto de capital, incluindo conhecimento especializado dos dados de treinamento, ressaltando a complexidade do desenvolvimento da IA além do hardware. Parte disso está sendo abordado com projetos como Guarda-corpos NeMo que é projetado para manter o Generative AI preciso e seguro.
Pensamentos de Encerramento
A NVIDIA DGX GH200 é uma solução completa posicionada para redefinir o panorama da IA. Com seu desempenho incomparável e recursos avançados, é um divisor de águas definido para impulsionar o futuro da IA. Seja você um pesquisador de IA procurando ultrapassar os limites do que é possível ou uma empresa que deseja aproveitar o poder da IA, o DGX GH200 é uma ferramenta que pode ajudá-lo a atingir seus objetivos. Será intrigante observar como a geração de dados de treinamento é abordada à medida que o poder de computação bruto se torna mais difundido. Esse aspecto é frequentemente negligenciado nas discussões sobre lançamentos de hardware.
Considerando tudo, é importante reconhecer o alto custo do sistema DGX GH200. O DGX GH200 não sai barato e seu preço premium o coloca diretamente no domínio das maiores empresas e das empresas de IA mais bem financiadas (NVIDIA, me ligue, eu quero um), mas para aquelas entidades que podem pagar nele, o DGX GH200 representa um investimento de mudança de paradigma, que tem o potencial de redefinir as fronteiras do desenvolvimento e aplicação de IA.
À medida que mais grandes empresas adotam essa tecnologia e começam a criar e implantar soluções avançadas de IA, isso pode levar a uma democratização mais ampla da tecnologia de IA. Espera-se que as inovações se traduzam em soluções mais econômicas, tornando a IA mais acessível para empresas menores. O acesso baseado em nuvem ao poder computacional do tipo DGX GH200 está se tornando mais amplamente disponível, permitindo que empresas menores aproveitem seus recursos com base no pagamento por uso. Embora o custo inicial possa ser alto, a influência de longo prazo do DGX GH200 pode se espalhar pela indústria, ajudando a nivelar o campo de jogo para empresas de todos os tamanhos.
Envolva-se com a StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS feed