
![]() 今天在 AWS 全球峰会上,Alluxio 宣布了其数据编排技术的最新版本 Alluxio 2.0。 最新版本为数据工程师带来了新的创新,旨在多云分析和人工智能。
今天在 AWS 全球峰会上,Alluxio 宣布了其数据编排技术的最新版本 Alluxio 2.0。 最新版本为数据工程师带来了新的创新,旨在多云分析和人工智能。
今天在 AWS 全球峰会上,Alluxio 宣布了其数据编排技术的最新版本 Alluxio 2.0。 最新版本为数据工程师带来了新的创新,旨在多云分析和人工智能。
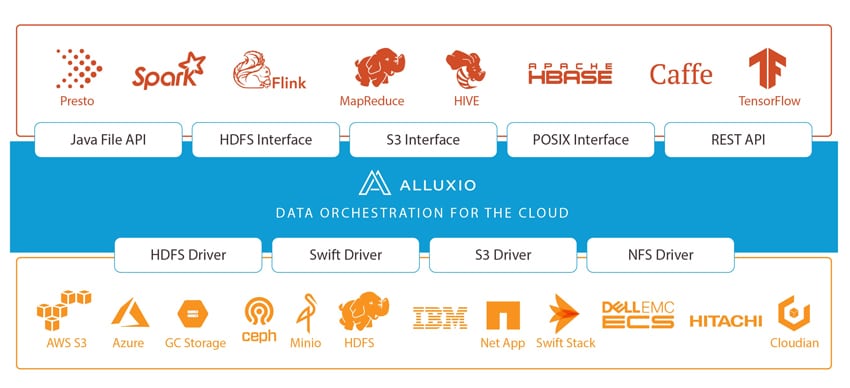
正如我们最初所说,Alluxio 表示他们是世界上第一个以内存速度统一数据的系统。 “内存速度”将使企业能够跨不同的存储系统快速访问数据,这反过来意味着他们可以更有效地管理他们的数据,更快地发现有价值的见解,并简化他们对混合云的采用。 目前,Alluxio 为阿里巴巴、百度、巴克莱银行、CERN、ESRI、华为、英特尔和瞻博网络等公司运行关键工作负载。
世界正在转向基于云的计算密集型工作负载。 这种新的关注点意味着计算需要以弹性方式独立于存储进行扩展。 虽然从性能角度来看这有几个好处,但它给数据工程师带来了潜在的麻烦。 Alluxio 旨在通过添加一个抽象层来解决这个问题,该抽象层带来数据局部性、数据可访问性和数据弹性,以跨数据孤岛、区域、区域甚至云进行计算。
特点和能力包括:
- 多云的数据编排创新:
- 策略驱动的数据管理
- Alluxio 2.0 包含一项新功能,允许数据工程师根据预定义的策略自动和持续地跨存储系统自动移动数据。 这意味着随着数据的创建和热、温、冷数据的管理,Alluxio 可以在本地和所有云中跨任意数量的存储系统自动对数据进行分层。
- 数据平台团队现在可以通过仅自动管理昂贵存储系统中最重要的数据并将其他数据转移到更便宜的存储替代方案来降低存储成本。
- 改进的数据访问策略管理:除了文件级别的细粒度策略外,现在用户还可以在任何目录和文件夹级别配置策略,以简化数据访问和工作负载的性能。 这些包括在各种核心功能上为单个数据集定义行为,例如在 Alluxio 下写入数据或与存储系统同步数据。
- 通过数据服务跨云存储高效数据移动:新数据服务允许高效数据移动,包括跨云存储(如 AWS S3 和谷歌 GCS),使对象存储上的昂贵操作与计算框架无缝衔接。
- 策略驱动的数据管理
- 为云分析计算优化数据访问:
- 以计算为中心的集群分区:用户现在可以根据任何维度对单个 Alluxio 进行分区,这样每个框架或工作负载的数据集就不会被另一个所污染。 最常见的用法包括通过 Spark、Presto 等框架对集群进行分区。此外,这还可以降低数据传输成本,将数据限制在特定区域或区域内。
- 通过 REST 与外部数据源集成:用户现在甚至可以从基于 Web 的数据源引入数据,以在 Alluxio 中聚合以执行他们的分析。 任何带有文件的 Web 位置都可以简化指向 Alluxio,以便根据查询或模型运行按需拉入。
- 其他功能包括:
- 高度分布式数据服务 - 2.0 引入了 Alluxio 数据服务,这是一种分布式集群服务,可进行复制、持久化等数据操作,以实现高性能和大规模。
- 用于增加数据局部性的自适应复制——新功能可以为存储在 Alluxio 中的自动管理的数据副本数量配置一个范围。
- 嵌入式日志的高可用性——一种新的文件和对象元数据容错和高可用性模式,称为嵌入式日志,它使用 RAFT 共识算法并且独立于任何其他外部存储系统。 这对于抽象对象存储特别有帮助。
- Alluxio POSIX API——Alluxio 的 FUSE 功能支持 POSIX 兼容 API,因此 Tensorflow、Caffe 和其他基于 Python 的模型等框架可以使用传统文件系统访问通过 Alluxio 直接访问任何存储系统中的数据。
- 亚马逊 AWS 支持:
- AWS Elastic Map Reduce (EMR) 服务集成:随着用户转向云服务来部署分析和 AI 工作负载,AWS EMR 等服务的使用越来越多。 Alluxio 现在可以无缝地引导到 AWS EMR 集群中,使其可用作 Spark、Presto 和 Hive 框架的 EMR 中的数据层。 用户现在有一个高性能的替代方案来缓存来自 S3 或远程数据的数据,同时还减少了在 EMR 中维护的数据副本。
可用性
Alluxio 2.0 社区版和企业版现已推出。
讨论这个故事