
Meta 推出了 Llama 4,这是一个强大的基于 MoE 的 AI 模型系列,可提供更高的效率、可扩展性和多模式性能。
Meta 推出了其最新的 AI 创新产品 Llama 4,这是一组可增强多模态智能能力的模型。Llama 4 基于 Mixture-of-Experts (MoE) 架构,可提供卓越的效率和性能。
理解 MoE 模型和稀疏性
混合专家 (MoE) 模型与传统的密集模型有很大不同,在传统密集模型中,整个模型会处理每个输入。在 MoE 模型中,对于每个输入,只会激活总参数的一个子集(称为“专家”)。这种选择性激活取决于输入的特征,使模型能够动态分配资源并提高效率。
稀疏性是 MoE 模型中的一个重要概念,表示特定输入的非活动参数的比例。MoE 模型可以利用稀疏性显著降低计算成本,同时保持或提高性能。
认识 Llama 4 家族:Scout、Maverick 和 Behemoth
Llama 4 套件包含三种型号:Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth。每种型号都旨在满足不同的使用情况和要求。
- Llama 4 Scout 是一个紧凑型模型,拥有 17 位专家的 109 亿个活动参数和 16 亿个总参数。它针对效率进行了优化,可以在单个 NVIDIA H100 GPU(FP4 Quantized)上运行。Scout 拥有令人印象深刻的 10 万个 token 上下文窗口,使其成为需要长上下文理解的应用程序的理想选择。
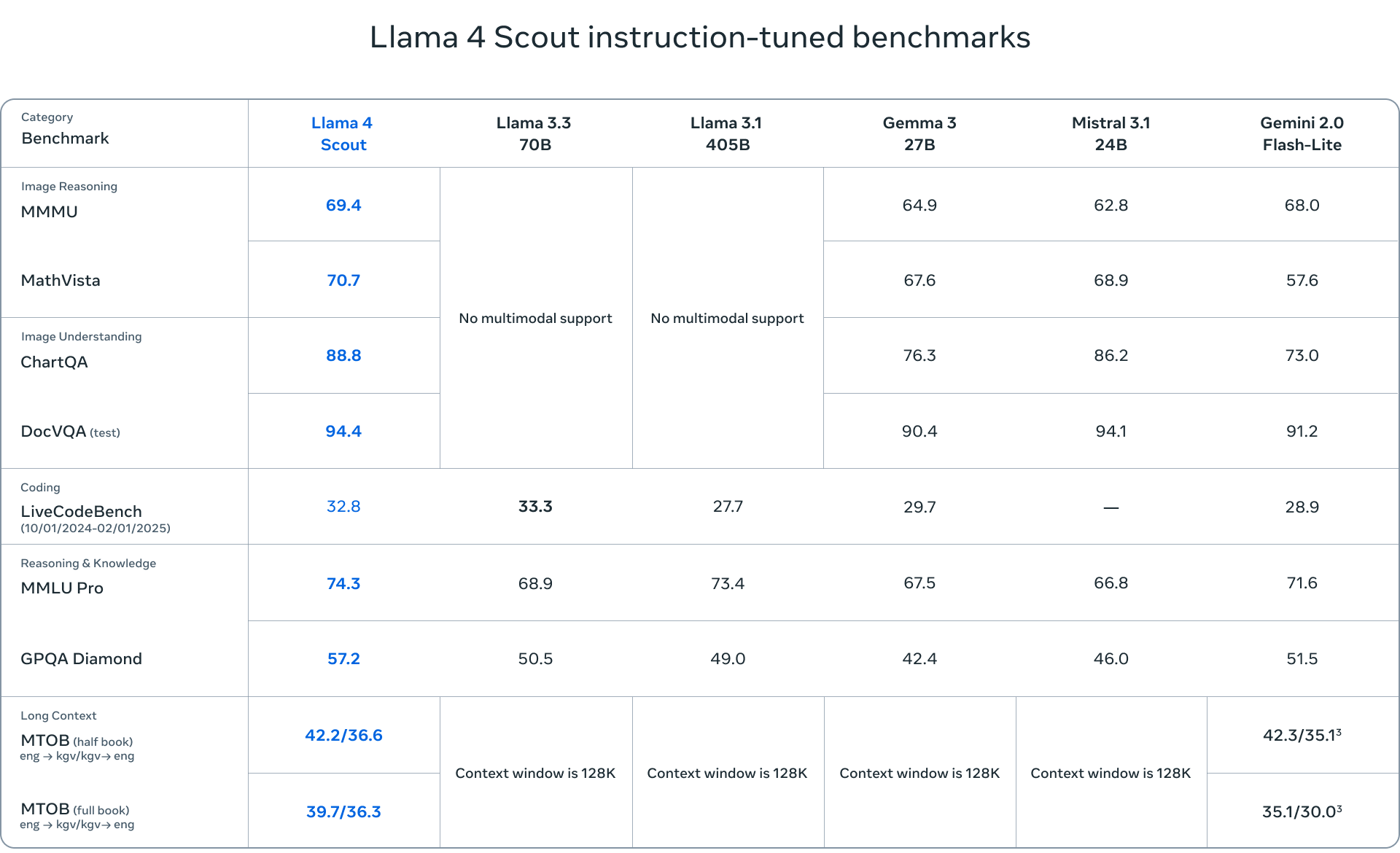
- Llama 4 Maverick 是一个更强大的模型,拥有相同的 17 亿个活动参数,但拥有 128 位专家,总计 400 亿个参数。Maverick 在多模态理解、多语言任务和编码方面表现出色,超越了 GPT-4o 和 Gemini 2.0 Flash 等竞争对手。
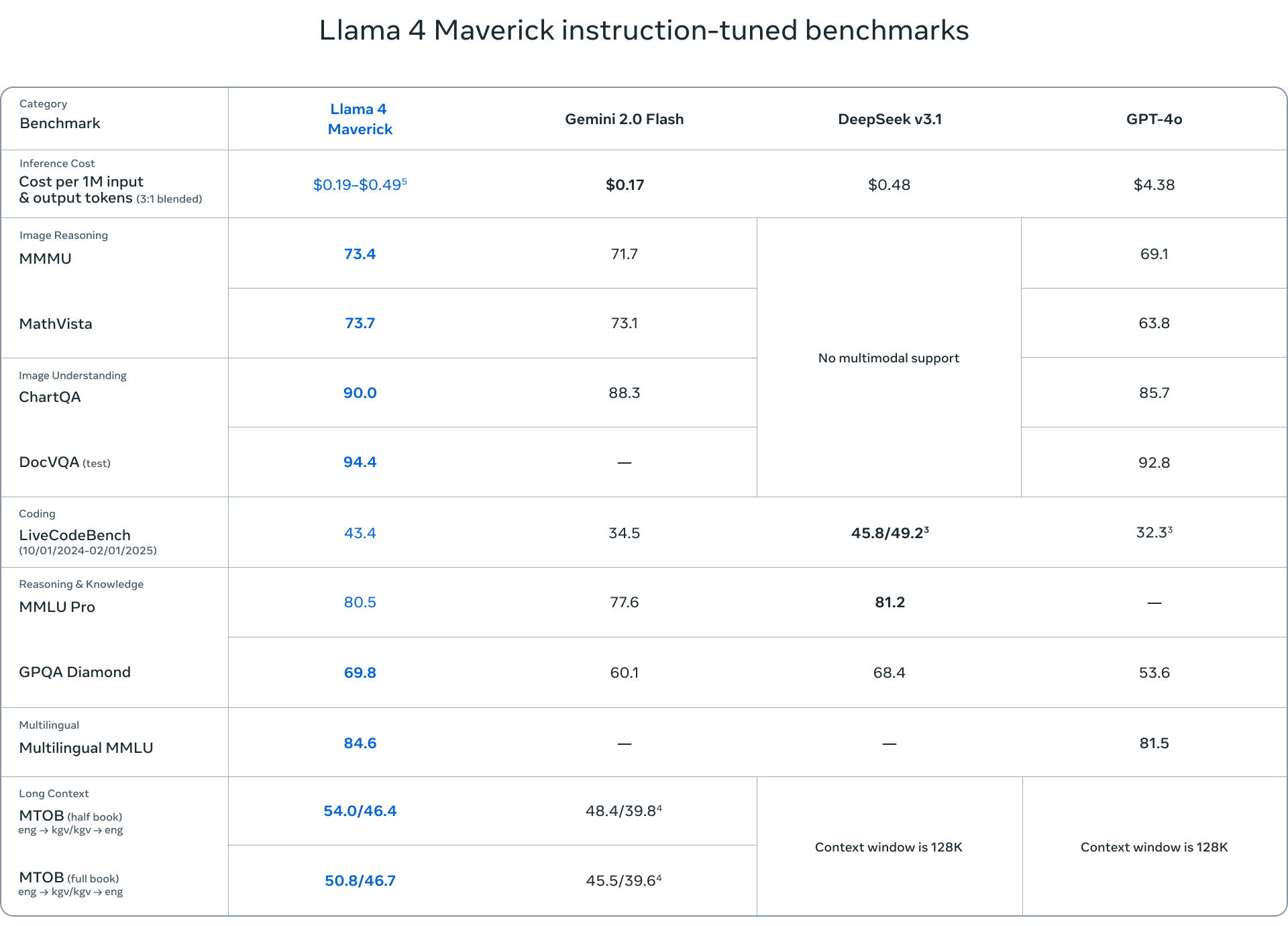
- Llama 4 Behemoth 是该套件中最大的模型,拥有 288 亿个活动参数和近 2 万亿个来自 16 位专家的总参数。尽管仍在训练中,但 Behemoth 已经在各种基准上展示了最先进的性能,超越了 GPT-4.5 和 Claude Sonnet 3.7 等模型。
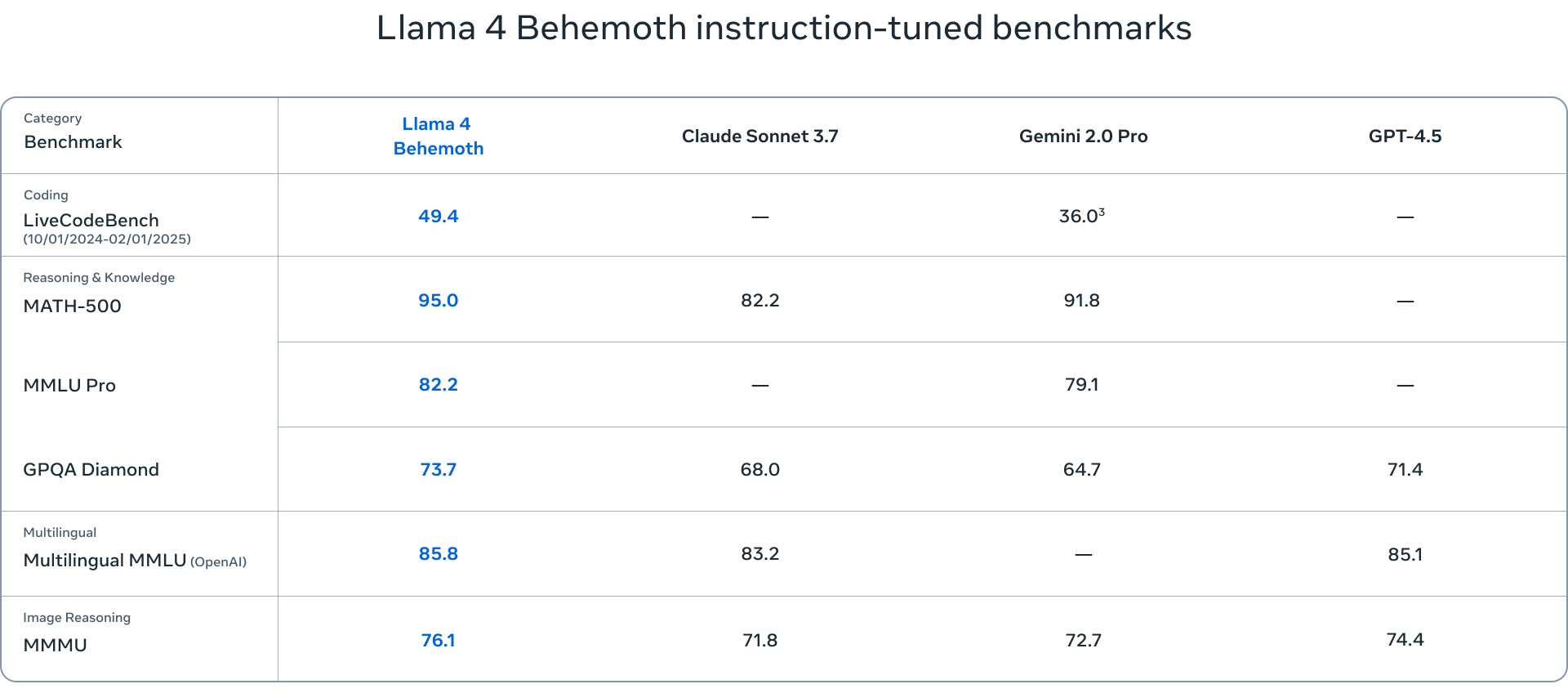
评估 Llama 4 模型的基准涵盖了一系列任务,包括语言理解(MMLU – 大规模多任务语言理解、GPQA – Google 验证问答)、数学问题解决(MATH – 数学问题解决、MathVista – 视觉环境下数学问题解决基准)和多模态理解(MMMU – 大规模多模态多任务理解)。这些标准基准对模型的能力进行了全面的评估,并有助于确定模型的优势或需要进一步改进的领域。
《骆驼4》中教师模型的作用
教师模型是一种大型的预训练模型,用于指导小型模型,通过提炼将其知识和能力传递给它们。在 Llama 4 中,Behemoth 充当教师模型,将其知识提炼给 Scout 和 Maverick。提炼过程包括训练小型模型以模仿教师模型的行为,让它们从教师模型的优点和缺点中学习。这种方法使小型模型能够实现令人印象深刻的性能,同时提高效率和可扩展性。
影响和未来方向
Llama 4 的发布标志着 AI 领域的一个重要里程碑,对研究、开发和应用具有深远的影响。从历史上看,Llama 模型一直是下游研究的催化剂,激发了各种研究和创新。Llama 4 的发布预计将延续这一趋势,使研究人员能够在此基础上构建和微调模型以应对复杂的任务和挑战。
许多模型都经过了微调,并基于 Llama 模型构建而成,这证明了 Llama 架构的多功能性和潜力。Llama 4 的发布可能会加速这一趋势,因为研究人员和开发人员可以利用这些模型来创建新的创新应用程序。这一点意义重大,因为 Llama 4 是一个强大的模型发布,将支持广泛的研究和开发活动。
值得注意的是,Llama 4 模型与前代产品类似,不具备思考能力。因此,未来发布的 Llama 4 系列产品可能会进行推理后训练,从而进一步提高其性能。
参与 StorageReview
电子报 | YouTube | 播客 iTunes/Spotify | Instagram | Twitter | TikTok | RSS订阅