
Meta Platforms 已为 AI Research SuperCluster (RSC) 选择了 NVIDIA DGX A100 系统。 完全部署后,Meta 的 RSC 有望成为最大的 NVIDIA DGX A100 系统。 AI Research SuperCluster (RSC) 已经在训练新模型来推进 AI。
Meta Platforms 已为 AI Research SuperCluster (RSC) 选择了 NVIDIA DGX A100 系统。 完全部署后,Meta 的 RSC 有望成为最大的 NVIDIA DGX A100 系统。 AI Research SuperCluster (RSC) 已经在训练新模型来推进 AI。
元研究超级集群

Meta 的 AI Research SuperCluster 具有数百个连接在 NVIDIA Quantum InfiniBand 网络上的 NVIDIA DGX 系统,以加速其 AI 研究团队的工作。
RSC 预计将在今年晚些时候全面建成,Meta 将使用它来训练具有超过一万亿参数的 AI 模型。 RSC 将在诸如实时识别有害内容等工作的自然语言处理等领域取得进展。 除了大规模性能外,Meta 还将极端的可靠性、安全性、隐私和处理“广泛的人工智能模型”的灵活性作为 RSC 的关键标准。

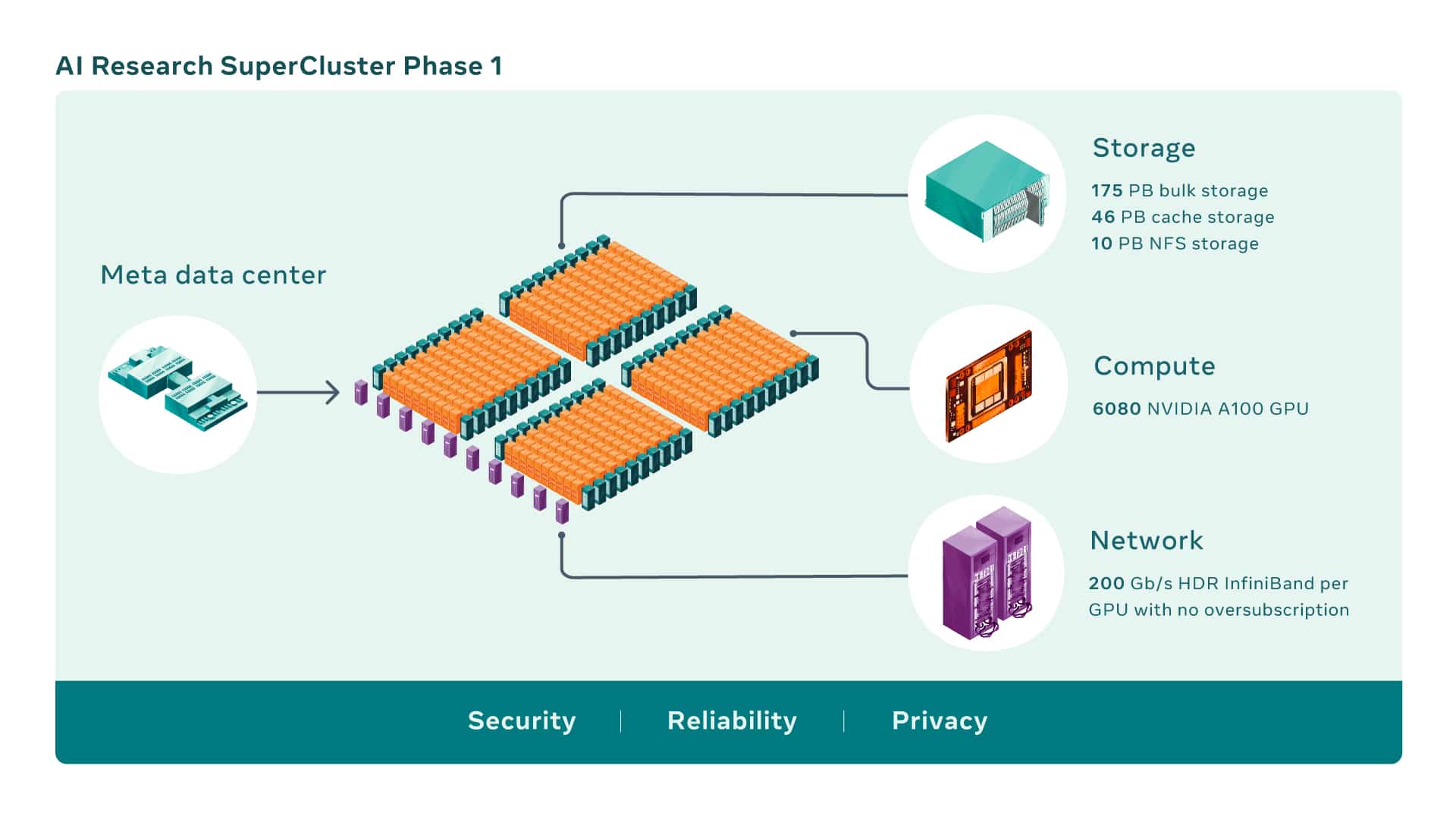
AI 超级计算机是通过将多个 GPU 组合成计算节点而构建的,然后通过高性能网络结构连接这些节点以允许这些 GPU 之间的快速通信。 今天的 RSC 共有 760 个 英伟达 DGX A100 系统作为其计算节点,总共有 6,080 个 GPU——每个 A100 GPU 都比以前系统中使用的 V100 更强大。

GPU 通过一个 NVIDIA 量子 200 Gb/s InfiniBand 没有超额订阅的两级 Clos 结构。 RSC 的存储层拥有 175 PB 的 Pure Storage FlashArray、46 PB 的 Penguin Computing Altus 系统缓存存储和 10 PB 的 Pure Storage FlashBlade。


与 Meta 的传统生产和研究基础设施相比,RSC 的早期基准测试表明,它运行计算机视觉工作流程的速度提高了 20 倍,运行 NVIDIA 集体通信库 (NCCL) 的速度提高了 XNUMX 倍以上,并且训练了大规模的 NLP 模型快三倍。 这意味着一个拥有数百亿参数的模型可以在三周内完成训练,而之前需要九周。
RSC 完成后,InfiniBand 网络结构将连接 16,000 个 GPU 作为端点,使其成为迄今为止部署的最大此类网络之一。 此外,设计的缓存和存储系统可以提供 16 TB/s 的训练数据,并将其扩展到 1 EB。

虽然 RSC 今天已启动并运行,但它的开发仍在继续。 一旦构建 RSC 的第二阶段完成,它有望成为世界上最快的 AI 超级计算机,以近 5 exaflops 的混合精度计算执行。

工作将持续到 2022 年,将 GPU 的数量从 6,080 个增加到 16,000 个,将 AI 训练性能提高 2.5 倍以上。 InfiniBand 结构将扩展为支持两层拓扑结构中的 16,000 个端口,并且没有超额订阅。 该存储系统将具有 16 TB/s 的目标传输带宽和 EB 级容量,以满足不断增长的需求。
参与 StorageReview
电子报 | YouTube | 播客 iTunes/Spotify | Instagram | Twitter | Facebook | TikTok | RSS订阅