
StorageReview und unsere Partner haben Pi gerade auf 105 Billionen Stellen gelöst, ein neuer Weltrekord, der den vorherigen Rekord um fünf Prozent übertrifft.
Wir sind kein Unbekannter darin, die Grenzen der Berechnung zu erweitern, aber dieses hier erfordert den Pi(e). Direkt auf den Fersen des letzten Jahres 100 Um den Billionen-Stellen-Benchmark zu erreichen, haben wir beschlossen, ihn zu erhöhen und die bekannten Ziffern von Pi auf 105 Billionen Stellen zu erhöhen. Das sind 105,000,000,000,000 Zahlen nach der 3. Wir haben ein paar Aktualisierungen der Plattform im Vergleich zum letzten Jahr vorgenommen, dabei ein paar überraschende Dinge gefunden und dabei einiges gelernt – darunter die 105 Billionenste Ziffer von Pi;6!

Mit der rekordverdächtigen Berechnung von Pi auf 105 Billionen Stellen hat das StorageReview-Labor die unglaublichen Fähigkeiten moderner Hardware unterstrichen. Dieses Unterfangen, das auf einem hochmodernen 2P 128-Core AMD EPYC Bergamo-System basiert, das mit 1.5 TB DRAM und fast einem Petabyte Solidigm QLC SSDs ausgestattet ist, stellt einen Meilenstein in der Rechen- und Speichertechnologie dar.
Die Herausforderung
Bei der digitalen 100-Billionen-Marke stießen wir auf mehrere technologische Einschränkungen. Die Serverplattform unterstützte beispielsweise nur 16 NVMe-SSDs in den vorderen Steckplätzen. Obwohl wir über ausreichend CPU-Leistung verfügten, erforderte diese Berechnung während des Prozesses und im Backend, als die endgültige TXT-Datei ausgegeben wurde, enormen Speicherplatz.
Um das Speicherproblem beim letzten Mal zu lösen, haben wir auf PCIe-NVME-Adapterschlitten zurückgegriffen, um drei weitere SSDs unterzubringen. Dann hatten wir für die Ausgabe einen HDD-Speicherserver in RAID0, wohlgemerkt, mit einer iSCSI-Freigabe zurück zur Rechenbox. Dieses Mal wollten wir mit diesem Server etwas „unternehmerischer“ werden, also haben wir ein paar Freunde hinzugezogen, die uns helfen. Interessanterweise ist es nicht so einfach, wie es scheint, eine Reihe von NVMe-SSDs zu einem Server hinzuzufügen.
Die Hardware
Das Herzstück dieser monumentalen Aufgabe war das Dual-Prozessor-System AMD EPYC 9754 Bergamo mit jeweils 128 Kernen. Die Prozessoren von AMD sind für ihre außergewöhnliche Leistung bei hochkomplexen Rechenaufgaben bekannt (KI, HPC, Big Data Analytics), sorgte für die nötigen PS. Hinzu kamen 1.5 TB DRAM, was eine schnelle Datenverarbeitung und Übertragungsgeschwindigkeit gewährleistete. Gleichzeitig fast ein Petabyte Solidigm QLC-Speicher bot beispiellose Kapazität und Zuverlässigkeit.

Unsere Basis-Chassis-Plattform blieb die gleiche wie im letzten Jahr (eine QCT-Box), aber wir haben die CPUs auf AMD EPYC 9754 Bergamo-Chips aufgerüstet. Wir wollten eine Geschwindigkeits- und Dezimalverbesserung anstreben und gleichzeitig die Verwendung von Speicher für die Berechnung vermeiden, was bedeutete, dass wir SerialCables mit der Bereitstellung eines JBOF beauftragen mussten. Dies stellte einige Herausforderungen für sich dar, auf die wir im Folgenden näher eingehen.
| Parameter | Wert |
|---|---|
| Kursstart | Di, 19. Dez. 14:10:48 2023 |
| Enddatum | Dienstag, 27. Februar, 09:53:16 Uhr 2024 |
| Gesamtrechenzeit | 5,363,970.541 Sekunden / 62.08 Tage |
| Wandzeit von Anfang bis Ende | 6,032,547.913 Sekunden / 69.82 Tage |
Berechnungszeitraum: 14. Dezember 2023 – 27. Februar 2024, über 75 Tage.
- ZENTRALPROZESSOR: Zwei AMD Epyc 9754 Bergamo-Prozessoren, 256 Kerne mit im BIOS deaktiviertem Simultaneous Multithreading (SMT).
- Erinnerung: 1.5 TB DDR5-RAM.
- Lagerung: 36x 30.72 TB Solidigm D5-P5316 SSDs.
- 24x 30.72 TB Solidigm D5-P5316 SSDs in einem SerialCables JBOF
- 12x 30.72 TB Solidigm D5-P5316 SSDs im Server Direct Attached.
- Betriebssystem: Windows Server 2022 (21H2).
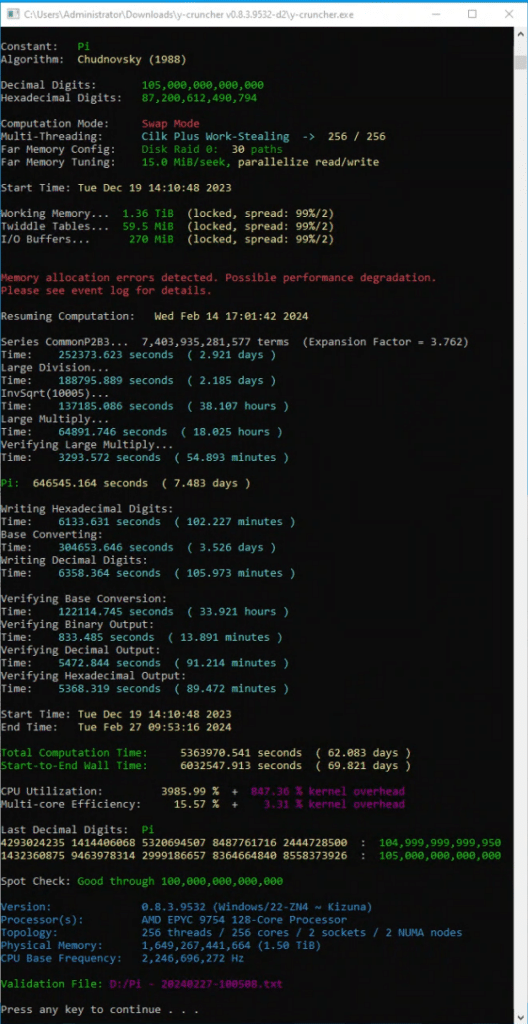
Der Weg zu 105 Billionen
| Parameter | Wert |
|---|---|
| Konstant | Pi |
| Algorithmus | Tschudnowski (1988) |
| Dezimalziffern | 105,000,000,000,000 |
| Hexadezimale Ziffern | 87,200,612,490,794 |
| Threading-Modus | Cilk Plus Arbeitsdiebstahl -> 256/256 |
| Arbeitsspeicher | 1,492,670,259,968 (1.36 TiB) |
| Gesamtspeicher | 1,492,984,298,368 (1.36 TiB) |
| Logisch größter Kontrollpunkt | 157,783,654,587,576 (144 TiB) |
| Logische Spitzenauslastung der Festplatte | 534,615,969,510,896 (486 TiB) |
| Gelesene Bytes der logischen Festplatte | 44,823,456,487,834,568 (39.8 PiB) |
| Geschriebene Bytes der logischen Festplatte | 38,717,269,572,788,080 (34.4 PiB) |
Auf Herausforderungen gestoßen
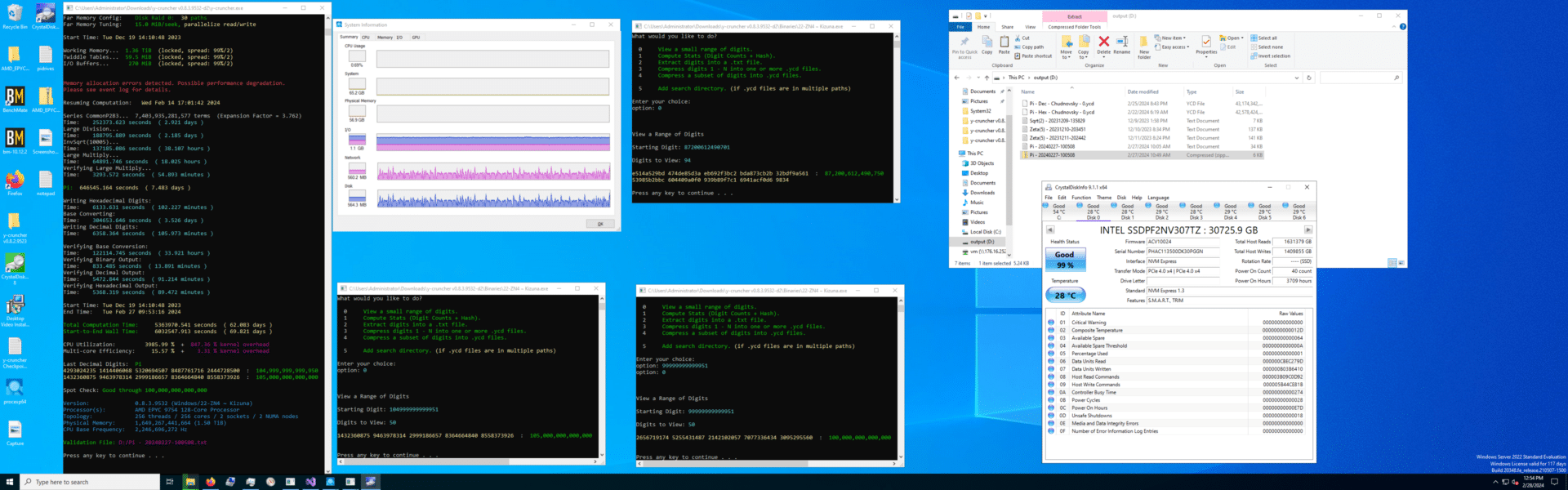
Eine neue Komponente bei diesem Lauf, die erforderlich war, um den verfügbaren Speicher für die Prozessoren zu erweitern, war das Hinzufügen eines NVMe-JBOF. Unsere Testplattform bot 16 NVMe-Schächte, die restlichen acht waren nur für SATA verkabelt. Während unser 100-Billionen-Durchlauf drei interne PCIe-U.2-Adapter nutzte, um die Anzahl unserer NVMe-Laufwerke auf 19 zu erhöhen, war dies nicht optimal. Für diese Wiederholung haben wir ein hinzugefügt Serielle Kabel 24-Bay U.2 JBOF, was in zweierlei Hinsicht erheblich geholfen hat: mehr Compute-Swap-Speicher und interner Ausgabedateispeicher. Kein verrückter RAID0-HDD-Speicherserver mehr!

Mit dem 24-Bay-JBOF von Serial Cables konnten wir die Anzahl der Laufwerke im Vergleich zu unserem ursprünglichen Versuch fast verdoppeln. Wir haben dem Y-Cruncher-Swap-Space 30 Laufwerke zugewiesen, sodass 6 SSDs für ein Storage Spaces RAID5-Ausgabevolume übrig blieben. Ein großer Vorteil dieses Ansatzes zeigte sich in der Ausgangsphase, wo wir nicht durch die Geschwindigkeit einer einzelnen 10-Gbit-Verbindung eingeschränkt wurden, wie bei der ersten 100T-Pi-Iteration. Das JBOF befasste sich zwar mit dem Problem der Gesamtanzahl der Laufwerke, führte jedoch zu einer Einschränkung: der Leistung einzelner Laufwerke.
In einem Server mit direkt angeschlossenen U.2-SSDs gibt es vier PCIe-Lanes pro Laufwerk. Wenn jedes Laufwerk direkt mit dem Motherboard verbunden ist, ergibt das 96 PCIe-Lanes für 24 SSDs. Die Gesamtbandbreite des JBOF ist durch die Anzahl der PCIe-Lanes begrenzt, die er mit dem Host verbinden kann.
In diesem Fall haben wir zwei PCIe-Switch-Hostkarten verwendet und die JBOF in zwei Gruppen von 12 SSDs aufgeteilt. Jede Gruppe von 12 SSDs teilte sich dann 16 PCIe-Lanes. Obwohl die Anbindung der SSDs an unseren Host immer noch erhebliche Vorteile bietet, kam es dennoch zu Szenarien, in denen Swap-Laufwerke, die über das JBOF laufen, hinter den direkt an den Server angeschlossenen Laufwerken zurückblieben. Dies ist kein Fehler des JBOF. Es handelt sich lediglich um eine technische Einschränkung bzw. eine Beschränkung der Anzahl der PCIe-Lanes, mit denen der Server arbeiten kann.
Aufmerksame Leser fragen sich vielleicht, warum wir in diesem Durchlauf bei 36 SSDs aufgehört haben, anstatt auf 40 zu steigen. Das ist eine lustige Geschichte. Der adressierbare PCIe-Speicherplatz stößt bei vielen Servern an seine Grenzen. In unserem Fall übernahm bei der Anzahl der 38 Laufwerke die letzte SSD die PCIe-Adresse des USB-Chipsatzes und wir verloren die Kontrolle über den Server. Um auf Nummer sicher zu gehen, haben wir es auf 36 SSDs zurückgesetzt, damit wir weiterhin ins BIOS gehen oder uns am Server anmelden konnten. Das Überschreiten von Grenzen führt zu einigen überraschenden Entdeckungen.
Diagnostische Erkenntnisse und Lösungen
Die erste der beiden größten Herausforderungen, denen wir begegneten, war leistungsbezogener Natur. Was wir entdeckten, war Amdahls Gesetz in Aktion. Ein eigenartiges Problem trat auf, als Y-Cruncher bei großen Swap-Modus-Vorgängen auf unserem AMD Bergamo-System mit 256 Kernen zu „hängen“ schien. Dieser Stillstand, der durch einen Mangel an CPU- und Festplatten-E/A-Aktivität gekennzeichnet war, stellte herkömmliche Erwartungen an das Softwareverhalten in Frage. Dies führte zu einem tiefen Einblick in die Feinheiten des Parallelrechnens und der Hardware-Interaktionen.
Der Entdeckungsprozess ergab, dass das Programm nicht wirklich hängen blieb, sondern mit einer stark eingeschränkten Kapazität lief und Single-Threaded auf einem umfangreichen 256-Core-Setup lief. Dieses ungewöhnliche Verhalten warf Fragen über die möglichen Auswirkungen des Amdahl-Gesetzes auf, insbesondere da die damit verbundenen Vorgänge nicht rechenintensiv waren und auf einem mit 1.5 TB RAM ausgestatteten System keine nennenswerten Verzögerungen hätten verursachen dürfen.
Die Ermittlung nahm eine unerwartete Wendung, als das Problem auf einem Verbraucher-Desktop reproduziert wurde, was die schwerwiegenden Auswirkungen des Amdahl-Gesetzes selbst auf weniger umfangreiche Systeme deutlich machte. Dies führte zu einer eingehenderen Untersuchung der zugrunde liegenden Ursachen, die eine für die Zen4-Architektur spezifische CPU-Gefährdung im Zusammenhang mit Super-Alignment und deren Auswirkungen auf Speicherzugriffsmuster aufdeckte.

Bei AMD-Prozessoren wurde das Problem durch eine Schleife im Code verschärft, die aufgrund ihrer einfachen Natur viel schneller hätte ausgeführt werden müssen als beobachtet. Die Hauptursache schien die ineffiziente Handhabung des Speicheraliasings durch die Load-Store-Einheit von AMD zu sein. Die Lösung dieses komplexen Problems erforderte sowohl die Minderung der Super-Alignment-Gefahr durch Vektorisierung der Schleife mit AVX512 als auch die Bewältigung der durch das Amdahl-Gesetz verursachten Verlangsamung durch verbesserte Parallelität. Dieser umfassende Ansatz löste nicht nur das unmittelbare Problem, sondern führte auch zu erheblichen Optimierungen der Rechenprozesse von y-cruncher und schuf damit einen Präzedenzfall für die Bewältigung ähnlicher Herausforderungen in Hochleistungsrechnerumgebungen.
Das nächste Problem trat in den letzten Schritten der Berechnung auf, die unerwartet abbrachen und keine Informationen über die Ursache des Absturzes lieferten. Alexander Yee wurde Fernzugriff gewährt, und zum ersten Mal seit über einem Jahrzehnt erforderte die Vervollständigung eines Pi-Datensatzes ein direktes Eingreifen des Entwicklers.
Wir waren an diesem Diagnoseprozess nicht beteiligt, es gab jedoch einen kritischen Gleitkomma-Arithmetikfehler im AVX512-Codepfad des N63-Multiplikationsalgorithmus. Alexander konnte eine Ferndiagnose stellen, stellen Sie eine feste Binärdatei bereit und fahren Sie an einem Kontrollpunkt fort, was nach der Implementierung wichtiger Softwarekorrekturen zu einer erfolgreichen Berechnung führt.
Reflexionen und Fortschritt
Dieses Unterfangen verdeutlicht die Komplexität und Unvorhersehbarkeit des Hochleistungsrechnens. Die Lösung dieser Herausforderungen stellte einen neuen Pi-Berechnungsrekord auf und lieferte wertvolle Einblicke in Softwareentwicklungs- und Testmethoden. Die neueste y-cruncher-Version, v0.8.4, enthält Korrekturen für die identifizierten Probleme und verspricht eine verbesserte Stabilität für zukünftige Berechnungen.
Die Berechnung von Pi auf 105 Billionen Stellen war keine leichte Aufgabe. Es erforderte eine sorgfältige Planung, Optimierung und Ausführung. Durch den Einsatz einer Kombination aus Open-Source- und proprietärer Software optimierte das Team von StorageReview den algorithmischen Prozess, um die Fähigkeiten der Hardware vollständig auszunutzen, die Rechenzeit zu reduzieren und die Effizienz zu steigern.
Mit PCIe Gen4 sättigender Leseleistung und branchenführenden Kapazitäten von bis zu 61.44 TB liefern Solidigm QLC SSDs unglaubliche Ergebnisse. „Stellen Sie sich vor, was diese Laufwerke bei Hochleistungsrechnern oder KI-intensiven Anwendungen ermöglichen können“, sagte Greg Matson, Vizepräsident für strategische Planung und Marketing bei Solidigm. Wir freuen uns, dass die SSDs von Solidigm den zweiten rekordverdächtigen Versuch von Storagereview zur Berechnung von Pi unterstützen könnten. Ihre Bemühungen beweisen die wahren Fähigkeiten der Speicherlaufwerke von Solidigm und eröffnen eine Welt voller Möglichkeiten für datenintensive KI-Anwendungen.“
Fazit
Der Anstieg auf 105 Billionen Ziffern von Pi war viel komplexer als wir erwartet hatten. Wenn wir darüber nachdenken, hätten wir damit rechnen müssen, auf neue Probleme zu stoßen; Schließlich führen wir eine Berechnung durch, die noch nie zuvor durchgeführt wurde. Aber nachdem die 100-Billionen-Berechnung mit einer viel mehr „Klebeband- und Maschendraht“-Konfiguration abgeschlossen war, dachten wir, wir hätten es geschafft. Letztendlich war eine gemeinsame Anstrengung erforderlich, um dieses Gerät über die Ziellinie zu bringen.
Während wir uns mit unseren Partnern über diesen Rekordlauf freuen, müssen wir uns fragen: „Was bedeutet das überhaupt?“ Fünf weitere Billionen Ziffern von Pi werden für die Mathematik wahrscheinlich keinen großen Unterschied machen. Dennoch können wir einige Grenzen zwischen der Rechenlast und dem Bedarf an moderner zugrunde liegender Hardware zu ihrer Unterstützung ziehen. Grundsätzlich spiegelt diese Übung wider, dass die richtige Hardware den entscheidenden Unterschied macht, sei es ein Unternehmens-Rechenzentrumscluster oder eine große HPC-Installation.
Für die Pi-Berechnung waren wir durch den Speicher vollständig eingeschränkt. Schnellere CPUs helfen dabei, die Berechnungen zu beschleunigen, aber der limitierende Faktor für viele neue Weltrekorde ist die Menge an lokalem Speicher in der Box. Für diesen Lauf nutzen wir erneut die Solidigm D5-P5316 30.72 TB SSDs um uns zu helfen, etwas mehr als 1.1 PB Roh-Flash in das System zu bekommen. Diese SSDs sind der einzige Grund, warum wir die bisherigen Rekorde durchbrechen und 105 Billionen Pi-Ziffern erreichen konnten.
Dies wirft jedoch eine interessante Frage auf. Viele unserer Follower wissen, dass Solidigm das hat 61.44 TB SSDs im D5-P5336 und bis zu 30.72 TB im D5-P5430 SSDs, verfügbar in verschiedenen Formfaktoren und Kapazitäten. Wir haben die Laufwerke überprüft und viele Social-Media-Beiträge veröffentlicht, in denen diese erstaunlich dichten Laufwerke vorgestellt werden. Angesichts der Tatsache, dass 32 dieser SSDs eine Speicherkapazität von fast 2 PB erreichen, könnte man sich fragen, wie lange diese 105 Billionen Ziffern des Pi noch der größte der Welt sein werden. Wir würden gerne nachdenken, nicht sehr lange.
Größte bekannte Dezimalstelle von Pi
1432360875 9463978314 2999186657 8364664840 8558373926: Ziffern bis 105,000,000,000,000
Beteiligen Sie sich an StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed